
MiniMax M2: Why is it the king of cost-effectiveness for LLM models?

MiniMax, the Chinese AI startup, has publicly released the weights and tooling for MiniMax M2, its newest large language model designed specifically for coding workflows and agentic tool use. The company says the M2 is built as an efficient mixture-of-experts (MoE) design that delivers top-tier coding and agent performance at a fraction of the cost of comparable proprietary models, I will explain why MiniMax M2 is the king of cost-effectiveness from the features, benchmark performance, architecture and cost.
What is MiniMax M2?
MiniMax M2 is MiniMax’s latest open-source large language model intended primarily for coding, multi-step agent workflows, and tool calling. The model uses a Mixture-of-Experts architecture: it has a very large total parameter footprint, but only a modest number of parameters are activated per token during inference — a design that reduces inference cost and latency while preserving strong reasoning and coding ability.
Key headline numbers (as released)
- Total parameter budget: ~230 billion (total).
- Activated / effective parameters per token: ~10 billion (activated).
- Context window (reported): up to ~204,800 tokens
- License: MIT (open source weights).
- Cost and speed claims: Its cost per token is only 8% of Anthropic Claude Sonnet and its speed is about twice as fast.
What are MiniMax M2’s headline features?
Agentic / tool-oriented behavior
MiniMax M2 ships with explicit support for tool calling, structured prompts, and interleaved reasoning → action → verification patterns, making it straightforward to build autonomous agents that call external APIs, run code, or operate terminals. Several integration recipes target agent runtimes and vLLM/accelerate stacks.
Optimized for coding & multi-file tasks
Benchmarks reported on Hugging Face and third-party analyses show strong performance on developer-oriented test suites (unit tests, terminal simulation, multi-file synthesis), where M2 scores highly relative to other open and closed models. That aligns with MiniMax’s stated product emphasis on developer tooling and coding assistants.
Sparse Mixture-of-Experts (MoE) efficiency
Rather than a single dense parameter set, MiniMax M2 uses a sparse Mixture-of-Experts routing strategy so only a subset of the full parameter bank is activated per token. This yields a large total parameter count but a much smaller activated parameter footprint during inference — improving cost and latency efficiency for many workloads.
How does MiniMax M2 work internally?
High-level architecture
According to MiniMax’s technical disclosures and independent reporting, MiniMax M2 is implemented as a sparse MoE transformer with the following, widely reported, design decisions:
- A very large total parameter count (reported in press coverage as on the order of hundreds of billions), with only a subset of experts activated per token (the press mentions examples like 230B total with ~10B active per inference in early reports). This is the classic MoE trade-off: scale capacity without linear inference cost.
- Routing: top-k expert routing (Top-2 or Top-K) that sends each token to a small number of experts so the compute load is sparse and predictable.
- Attention & position encoding: hybrid attention patterns (e.g., mixes of dense and efficient attention kernels) and modern rotary or RoPE style positional encodings are mentioned in community model documentation and the Hugging Face model card. These choices improve long-context behavior important for multi-file coding and agent memory.
Why sparse MoE helps agentic workflows
Agentic workflows typically require a blend of reasoning, code generation, tool orchestration, and stateful planning. With MoE, MiniMax M2 can afford many specialized expert submodules (e.g., experts better at code, experts tuned for tool formatting, experts for factual retrieval) while activating only the experts needed for each token. That specialization improves both throughput and correctness for compound tasks while lowering inference cost compared to a uniformly large dense model.
Training & fine-tuning notes (what MiniMax published)
MiniMax cites a mixture of code, instruction-tuning, web text, and agent-loop datasets for M2’s instruction and tool fluency.
Why MoE for agents and code?
MoE lets you grow model capacity (for better reasoning and multimodal capability) without linearly increasing the inference FLOPs for each token. For agents and coding assistants — which frequently make many short, interactive queries and call external tools — MoE’s selective activation keeps latency and cloud bill reasonable while retaining the capacity benefits of a very large model.
