
ByteDance Releases Seed3D 1.0 —What will it bring to 3D asset generation?

ByteDance’s research arm Seed has launched Seed3D 1.0, a single-image → high-fidelity 3D foundation model that produces simulation-ready meshes, PBR materials, and aligned textures — assets designed to plug directly into physics engines and robotics simulators. The release aims to close a painful gap: scalable content generation (diverse visual content) versus physics fidelity required by embodied AI and simulator training.
What is ByteDance Seed3D 1.0?
Seed3D 1.0 is a 3D foundation model built to convert a single RGB image of an object or environment into a simulation-ready 3D asset bundle — typically an explicit, watertight mesh, associated UV-mapped texture maps, and physically-based rendering (PBR) material parameters. The model is designed not only to produce visually faithful geometry and textures, but also to emit assets that need minimal post-processing before being used in simulators such as Isaac Sim, Unity or Unreal Engine for robotics, training, or virtual world generation.
Key high-level design goals:
- Single-image input: remove the need for multi-view capture or scanning hardware.
- Simulation readiness: ensure topology, scale, and PBR materials are suitable for physical simulation.
- Scene scalability: allow generated objects to be assembled into coherent scenes automatically.
- Integration: minimal adaptation to common physics engines and runtime pipelines.
What features does Seed3D 1.0 provide?
High-fidelity geometry (watertight meshes)
Seed3D produces closed, manifold geometry designed for accurate collision handling and reliable contact physics. The geometry component uses a VAE + diffusion-transformer hybrid to produce level-of-detail-preserving meshes that retain fine structural details such as thin protrusions, holes, and text. The mesh extraction pipeline uses a dual marching cubes / hierarchical iso-surface strategy to extract high-quality surfaces efficiently. ([arXiv][1])
Photorealistic textures and PBR materials
The texture pipeline yields multi-view consistent albedo maps and full PBR textures (albedo, metallic, roughness), and can produce texture outputs up to 4K resolution. These maps are designed so lighting behaves physically plausibly in rendering engines. A UV inpainting module completes occluded regions and ensures spatial coherence across the UV atlas.
Simulation and pipeline readiness
Outputs are exportable to common formats (OBJ/GLB). Generated assets are intentionally simulation-ready: they integrate into physics simulators where collision meshes and friction/rigidity parameters can be auto-derived or adjusted, enabling immediate use in robotics or game engines. Seed3D demonstrates workflows that place generated assets in Isaac Sim for manipulation experiments.
Scene generation and factorized assembly
Beyond single objects, Seed3D uses a factorized scene generation approach where vision-language models infer layout maps (positions, scales, orientations) and Seed3D synthesizes and places objects accordingly, enabling coherent scene composition for interiors and urban layouts.
Performance evaluation result
Geometry Generation
On geometry benchmarks, Seed3D 1.0’s 1.5-billion-parameter geometry model (Seed3D-DiT + VAE) achieves better structural accuracy and finer details compared to several baselines (TRELLIS, TripoSG, Step1X-3D, Direct3D-S2 and large models such as Hunyuan3D-2.1). Seed3D’s architecture—latent-space diffusion combined with careful SDF decoding and hierarchical mesh extraction—yields meshes with fewer artifacts and better preservation of high-frequency geometry (text, small protrusions).
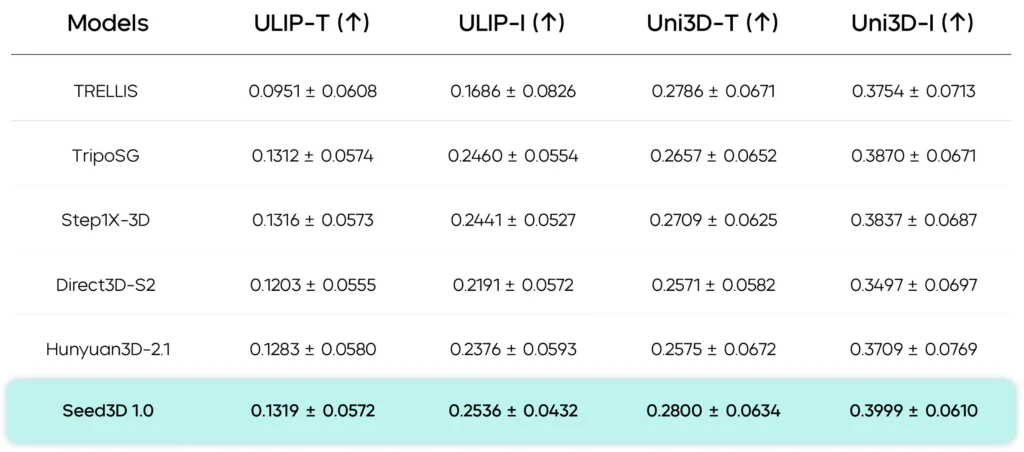
Texture Generation
For texture and material estimates, Seed3D reports substantial gains in alignment with reference images and in material realism. The Seed3D-PBR decomposition and Seed3D-UV inpainting together produce UV atlases that preserve high-frequency texture details and provide coherent PBR maps (albedo, metallic, roughness) suitable for physical rendering.
