

Anthropic’s new Claude 4 family – Claude Opus 4 and Claude Sonnet 4 – were announced in May 2025 as next-generation AI assistants optimized for advanced reasoning and coding. Opus 4 is described as Anthropic’s “most powerful model yet”, excelling at complex, multi-step coding and reasoning tasks. Sonnet 4 is a high-performance upgrade to the prior Sonnet 3.7, offering strong general reasoning, precise instruction-following, and competitive coding ability.
Below we compare these models across key technical dimensions important to developers: reasoning and coding performance, latency and efficiency, code generation quality, transparency, tool-use, integrations, cost/performance, safety, and deployment use cases. The analysis draws on Anthropic’s announcements and documentation, independent benchmarks, and industry reports to give a comprehensive, up-to-date view.
What are Claude Opus 4 and Claude Sonnet 4?
Claude Opus 4 and Claude Sonnet 4 are the newest members of Anthropic’s Claude 4 family, designed as hybrid-reasoning language models that blend internal chain-of-thought with dynamic tool use. Both models feature two key innovations:
- Thinking Summaries: Automatically generated overviews of the model’s reasoning steps, which improve transparency and help developers understand decision pathways.
- Extended Thinking (beta): A mode that balances internal reasoning with external tool calls—such as web search or code execution—to optimize task performance over longer, complex workflows.
Origins and positioning
- Claude Opus 4 is positioned as Anthropic’s flagship reasoning engine. It sustains autonomous task execution for up to seven hours and outperforms competing large models—including Google’s Gemini 2.5 Pro, OpenAI’s o3 reasoning model, and GPT-4.1—on benchmarked coding and tool-use tasks.
- Claude Sonnet 4 succeeds Claude Sonnet 3.7 as a cost-effective workhorse optimized for general-purpose use. It offers superior instruction following, tool selection, and error correction relative to its predecessor, while maintaining high throughput for customer-facing agents and AI workflows .
Availability and pricing
- API and cloud platforms: Both models are accessible via the Anthropic API as well as through major cloud marketplaces—Amazon Bedrock, Google Cloud Vertex AI, Databricks, Snowflake Cortex AI, and GitHub Copilot.
- Free vs. paid tiers: Free-tier users can access Claude Sonnet 4, while Claude Opus 4 and extended-thinking features require a paid subscription .
How do Opus 4 and Sonnet 4 core capabilities compare?
While both models share underlying architecture and safety foundations, their tuning and performance envelopes are tailored to distinct use cases.
Coding and Development Workflows
Claude Opus 4 sets a new bar for AI-driven software engineering, achieving top marks on industry benchmarks such as SWE-bench (72.5%) and Terminal-bench (43.2%) and sustaining autonomous code generation for days-long refactoring pipelines . Its support for 32 K+ token contexts and background task execution (“Claude Code”) allows developers to offload complex multi-file edits and iterative debugging to the model. Conversely, Claude Sonnet 4—while not matching Opus 4’s absolute peak performance—is still 20% more accurate than Sonnet 3.7 on average in developer-oriented workflows and excels in rapid prototyping, code review, and interactive chat-based assistance.
Reasoning, Memory, and Planning
Both models introduce extended memory windows that retain context over sessions up to seven hours, a breakthrough for applications requiring sustained dialogues or long-running agentic processes . Their “thinking summaries” feature surfaces concise overviews of internal chain-of-thought, boosting transparency for complex decision paths. Opus 4’s summaries are particularly detailed—suited for research-grade analyses—whereas Sonnet 4’s leaner summaries prioritize clarity and speed to serve customer support bots and high-volume chat interfaces.
Safety and Ethical Considerations
Given the potency of Claude Opus 4—demonstrated by its ability to guide multi-step tasks that could pose biosecurity risks—Anthropic applied its Responsible Scaling Policy at AI Safety Level 3 (ASL-3), enforcing anti-jailbreak classifiers, cybersecurity hardening, and an external bounty program for vulnerability discovery . Sonnet 4, while still governed by robust filter and red-teaming protocols, is rated ASL-2, reflecting a lower risk profile aligned with its less autonomous usage scenarios . Anthropic’s voluntary self-regulation aims to demonstrate that rigorous safety need not impede commercial deployment.
