
How to Access DeepSeek-V3.2-Exp API

DeepSeek released an experimental model called DeepSeek-V3.2-Exp on September 29, 2025, introducing a new sparse-attention mechanism (DeepSeek Sparse Attention, or DSA) that targets much lower inference costs for long-context workloads — and the company simultaneously cut API prices by roughly half. This guide explains what the model is, the architecture/feature highlights, how to access and use the API (with code examples), how it compares to prior DeepSeek models, and how to parse and handle its responses in production.
What is DeepSeek-V3.2-Exp?
DeepSeek-V3.2-Exp is an experimental iteration in DeepSeek’s V3 track. The release — announced in late September 2025 — is positioned as an “intermediate” step that validates architectural optimizations for extended context lengths rather than as a big leap in raw accuracy. Its headline innovation is DeepSeek Sparse Attention (DSA), an attention pattern that selectively attends to parts of a long input to reduce compute and memory costs while aiming to keep output quality comparable to V3.1-Terminus.
Why it’s important in practice:
- Cost for long-context tasks: DSA targets the quadratic cost of attention, reducing compute for very long inputs (think multi-document retrieval, long transcripts, large game worlds). API usage costs are materially lower for typical long-context use cases.
- Compatibility & accessibility: The DeepSeek API uses an OpenAI-compatible request format, so many existing OpenAI SDK workflows can be adapted quickly.
What are the main features and architecture of DeepSeek V3.2-Exp?
What is DeepSeek Sparse Attention (DSA) and how does it work?
DSA is a fine-grained sparse attention scheme designed to attend selectively over tokens rather than computing dense attention across the full context. In short:
- The model dynamically selects subsets of tokens to attend to at each layer or block, reducing FLOPs for long input lengths.
- The selection is designed to preserve the “important” context for reasoning tasks, leveraging a combination of learned selection policies and routing heuristics.
DSA as the core innovation in V3.2-Exp, intended to keep output quality close to dense-attention models while cutting inference cost, especially when context lengths grow. The release notes and model page emphasize that training configurations were aligned with V3.1-Terminus so differences in benchmark metrics reflect the sparse attention mechanism rather than a wholesale training change.
What other architecture/features ship with V3.2-Exp?
- Hybrid modes (thinking vs non-thinking): DeepSeek exposes two model IDs:
deepseek-chat(non-thinking / faster replies) anddeepseek-reasoner(thinking mode that can expose Chain-of-Thought or intermediate reasoning content). These modes let developers pick speed vs. explicit reasoning transparency. - Very large context windows: V3.x family supports very large contexts (the V3 line gives DeepSeek 128K context options in current updates), making it suitable for multi-document workflows, long logs, and knowledge-heavy agents.
- JSON output & strict function calling (Beta): The API supports a
response_formatobject that can force JSON output (and a strict function-calling beta). This helps when you need predictable machine-parseable outputs for tool integration. - Streaming & reasoning tokens: The API supports streaming responses and — for reasoning models — distinct reasoning content tokens (often exposed under
reasoning_content), which allows you to display or audit the model’s intermediate steps.
How do I access and use the DeepSeek-V3.2-Exp API via CometAPI?
DeepSeek intentionally keeps an OpenAI-style API format — so existing OpenAI SDKs or compatible tooling can be re-targeted with a different base URL. I recommend using CometAPI to access DeepSeek-V3.2-Exp because it is low-priced and a multimodal aggregation gateway. DeepSeek exposes model names that map to the V3.2-Exp behavior. Examples:
DeepSeek-V3.2-Exp-thinking — reasoning/thinking mode mapped to V3.2-Exp.
DeepSeek-V3.2-Exp-thinking — non-reasoning/chat mode mapped to V3.2-Exp.
How do I authenticate and what is the base URL?
- Get an API key from the CometAPI developer console (apply on their site).
- Base URL: (
https://api.cometapi.comorhttps://api.cometapi.com/v1for OpenAI-compatible paths). The OpenAI-compatibility means many OpenAI SDKs can be re-pointed to DeepSeek with small changes.
Which model IDs should I use?
-
DeepSeek-V3.2-Exp-thinking— thinking mode, exposes chain-of-thought/reasoning content. Both were upgraded to V3.2-Exp in the latest release notes. DeepSeek-V3.2-Exp-nothinking— non-thinking, quicker responses, typical chat/completion usage.
Example: simple curl request (chat completion)
curl -s https://api.cometapi.com/v1/chat/completions \
-H "Authorization: Bearer $cometapi_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-v3.2-exp",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize the attached meeting transcript in 3 bullet points."}
],
"max_tokens": 512,
"stream": false
}'
Example: Python (OpenAI-compatible client pattern)
This pattern works after pointing an OpenAI client to the CometAPI base URL (or using CometAPI’s SDK). The example below follows DeepSeek’s docs style:
import os
import requests
API_KEY = os.environ["CometAPI_API_KEY"]
url = "https://api.deepseek.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"model": "deepseek-v3.2-exp",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Extract action items from the following notes..."}
],
"max_tokens": 800
}
r = requests.post(url, headers=headers, json=payload)
r.raise_for_status()
print(r.json())
No special SDK is required — but if you already use OpenAI’s SDK you can often reconfigure base_url and api_key and keep the same call patterns.