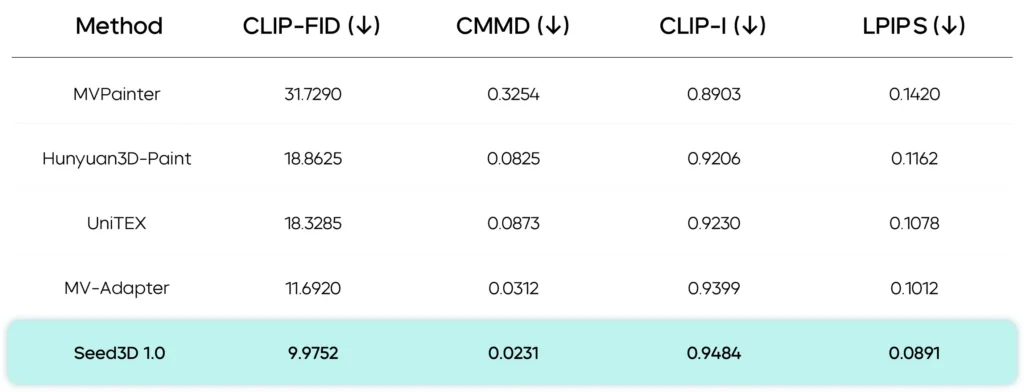
Human Evaluation (User Study)
The paper reports a user study with 14 human evaluators over a 43-image test set. Evaluators compared multiple methods across dimensions such as visual clarity, faithful restoration, geometry accuracy, perspective & structure, material & texture realism, and detail richness. Seed3D 1.0 received consistently higher subjective ratings across these categories, with the most pronounced advantages in geometry and material quality. The human study corroborates the quantitative benchmarks, showing that perceived realism and simulation suitability improved relative to baselines.
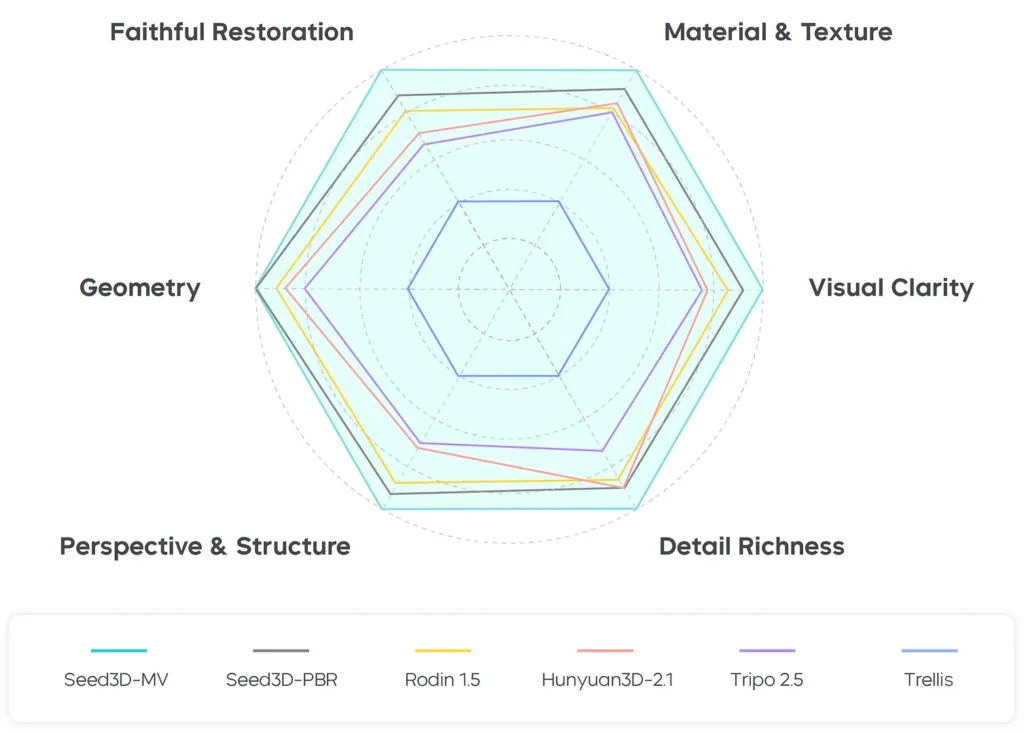
How does Seed3D 1.0 work (architecture and pipeline)?
Seed3D 1.0 is framed as a multi-component system combining learned latent geometry representations, transformer-based denoising in latent space, and multi-view & texture completion modules. The design is intentionally modular so each component can be optimized and upgraded independently.