Performance Benchmarks
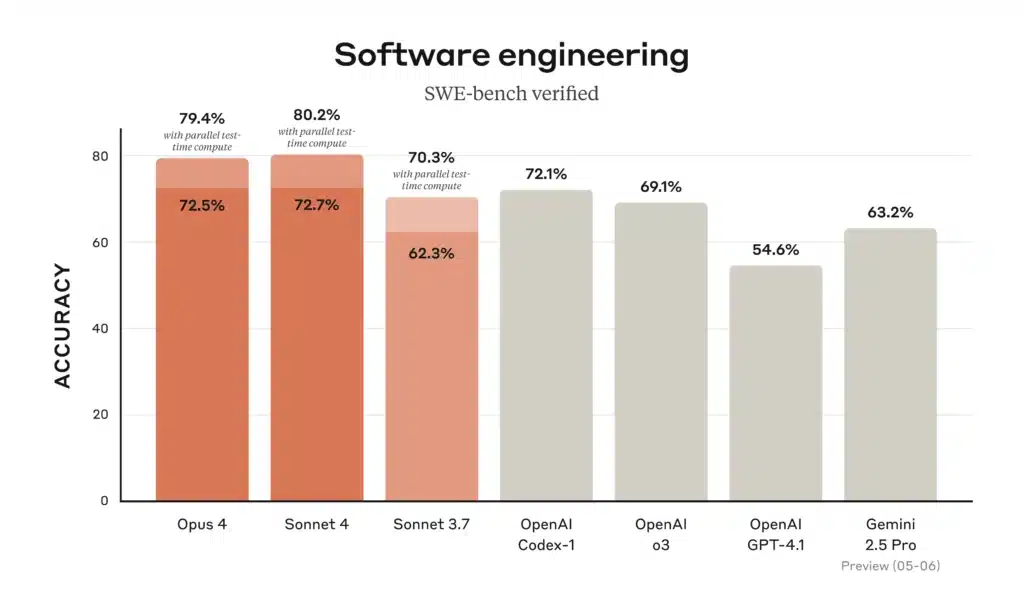
Figure: Software-engineering (SWE-bench Verified) accuracy for Claude 4 models vs prior models (higher is better). Opus 4 and Sonnet 4 both rank at the top of standard benchmarks. On Anthropic’s SWE-bench (software engineering) test, Opus 4 scores ~72.5% and Sonnet 4 ~72.7% (far above Claude Sonnet 3.7’s ~62%). The figure above (from Anthropic) illustrates that both new models (orange bars) outperform previous Claude versions and even GPT-4.1 on real coding tasks.
- Coding (SWE-bench): Opus 4 = 72.5%; Sonnet 4 = 72.7%. Both far exceed older models (Sonnet 3.7 = 62.3%, GPT-4.1 ≈54.6%). This confirms Anthropic’s claim that both Claude 4 models lead on coding benchmarks.
- Graduate-level reasoning (GPQA Diamond): Anthropic reports Opus 4 at 74.9% vs Sonnet 4 at 70.0%. This is an internal benchmark for complex science reasoning; Opus holds a modest edge here.
- Knowledge (MMLU): Opus 4: 87.4% vs Sonnet 4: 85.4% on MMLU. Again Opus is slightly higher, but both score strongly (Anthropic notes that Sonnet 4 “significantly improves” over 3.7 on MMLU).
- Independent coding tests: In open evaluations, both models perform excellently. For example, a third-party test on a Next.js coding task gave Opus 4 a 9.5/10 and Sonnet 4 a 9.25/10 (both tied or above GPT-4.1 on that challenge). Both models produced concise, correct code more reliably than other LLMs.
- Other benchmarks: On the high-school math contest (AIME), both score low (~33%, a known difficulty for all LLMs). For tool-using and agent tasks (TAU-bench variants), Anthropic reports strong results (>80% on some sub-tasks) for both models. In summary, Opus 4 usually has a slight performance advantage on difficult benchmarks, but Sonnet 4 remains extremely capable; often the trade-off is cost and speed.
Overall, Claude Opus 4 is the top-tier model (best for ultra-demanding tasks), while Claude Sonnet 4 delivers nearly as much power with much higher efficiency. Their pricing and availability reflect this: Sonnet 4 is ideal for scaled applications (and free users), whereas Opus 4 is reserved for teams needing every last bit of performance.
Pricing
Token costs (API): Opus 4 is priced at $15 per million input tokens and $75 per million output tokens, whereas Sonnet 4 costs only $3/$15 (input/output). These rates match Anthropic’s previous Claude v4 pricing.
Discounts: Anthropic offers heavy discounts on Opus 4: prompt caching can cut token costs by up to 90%, and batch processing by up to 50%. (Sonnet 4’s lower base cost makes it cheaper even without these features.)
Subscription inclusion: Sonnet 4 is included even on the free Claude plan, while Opus 4 requires a paid Claude Pro/Team/Enterprise subscription. In practice, this means all Sonnet 4 usage (in Claude Chat or API) is very low-cost, but Opus 4 is only available to paying customers.
How Does Sonnet 4 Compare to Claude Opus 4 in Use Cases?
While Opus 4 is Anthropic’s flagship model for peak performance, Sonnet 4 carves its niche in practicality and accessibility.
Performance vs. Practicality
- Raw Capability: In head-to-head benchmarks, Opus 4 surpasses Sonnet 4 in complex reasoning, code generation accuracy, and sustained multi-step workflows, reflecting its “best-in-class” status .
- Efficiency: Sonnet 4 delivers approximately 80 percent of Opus 4’s performance at half the computational cost, making it an attractive option for routine tasks and budget-sensitive projects .
Use Case Scenarios
| Use Case | Claude Sonnet 4 | Claude Opus 4 |
|---|---|---|
| Day-to-day coding | ✔️ Balanced speed and accuracy | ✔️ Maximum accuracy |
| Research and scientific AI | ✔️ Good for summaries and prototyping | ✔️ Superior deep-dive reasoning |
| Autonomous agentic workflows | ✔️ Entry-level agents | ✔️ High-complexity, long-horizon |
| Cost-sensitive deployments | ✔️ Optimized for resource efficiency | ❌ Premium tier only |
Availability and Integration with Developer Tools
Claude Chat & Apps: Both models are accessible on Anthropic’s Claude interface (web and apps). Sonnet 4 is available to all users, including free-tier, while Opus 4 can only be used on paid plans (Pro/Max/Team/Enterprise).
Anthropic API & Cloud Platforms: Both Claude models are accessible via Anthropic’s REST API, and are listed on major cloud platforms. Anthropic says this “gives developers immediate access” to the models and their reasoning and agentic capabilities.
IDEs and Editor Plugins: Anthropic has deeply integrated Claude 4 into coding workflows. The new Claude Code product embeds Claude right in developer environments. Beta extensions for VS Code and JetBrains IDEs let the model propose code edits inline within your files. There’s also a GitHub Actions integration: you can tag Claude Code on a pull request to automatically fix a failing CI test or respond to reviewer comments. A Claude Code SDK lets you run Claude as a subprocess on local machines. In short, Sonnet 4 and Opus 4 can now work as pair-programmers in familiar tools. Anthropic notes that GitHub will use Sonnet 4 as the model behind its new AI-assisted coding agent, and connectors already exist for VS Code, JetBrains, and GitHub. This ecosystem means developers can leverage Claude’s capabilities without leaving their usual environment.
APIs and Workflow Automation: Both models fully support programmatic use. Anthropic’s API (v1) has been updated to let you toggle thinking modes, set safety levels, and attach tool connectors. In practice, a Python client call might look identical except for the model name (claude-opus-4-20250514 vs claude-sonnet-4-20250514). On CometAPI, the API provides a unified interface to call either model. Developers can integrate them into automated workflows (CI/CD, monitoring, data pipelines) using their preferred language or REST clients.
Comparison Chart
| Feature | Claude Opus 4 | Claude Sonnet 4 |
|---|---|---|
| Model Type | Largest “Opus” model – focused on maximum reasoning power. | Mid-size model – balance of speed, cost, and capability. |
| Context Window | 200K tokens (huge context); extremely long documents or multi-file code. | 200K tokens (same very large context). |
| Output Length | Up to 32K tokens per response (suitable for complex code outputs). | Up to 64K tokens per response (longer outputs). |
| Performance (SWE-bench) | ~72.5–79% (leading coding benchmark). | ~72.7–80% (very similar coding score). |
| Performance (General IQ) | Strong advanced reasoning (MMLU ~87%). Slightly outperforms Sonnet. | Strong reasoning (MMLU ~85%); slightly lower than Opus on hard tasks. |
| Use Case Examples | Best for long-running code projects, deep research, and agent planning (e.g. refactoring multi-file projects, hours-long simulations). | Best for high-volume tasks and interactive agents (e.g. live chatbots, code reviews, CI automation). |
| Extended Thinking | Yes (64K-token thinking mode; great for deep multi-step reasoning). Ideal for tasks benefiting from longer “thoughts.” | Yes (64K-token thinking mode). Also supports it, with user-visible reasoning summaries. |
| Tool Support | Full tool use (parallel web search, code execution, file I/O, etc.). | Full tool use (same capability). |
| Memory & “Files” | Advanced long-term memory via Files API; excels at tracking project state. | Same memory features; can store and recall facts as well. |
| Multimodal Input | Strong code+text; can process images via tools (vision analysis). Primarily text/coding tasks. | Includes vision and UI capabilities; can parse images/screenshots and even “use” software UIs. |
| Latency & Throughput | Higher latency (heavier compute). Best for batch/automated workflows where depth matters. | Lower latency (faster responses). Optimized for interactive and streaming use. |
| Availability | Anthropic API (Pro/Enterprise), AWS Bedrock, GCP Vertex. Paid-tier only. | Anthropic API (all tiers), AWS Bedrock, GCP Vertex. Also free on Claude. |
| Pricing (tokens) | $15 per M input, $75 per M output. | $3 per M input, $15 per M output. |
| Safety/Alignment | Highest-tier safety (ASL-3+ measures), “least likely” to shortcut. | Same robust safety measures (ASL-3). Slightly more efficient, same alignment. |
Conclusion
In 2025, Anthropic’s Claude Opus 4 and Sonnet 4 represent a significant leap for developer-focused AI. They introduce extended multimodal reasoning, deeper tool integration, and unprecedented context lengths that directly address challenges in moderndevelopment workflows. By embedding these models through API or cloud platforms, teams can automate far more of the software lifecycle – from code design to deployment – without losing accuracy or alignment. Opus 4 brings frontier AI reasoning to complex, open-ended tasks, while Sonnet 4 brings high-speed, budget-friendly performance to everyday coding and agent needs.
These improvements – extended thinking, memory files, parallel tools, and streamlined IDE integration – are not just incremental. They reshape how developers interact with AI: shifting from quick one-off completions to sustained collaboration across hours of work. The upshot is that routine development tasks become faster and more reliable, allowing engineers to focus on creativity and oversight. As Anthropic says, with Claude 4 “you can use Opus 4 to write and refactor code across entire projects” and Sonnet 4 to power “everyday development tasks”.
Getting Started
CometAPI provides a unified REST interface that aggregates hundreds of AI models—including Claude family—under a consistent endpoint, with built-in API-key management, usage quotas, and billing dashboards. Instead of juggling multiple vendor URLs and credentials.
Developers can access Claude Sonnet 4 API (model: claude-sonnet-4-20250514 ; claude-sonnet-4-20250514-thinking) and Claude Opus 4 API (model: claude-opus-4-20250514; claude-opus-4-20250514-thinking)etc through CometAPI. . To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI’ve also added cometapi-sonnet-4-20250514andcometapi-sonnet-4-20250514-thinking specifically for use in Cursor.
New to CometAPI? Start a free 1$ trial and unleash Sonnet 4 on your toughest tasks.
We can’t wait to see what you build. If something feels off, hit the feedback button—telling us what broke is the fastest way to make it better.