
How to integrate AnythingLLM with CometAPI?

In 2025–2026 the AI tooling landscape continued to consolidate: gateway APIs (like CometAPI) expanded to provide OpenAI-style access to hundreds of models, while end-user LLM apps (like AnythingLLM) continued improving their “Generic OpenAI” provider to let desktop and local-first apps call any OpenAI-compatible endpoint. That makes it straightforward today to route AnythingLLM traffic through CometAPI and get the benefits of model choice, cost routing, and unified billing — while still using AnythingLLM’s local UI and RAG/agent features.
What is AnythingLLM and why would you want to connect it to CometAPI?
What is AnythingLLM?
AnythingLLM is an open-source, all-in-one AI application and local/cloud client for building chat assistants, retrieval-augmented generation (RAG) workflows, and LLM-driven agents. It provides a slick UI, a developer API, workspace/agent features, and support for local and cloud LLMs — designed to be private by default and extensible via plugins. AnythingLLM exposes a Generic OpenAI provider that lets it talk to OpenAI-compatible LLM APIs.
What is CometAPI?
CometAPI is a commercial API-aggregation platform that exposes 500+ AI models through one OpenAI-style REST interface and unified billing. In practice it lets you call models from multiple vendors (OpenAI, Anthropic, Google/Gemini variants, image/audio models, etc.) via the same https://api.cometapi.com/v1 endpoints and a single API key (format sk-xxxxx). CometAPI supports standard OpenAI-style endpoints such as /v1/chat/completions, /v1/embeddings, etc., which makes it easy to adapt tools that already support OpenAI-compatible APIs.
Why integrate AnythingLLM with CometAPI?
Three practical reasons:
- Model choice & vendor flexibility: AnythingLLM can use “any OpenAI-compatible” LLM via its Generic OpenAI wrapper. Pointing that wrapper at CometAPI gives immediate access to hundreds of models without changing AnythingLLM’s UI or flows.
- Cost/ops optimization: Using CometAPI lets you switch models (or downshift to cheaper ones) centrally for cost control, and keep unified billing instead of juggling multiple provider keys.
- Faster experimentation: You can A/B different models (e.g.,
gpt-4o,gpt-4.5, Claude variants, or open-source multi-modal models) via the same AnythingLLM UI — useful for agents, RAG responses, summarization, and multimodal tasks.
Environment and conditions must you prepare before integrating
System & software requirements (high level)
- Desktop or server running AnythingLLM (Windows, macOS, Linux) — desktop install or self-hosted instance. Confirm you’re on a recent build that exposes the LLM Preferences / AI Providers settings.
- CometAPI account and an API key (the
sk-xxxxxstyle secret). You’ll use this secret in AnythingLLM’s Generic OpenAI provider. - Network connectivity from your machine to
https://api.cometapi.com(no firewall blocking outbound HTTPS). - Optional but recommended: a modern Python or Node environment for testing (Python 3.10+ or Node 18+), curl, and an HTTP client (Postman / HTTPie) to sanity-check CometAPI before hooking it into AnythingLLM.
AnythingLLM-specific conditions
The Generic OpenAI LLM provider is the recommended route for endpoints that mimic OpenAI’s API surface. AnythingLLM’s docs warn that this provider is developer-focused and you should understand the inputs you supply. If you use streaming or your endpoint does not support streaming, AnythingLLM includes a setting to disable streaming for Generic OpenAI.
Security & operational checklist
- Treat the CometAPI key like any other secret — don’t commit it to repos; store it in OS keychains or environment variables where possible.
- If you plan to use sensitive documents in RAG, ensure endpoint privacy guarantees meet your compliance needs (check CometAPI’s docs/terms).
- Decide on max tokens and context window limits to prevent runaway bills.
How do you configure AnythingLLM to use CometAPI (step-by-step)?
Below is a concrete step sequence — followed by example environment variables and code snippets for testing the connection before you save the settings in the AnythingLLM UI.
Step 1 — Get your CometAPI key
- Register or sign in at CometAPI.
- Navigate to “API Keys” and generate a key — you’ll get a string that looks like
sk-xxxxx. Keep it secret.
Step 2 — Verify CometAPI works with a quick request
Use curl or Python to call a simple chat completion endpoint to confirm connectivity.
Curl example
curl -X POST "https://api.cometapi.com/v1/chat/completions" \
-H "Authorization: Bearer sk-xxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o",
"messages": [{"role":"user","content":"Hello from CometAPI test"}],
"max_tokens": 50
}'
If this returns a 200 and a JSON response with a choices array, your key and network are working. (CometAPI’s docs show the OpenAI-style surface and endpoints).
Python example (requests)
import requests
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": "Bearer sk-xxxxx", "Content-Type": "application/json"}
payload = {
"model": "gpt-4o",
"messages": [{"role":"user","content":"Test from Python via CometAPI"}],
"max_tokens": 64
}
r = requests.post(url, json=payload, headers=headers, timeout=15)
print(r.status_code, r.json())
Step 3 — Configure AnythingLLM (UI)
Open AnythingLLM → Settings → AI Providers → LLM Preferences (or similar path in your version). Use the Generic OpenAI provider and fill fields as follows:
API Configuration (example)
• Enter AnythingLLM settings menu, locate LLM Preferences under AI Providers.