Major components
Seed3D-VAE (geometry latent encoder/decoder): Learns a compact latent representation for 3D geometry (e.g., TSDF/mesh latent). The VAE is trained to reconstruct high-resolution, watertight geometry from compressed latent codes. This provides an efficient bottleneck for the generation stage.
Seed3D-DiT (diffusion-transformer for geometry): A rectified flow / denoising transformer (DiT-like) that operates in the learned geometry latent space. Conditioned on a reference image embedding, it iteratively denoises latent tokens into a geometry latent that the VAE decodes into an explicit mesh.
Seed3D-MV (multi-view synthesis) and Seed3D-UV (texture completion): After initial geometry is produced, the system synthesizes multiple views to reduce occlusion ambiguity and then completes UV maps via an inpainting/UV enhancement module to produce full, coherent textures.
Seed3D-PBR (material decomposition): Decomposes generated textures into PBR maps (metalness, roughness, normal maps, etc.) so that physically plausible shading and contact responses are preserved in simulation.
Vision-Language Model for scene factorization: For scene generation the pipeline uses VLMs to detect objects, predict spatial relationships, and produce layout maps (position, scale, orientation). Individual objects are generated and then assembled into a scene according to the layout map. ([arXiv][1])
High-level inference flow
- Input: single RGB image → image encoder extracts visual embedding.
- Geometry generation: Seed3D-DiT conditioned on the embedding denoises geometry latents → Seed3D-VAE decodes mesh (watertight).
- Multi-view synthesis: generate synthetic views from the mesh + render pipeline for texture completion.
- UV & texture: Seed3D-UV inpaints occlusions and produces full UV maps → Seed3D-PBR decomposes textures into material maps.
- Export: produce .obj/.gltf with textures and material maps, ready for physics engines (collision meshes, scale estimation by VLM).
Scene Generation
Seed3D not only generates individual objects, but also automatically generates complete scenes.
Generation Process:
- Input: An image containing multiple objects;
- The VLM model identifies the objects and spatial relationships in the image;
- Seed3D generates the geometry and texture for each object;
- Finally, the spatial layout is combined to form a complete 3D scene.
What are the limitations and open challenges?
Seed3D 1.0 is a major step, but several limitations remain — both intrinsic to single-image generation and specific to simulation contexts:
- Single-view ambiguity: inferring occluded geometry and exact topology from one view is fundamentally ill-posed; priors and learned statistics help, but errors remain for heavily occluded regions.
- Physical correctness at scale: while assets are “simulation-ready” by many practical measures, fine-grained mass/inertia estimation and joint dynamics for complex articulated systems still require domain-specific tuning.
- Rare materials & microstructure: highly specular, translucent, or anisotropic materials (e.g., brushed metals, fabrics with subsurface scattering) are harder to reproduce accurately from a single image.
- Data biases: training data sources influence what the model captures well — uncommon objects or culturally specific artifacts may be reproduced poorly.
- Intellectual property & ethics: as with all generative systems, creators and organizations must consider IP and provenance when converting copyrighted images to 3D assets.
Application Scenario
Seed3D is explicitly positioned for embodied AI and simulation use cases, but the implications span multiple industries:
- Robotics and RL training: rapid content generation for manipulation benchmarks, training curricula, and domain-randomized datasets for sim-to-real transfer. The assets’ physics readiness reduces pre-processing friction.
- Game development and XR: accelerated asset creation for prototypes, background props, or entire scenes; the PBR workflows and 4K textures are particularly useful for high-fidelity experiences.
- Virtual production and visualization: quick turn-around generation of props and environment elements for concepting or previsualization.
- Content creation pipelines: designers can iterate from 2D references (photos, art) to 3D prototypes much faster, enabling hybrid human+AI workflows where artists fine-tune outputs. ([arXiv][1])
- Research: large-scale generation of diverse 3D training data for vision-language-action models and other multimodal research. The paper explicitly frames Seed3D as a tool for advancing world simulator scale and embodied intelligence research.
Seed3D can convert a single photo into a detailed 3D object suitable for simulation and interactive use, which broadens access to high-quality 3D content creation.
Conclusion
ByteDance’s Seed3D 1.0 represents a significant step toward scalable, simulation-grade 3D generation from simple 2D inputs. By combining a focused geometry pipeline (VAE + DiT), robust texture/PBR estimation, and UV completion, the system produces assets that are both photorealistic and immediately useful in physics simulators — a combination that addresses a persistent bottleneck for embodied AI research and many applied pipelines. The model’s reported SOTA performance (geometry & texture) and positive human evaluation results make it a strong entrant in the rapidly evolving 3D generative landscape.
Getting Started
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
Developers can access 3D model and other ByteDance’s model such as Seedream 4.0 API through CometAPI, the latest model version is always updated with the official website. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!