Benchmark Performance
According to independent evaluations by Artificial Analysis, a third-party generative AI model benchmark and research organization, M2 currently ranks first among all open-source weighted systems globally in the “Intelligence Index,” a comprehensive measure of reasoning, coding, and task execution performance.
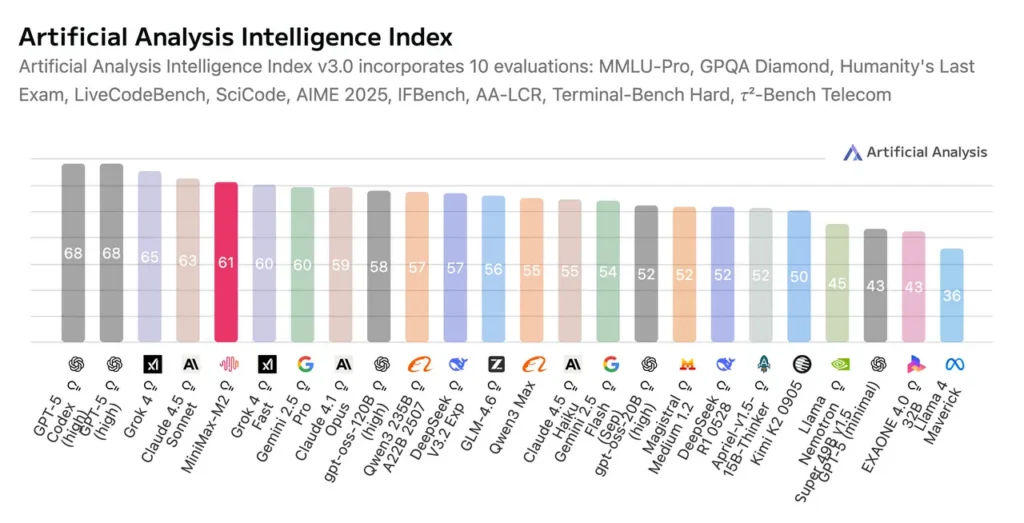
MiniMax’s model card shows comparative results across coding / agentic benchmark suites (SWE-bench, Terminal-Bench, BrowseComp, GAIA, τ²-Bench, etc.). In those published tables M2 shows strong scores on coding and multi-step tool tasks, and MiniMax highlights competitive intelligence/agentic composite scores relative to other open models.
These scores place it at or near the level of top proprietary systems such as GPT-5 (thinking) and Claude Sonnet 4.5, making MiniMax-M2 the highest-performing open model to date on real-world agent and tool-invocation tasks.
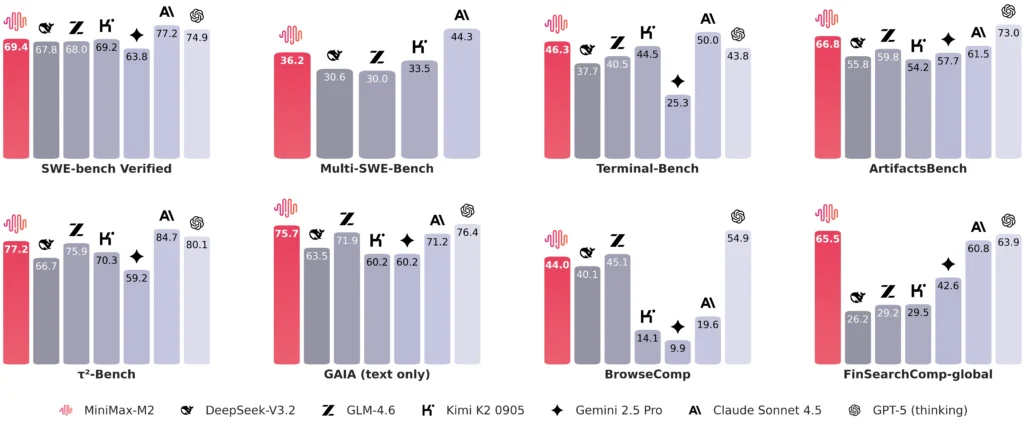
MiniMax-M2 achieves top or near-top performance in many categories:
- SWE-bench Verified: 69.4 — close to GPT-5’s 74.9
- ArtifactsBench: 66.8 — above Claude Sonnet 4.5 and DeepSeek-V3.2
- τ²-Bench: 77.2 — approaching GPT-5’s 80.1
- GAIA (text only): 75.7 — surpassing DeepSeek-V3.2
- BrowseComp: 44.0 — notably stronger than other open models
- FinSearchComp-global: 65.5 — best among tested open-weight systems
Cost and Pricng
MiniMax publicly lists a very competitive API price of $0.30 per 1,000,000 input tokens and $1.20 per 1,000,000 output tokens. The company also reports an inference throughput (TPS) figure on its hosted endpoint of ~100 tokens/sec (and states they are improving it). CometAPI offers 20% off official price for accessing MiniMax M2 API.
Quick interpretation
- Input tokens are extremely cheap per-token relative to many commercial models; output tokens are more expensive but still low compared to many closed alternatives.
- Throughput (tokens/sec) and latency will depend heavily on deployment choices (hosted vs self-hosted, GPU type, batching, quantization). Use the published TPS as a baseline for hosted API planning only.
What are the best use cases for MiniMax M2?
1) End-to-end developer assistants (code authoring → run → fix → verify)
MiniMax M2 is purpose-built for multi-file edits, compile/run/fix loops, and CI/IDE automation—where the model must remember large codebases or long terminal transcripts and orchestrate tool calls (build, test, lint, git). Benchmarks and early community tests put it high among coding/agentic suites.
Typical flow: fetch repo → run tests inside sandbox → parse failures → produce patch → run tests again → open PR if green.
2) Multi-step agents and RPA (tools + memory)
Agentic applications that need planning, tool-invocation, and recovery (web browsing, terminal, database, custom APIs) benefit from the long context and structured function/tool calling. M2’s long-context ability lets you keep plans, logs, and state in memory without aggressive external retrieval.
3) Long-document reasoning & customer support (playbooks, manuals)
Because M2 supports very large contexts, you can feed whole product manuals, playbooks, or long user conversation histories without heavy chunking — ideal for context-rich support automation, policy reasoning, and compliance checks.
4) Research & experimentation (open weights, permissive use)
With open weights on Hugging Face you can run experiments (custom finetuning, MoE research, new routing strategies or safety mechanisms) locally or on private clusters. That makes M2 attractive to labs and teams wanting full control.
Practical recommendations for engineers and product teams
If you want fast experimentation: Use the MiniMax cloud API (Anthropic/OpenAI compatible). It removes local infra friction and gives you immediate access to tool calling and long-context features.
If you need control and cost optimization: Download the weights from Hugging Face and serve with vLLM or SGLang. Expect to invest in engineering for MoE sharding and careful inference tuning. Test memory, cost, and latency against your real workload (multi-turn agents and multi-file code tasks).
Testing and safety: Run your own red-team tests, safety filters, and tool validation. Open weights accelerate research but also mean bad actors can iterate quickly; build detectors and human-in-the-loop checks where necessary.
Conclusion
MiniMax M2 represents a notable moment in the open-source LLM ecosystem: a large, agent-centric, permissively licensed model that prioritizes coding and tool use while aiming to keep inference cost practicable through sparse MoE routing. For organizations building developer tools, autonomous agents, or research teams needing access to weights for fine-tuning, M2 offers a compelling, immediately usable option — provided the team is prepared to manage MoE deployment complexity.
How to Access MiniMax M2 API
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
Developers can access MiniMax M2 through CometAPI, the latest model version is always updated with the official website. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!