
Google has upgraded Gemini 2.5 Flash and 2.5 Flash-Lite to offer better performance

On Sept 25, 2025 Google released preview updates to Gemini 2.5 Flash and Gemini 2.5 Flash-Lite. The previews bring faster, more efficient outputs, better instruction-following and multimodal abilities, and new -latest aliases so developers can test the newest builds easily.Now let’s take a look at what these two models specifically adjust.
Core improvements
Gemini 2.5 Flash-Lite
Better Following of Complex Instructions: Improves understanding of complex prompts and system commands.
- Instruction following & verbosity: Flash-Lite is tuned for better complex instruction following and produces more concise outputs (helps both cost and throughput).
- Multimodal & transcription/translation: Flash-Lite improves audio transcription, image understanding, and translation quality.
- Cost Optimization: Reduces output token count by 50%.
- Using model string: gemini-2.5-flash-lite-preview-09-2025.
Gemini 2.5 Flash
Flash: improved agentic/tool use (better at multi-step workflows and tool invocation), plus quality/speed refinements important for large-scale low-latency/agentic deployments.
- Multimodal I/O & token limits: Flash accepts text, code, images, audio and video as inputs in various variants; some Flash image previews support text+image outputs. Token limits for 2.5 Flash variants go up to 32,768 input and output tokens in supported previews/variants.
- “Thinking” capability: Gemini 2.5 Flash is a Flash-class model that now supports thinking (showing intermediate chain-of-thought/process information to improve reasoning and transparency).
- Agentic/tool use (Flash): Gemini 2.5 Flash improves how it uses tools for multi-step/agentic workflows (noted ~5% gain on SWE-Bench Verified vs prior release). With “thinking” enabled it’s more cost-efficient for complex tasks.
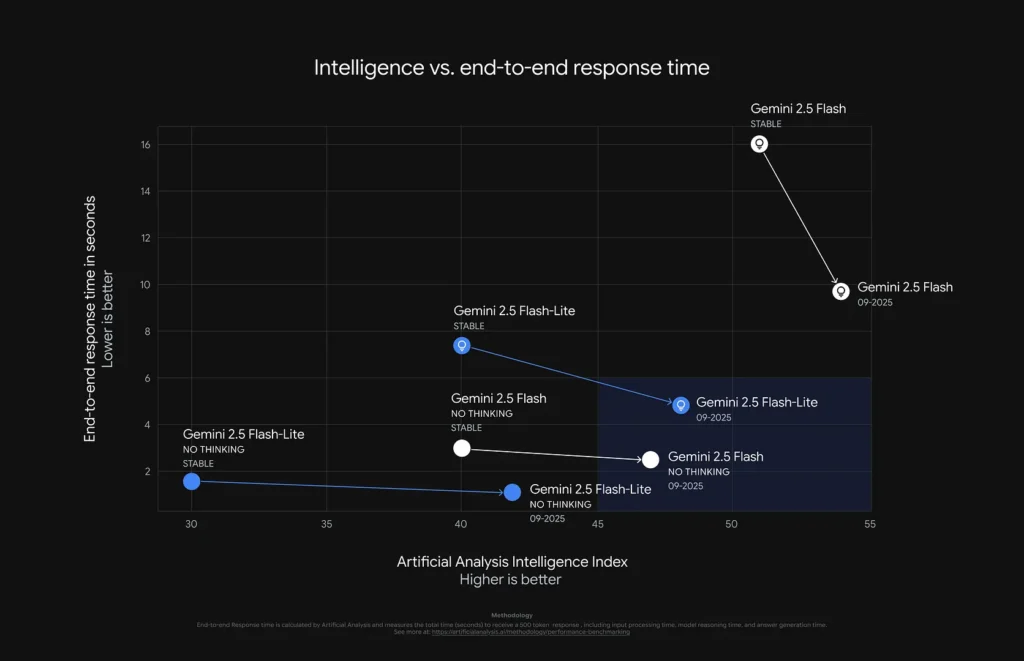
Practical implications / recommended uses
- Use Flash-Lite preview for cost-sensitive, high-throughput pipelines (batch summarization, realtime transcript processing, translation) where reduced token use and faster throughput matter.
- Use Flash preview to experiment with agentic / tool-based flows and workflows that benefit from “thinking” mode and structured outputs (agents, orchestration, multi-step assistants).
- For production stability, continue to point to the stable model IDs (e.g.,
gemini-2.5-flash,gemini-2.5-flash-lite) rather than-previewor-latestaliases until you’ve validated the new builds.
Other Updates
Introducing the -latest model alias (e.g., gemini-flash-latest and gemini-flash-lite-latest) to automatically point to the latest version, saving developers from frequent code changes.
To maintain stability, applications requiring a stable environment are recommended to continue using gemini-2.5-flash and gemini-2.5-flash-lite.
Getting Started
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
Developers can access Gemini 2.5 Flash and Gemini 2.5 Flash-Lite through CometAPI, the latest model version is always updated with the official website. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !


