

Alibaba’s Qwen team has released Qwen3-Max-Preview (Instruct) — the company’s largest model to date, with more than 1 trillion parameters — and made it available immediately through Qwen Chat, Alibaba Cloud Model Studio (API), and third-party marketplaces such as CometAPI. The preview targets reasoning, coding, and long-document workflows by combining extreme scale with a very large context window and context-caching to keep latency low for long sessions.
Key technical highlights
- Massive parameter count (trillion+): The move to a trillion+ parameter model is designed to increase capacity for complex pattern learning (multi-step reasoning, code synthesis, deep document understanding). Early benchmarks released by Qwen indicate improved results on reasoning, coding and benchmark suites vs Qwen’s prior top models.
- Ultra-long context & caching: The 262k token window lets teams feed entire long reports, multi-file codebases, or long chat histories in a single pass. Context caching support reduces repeated compute for recurring context and can cut latency and cost for extended sessions.
- Multilingual + coding prowess: The Qwen3 family emphasizes bilingual (Chinese/English) and broad multilingual support, plus stronger coding and structured output handling — useful for code assistants, automated report generation, and large-scale text analytics.
- Designed for speed and quality. Preview users describe “blazing” response speed and improved instruction-following and reasoning compared with prior Qwen3 variants. Alibaba positions the model as a high-throughput flagship for production-grade, agentic, and developer scenarios.
Availability and Access
Alibaba Cloud charges tiered, token-based prices for Qwen3-Max-Preview (separate input & output rates). Billing is per-million tokens and applied to the actual tokens consumed after any free quota.
Alibaba’s published preview pricing (USD) is tiered by request input token volume (the same tiers determine which unit rates apply):
- 0–32K input tokens: $0.861 / 1M input tokens and $3.441 / 1M output tokens.
- 32K–128K input tokens: $1.434 / 1M input tokens and $5.735 / 1M output tokens.
- 128K–252K input tokens: $2.151 / 1M input tokens and $8.602 / 1M output tokens.
CometAPI provides an official 20% discount to help users call API, details refer to Qwen3-Max-Preview:
| Input Tokens | $0.24 |
| Output Tokens | $2.42 |
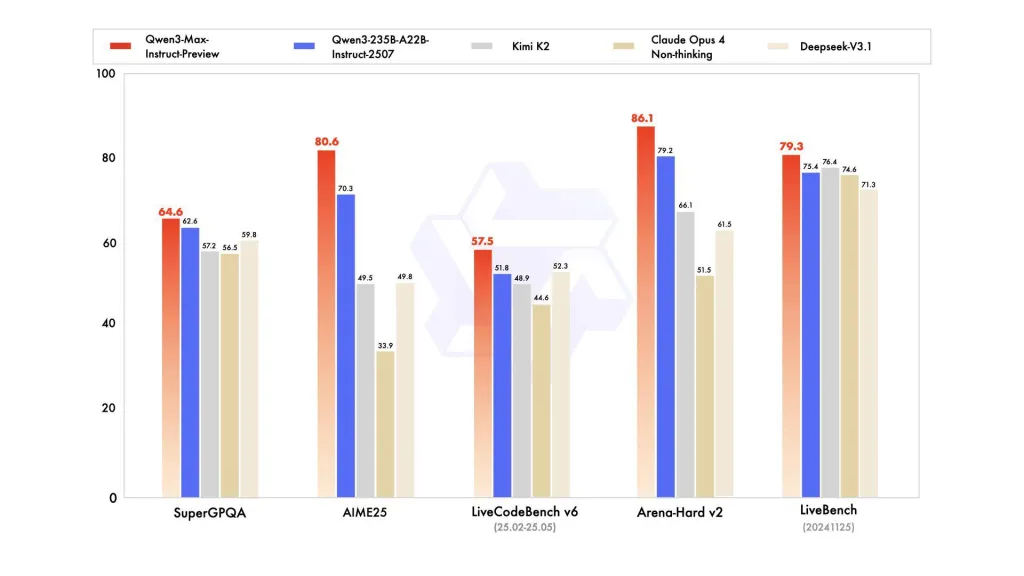
Qwen3-Max extends the Qwen3 family (which has used hybrid designs such as Mixture-of-Experts variants and multiple active-parameter tiers in previous builds). Alibaba’s prior Qwen3 releases focused on both “thinking” (step-by-step reasoning) and “instruct” modes; Qwen3-Max is positioned as the new top-end instruct variant in that line,demonstrating that it surpasses the company’s previous best-performing product, Qwen3-235B-A22B-2507, showing that the 1T parameter model leads across a range of tests.
On SuperGPQA, AIME25, LiveCodeBench v6, Arena-Hard v2, and LiveBench (20241125), Qwen3-Max-Preview consistently ranks ahead of Claude Opus 4, Kimi K2, and Deepseek-V3.1.
How to access and use Qwen3-Max (practical guide)
1) Try it in the browser (Qwen Chat)
Visit Qwen Chat (official Qwen web/chat interface) and select the Qwen3-Max-Preview (Instruct) model if shown in the model picker. This is the fastest way to evaluate conversational and instruction tasks visually.
2) Access via Alibaba Cloud (Model Studio / Cloud API)
- Sign in to Alibaba Cloud → Model Studio / Model Serving. Create an inference instance or select the hosted model endpoint for qwen3-max-preview (or the labeled preview version).
- Authenticate using your Alibaba Cloud Access Key / RAM roles and call the inference endpoint with a POST request containing your prompt and any generation parameters (temperature, max tokens, etc.).
3) Use through third-party hosts / aggregators
According to coverage, the preview is reachable via CometAPI and other API aggregators that let developers call multiple hosted models with a single API key. This can simplify testing across providers but verify latency, regional availability and data-handling policies for each host.
Getting Started
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
Conclusion
Qwen3-Max-Preview places Alibaba squarely among organizations shipping trillion-scale models to customers. The combination of extreme context length and an OpenAI-compatible API lowers the integration barrier for enterprises that need long-document reasoning, code automation, or agent orchestration. Cost and preview stability are the principal adoption considerations: organizations will want to pilot with caching, streaming, and batched calls to manage both latency and pricing.