Advanced usage: enabling reasoning or reasoning_content
If you need the model’s internal chain-of-thought (for auditing, distillation, or extracting intermediate steps), switch to DeepSeek-V3.2-Exp-thinking. The reasoning_content field (and related stream or tokens) is available in the response for reasoning mode; the API docs provide reasoning_content as a response field to inspect the CoT generated prior to the final answer. Note: exposing these tokens may affect billing as they are part of the model output.
Streaming and partial updates
- Use
"stream": truein requests to receive token deltas via SSE (server-sent events). stream_optionsandinclude_usagelet you tune how and when usage metadata appears during a stream (helpful for incremental UIs).
How does DeepSeek-V3.2-Exp compare with previous DeepSeek models?
V3.2-Exp vs V3.1-Terminus
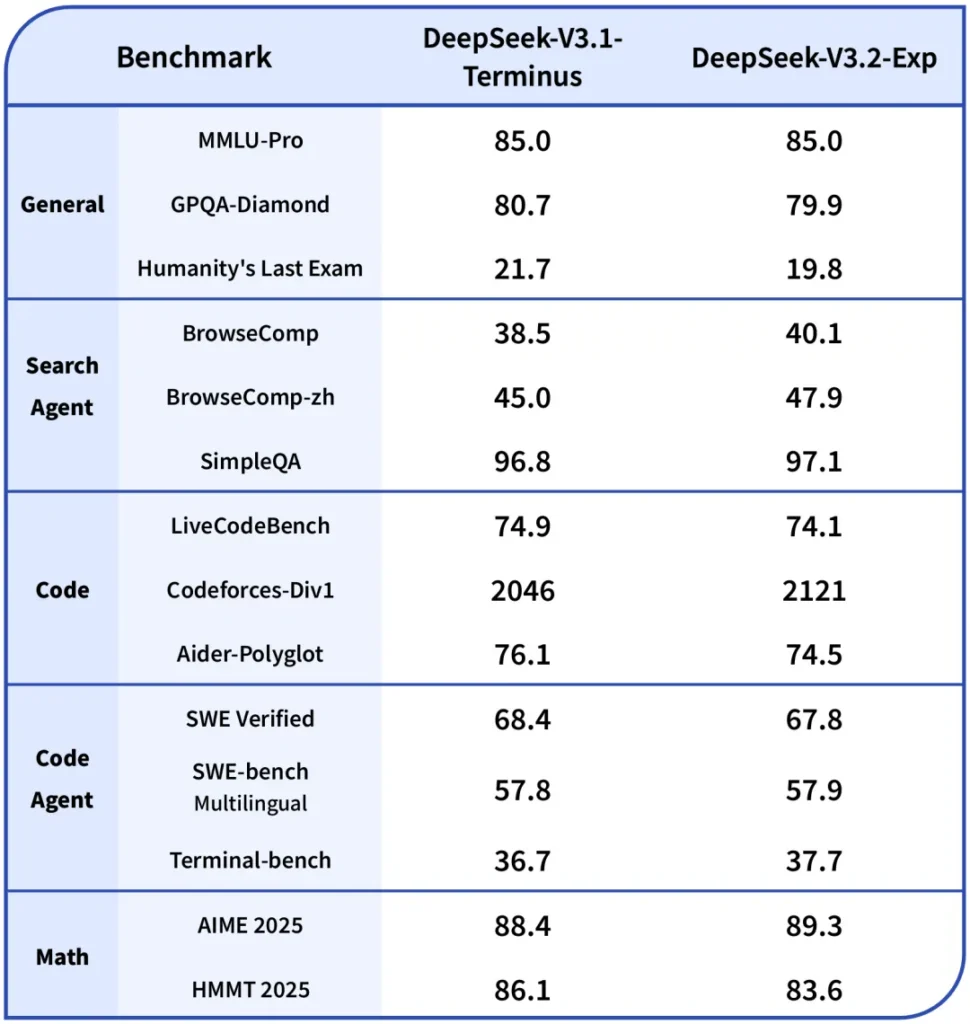
- Primary difference: V3.2-Exp introduces the sparse attention mechanism to reduce compute for long contexts while keeping the rest of the training recipe aligned to V3.1. This allowed DeepSeek to make a cleaner apples-to-apples comparison of efficiency gains. ([Hugging Face][3])
- Benchmarks: Public notes indicate V3.2-Exp performs roughly on par with V3.1 on many reasoning/coding tasks while being notably cheaper on long contexts; note that specific tasks can still have minor regressions depending on how attention sparsity interacts with the required token interactions.
V3.2-Exp vs R1 / Older releases
- R1 and V3 lines follow different design goals (R1 historically focused on different architectural tradeoffs and multimodal capacities in some branches). V3.2-Exp is a refinement in the V3 family focused on long contexts and throughput. If your workload is heavy on single-turn raw accuracy benchmarks, the differences may be modest; if you are operating on multi-document pipelines, V3.2-Exp’s cost profile is likely more attractive.
Where to Access Claude Sonnet 4.5
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
Developers can access DeepSeek V3.2 Exp through CometAPI, the latest model version is always updated with the official website. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
Conclusion
DeepSeek-V3.2-Exp is a pragmatic experimental release aimed at making long-context work cheaper and more feasible while preserving V3-class output quality. For teams dealing with long documents, transcripts, or multi-document reasoning, it’s worth piloting: the API follows an OpenAI-style interface making integration straightforward, it highlights both the DSA mechanism and meaningful price reductions that change the economic calculus of building at scale. As with any experimental model, comprehensive evaluation, instrumentation and staged rollout are essential.