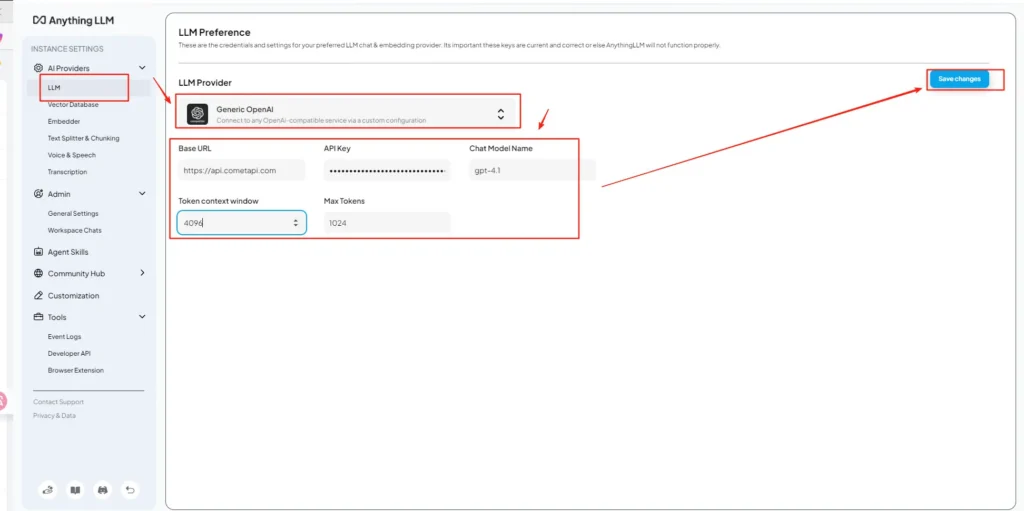
• Select Generic OpenAI as the model provider, enterhttps://api.cometapi.com/v1in the URL field.
• Paste thesk-xxxxxfrom CometAPI in the API key input box. Fill in Token context window and Max Tokens according to the actual model. You can also customize model names on this page, such as adding thegpt-4omodel.
This aligns with AnythingLLM’s “Generic OpenAI” guidance (developer wrapper) and CometAPI’s OpenAI-compatible base URL approach.
Step 4 — Set model names & token limits
On the same settings screen, add or customize model names exactly as CometAPI publishes them (e.g., gpt-4o, minimax-m2, kimi-k2-thinking) so the AnythingLLM UI can present those models to users. CometAPI publishes model strings for each vendor.
Step 5 — Test in AnythingLLM
Start a new chat or use an existing workspace, select the Generic OpenAI provider (if you have multiple providers), choose one of the CometAPI model names you added, and run a simple prompt. If you get coherent completions, you’re integrated.
How AnythingLLM uses those settings internally
AnythingLLM’s Generic OpenAI wrapper constructs OpenAI-style requests (/v1/chat/completions, /v1/embeddings), so once you point the base URL and supply the CometAPI key, AnythingLLM will route chats, agent calls, and embedding requests through CometAPI transparently. If you use AnythingLLM agents (the @agent flows), they will inherit the same provider.
What are best practices and possible pitfalls?
Best practices
- Use model-appropriate context settings: Match AnythingLLM’s Token Context Window and Max Tokens to the model you pick on CometAPI. Mismatch leads to unexpected truncation or failed calls.
- Secure your API keys: Store CometAPI keys in environment variables and/or Kubernetes/secret manager; never check them into git. AnythingLLM will store keys in its local settings if you enter them in the UI — treat the host storage as sensitive.
- Start with cheaper / smaller models for experiment flows: Use CometAPI to try lower-cost models for development, reserve premium models for production. CometAPI explicitly advertises cost switching and unified billing.
- Monitor usage & set alerts: CometAPI provides usage dashboards — set budgets/alerts to avoid surprise bills.
- Test agents and tools in isolation: AnythingLLM agents can trigger actions; test them with safe prompts and on staging instances first.
Common pitfalls
- UI vs
.envconflicts: When self-hosting, UI settings can overwrite.envchanges (and vice versa). Check the generated/app/server/.envif things revert after restart. Community issues reportLLM_PROVIDERresets. - Model name mismatches: Using a model name not available on CometAPI will cause a 400/404 from the gateway. Always confirm available models on the CometAPI model list.
- Token limits & streaming: If you need streaming responses, verify the CometAPI model supports streaming (and AnythingLLM’s UI version supports it). Some providers differ in streaming semantics.
What real-world use cases does this integration unlock?
Retrieval-Augmented Generation (RAG)
Use AnythingLLM’s document loaders + vector DB with CometAPI LLMs to generate context-aware answers. You can experiment with cheap embedding + expensive chat models, or keep everything on CometAPI for unified billing. AnythingLLM’s RAG flows are a primary built-in feature.
Agent automation
AnythingLLM supports @agent workflows (browse pages, call tools, run automations). Routing agents’ LLM calls through CometAPI gives you choice of models for control/interpretation steps without modifying agent code.
Multi-model A/B testing and cost optimization
Switch models per workspace or feature (e.g., gpt-4o for production answers, gpt-4o-mini for dev). CometAPI makes model swaps trivial and centralizes costs.
Multimodal pipelines
CometAPI provides image, audio, and specialized models. AnythingLLM’s multi-modal support (via providers) plus CometAPI’s models enables image captioning, multimodal summarization, or audio transcription flows through the same interface.
Conclusion
CometAPI continues to position itself as a multi-model gateway (500+ models, OpenAI-style API) — which makes it a natural partner for apps like AnythingLLM that already support a Generic OpenAI provider. Likewise, AnythingLLM’s Generic provider and recent configuration options make it straightforward to connect to such gateways. This convergence simplifies experimentation and production migration in late-2025.
How to get started with Comet API
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
To begin, explore the model capabilities of CometAPI in the Playground and consult the Continue API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!


