

The last few months have seen a rapid escalation in agentic coding: specialist models that don’t just answer one-off prompts but plan, edit, test and iterate across entire repositories. Two of the highest-profile entrants are Composer, a purpose-built, low-latency coding model introduced by Cursor with its Cursor 2.0 release, and GPT-5-Codex, OpenAI’s agent-optimized variant of GPT-5 tuned for sustained coding workflows. Together they illustrate the new fault lines in developer tooling: speed vs. depth, local workspace awareness vs. generalist reasoning, and “vibe-coding” convenience vs. engineering rigor.
At a glance: head-to-head distinctions
- Design intent: GPT-5-Codex — deep, agentic reasoning and robustness for long, complex sessions; Composer — snappy, workspace-aware iteration optimized for speed.
- Primary integration surface: GPT-5-Codex — Codex product/Responses API, IDEs, enterprise integrations; Composer — Cursor editor and Cursor’s multi-agent UI.
- Latency/iteration: Composer emphasizes sub-30-second turns and claims large speed advantages; GPT-5-Codex prioritizes thoroughness and multi-hour autonomous runs where required.
I tested the GPT-5-Codex API model provided by CometAPI (a third-party API aggregation provider, whose API prices are generally cheaper than the official one), summarized my experience using Cursor 2.0 ‘s Composer model, and compared the two in various dimensions of code generation judgment.
What are Composer and GPT-5-Codex
What is GPT-5-Codex and what problems does it aim to solve?
OpenAI’s GPT-5-Codex is a specialized snapshot of GPT-5 that OpenAI states is optimized for agentic coding scenarios: running tests, performing repository-scale code edits, and iterating autonomously until checks pass. The focus here is broad capability across many engineering tasks — deep reasoning for complex refactors, longer-horizon “agentic” operation (where the model can spend minutes to hours reasoning and testing), and stronger performance on standardized benchmarks designed to reflect real-world engineering problems.
What is Composer and what problems does it aim to solve?
Composer is Cursor’s first native coding model, surfaced with Cursor 2.0. Cursor describes Composer as a frontier, agent-centric model built for low latency and fast iteration inside developer workflows: planning multi-file diffs, applying repository-wide semantic search, and completing most turns in under 30 seconds. It was trained with tool access in the loop (search, edit, test harnesses) to be efficient on practical engineering tasks and to minimize the friction of repeated prompt→response cycles in everyday coding. Cursor positions Composer as a model optimized for developer velocity and real-time feedback loops.
Model scope & runtime behavior
- Composer: optimized for fast, editor-centric interactions and multi-file consistency. Cursor’s platform-level integration enables Composer to see more of the repository and to participate in multi-agent orchestration (e.g., two Composer agents vs. others), which Cursor argues reduces missed dependencies across files.
- GPT-5-Codex: optimized for deeper, variable-length reasoning. OpenAI advertises the model’s ability to trade compute/time for deeper reasoning when necessary — reportedly ranging from seconds for lightweight tasks up to hours for extensive autonomous runs — enabling more thorough refactors and test-guided debugging.
Short version: Composer = Cursor’s in-IDE, workspace-aware coding model; GPT-5-Codex = OpenAI’s specialized GPT-5 variant for software engineering, available via Responses/Codex.
How do Composer and GPT-5-Codex compare in speed?
What did the vendors claim?
Cursor positions Composer as a “fast frontier” coder: published numbers highlight generation throughput measured in tokens per second and claims of 2–4× faster interactive completion times vs. “frontier” models in Cursor’s internal harness. Independent coverage (press and early testers) reports Composer producing code at ~200–250 tokens/sec in Cursor’s environment and completing typical interactive coding turns in under 30 seconds in many cases.
OpenAI’s GPT-5-Codex is not positioned as a latency experiment; it prioritizes robustness and deeper reasoning and — on comparable high-reasoning workloads — can be slower when used at higher context sizes, according to community reports and issue threads.
How we benchmarked speed (methodology)
To produce a fair speed comparison you must control the task type (short completions vs long reasoning), the environment (network latency, local vs cloud integration) and measure both time-to-first-useful-result and end-to-end wall-clock (including any test execution or compile steps). Key points:
- Tasks chosen — small snippet generation (implementing an API endpoint), medium task (refactor one file and update imports), large task (implement feature across three files, update tests).
- Metrics — time-to-first-token, time-to-first-useful-diff (time until candidate patch is emitted), and total time including test execution & verification.
- Repetitions — each task run 10×, median used to reduce network noise.
- Environment — measurements taken from a developer machine in Tokyo (to reflect real-world latency) with stable 100/10 Mbps link; results will vary regionally.
Below is a reproducible speed harness for GPT-5-Codex (Responses API) and a description of how to measure Composer (inside Cursor).
Speed harness (Node.js) — GPT-5-Codex (Responses API):
// node speed_harness_gpt5_codex.js
// Requires: node16+, npm install node-fetch
import fetch from "node-fetch";
import { performance } from "perf_hooks";
const API_KEY = process.env.OPENAI_API_KEY; // set your key
const ENDPOINT = "https://api.openai.com/v1/responses"; // OpenAI Responses API
const MODEL = "gpt-5-codex";
async function runPrompt(prompt) {
const start = performance.now();
const body = {
model: MODEL,
input: prompt,
// small length to simulate short interactive tasks
max_output_tokens: 256,
};
const resp = await fetch(ENDPOINT, {
method: "POST",
headers: {
"Authorization": `Bearer ${API_KEY}`,
"Content-Type": "application/json"
},
body: JSON.stringify(body)
});
const json = await resp.json();
const elapsed = performance.now() - start;
return { elapsed, output: json };
}
(async () => {
const prompt = "Implement a Node.js Express route POST /signup that validates email and stores user in-memory with hashed password (bcrypt). Return code only.";
const trials = 10;
for (let i=0;i<trials;i++){
const r = await runPrompt(prompt);
console.log(`trial ${i+1}: ${Math.round(r.elapsed)} ms`);
}
})();
This measures end-to-end request latency for GPT-5-Codex using the public Responses API (OpenAI docs describe Responses API and gpt-5-codex model usage).
How to measure Composer speed (Cursor):
Composer runs inside Cursor 2.0 (desktop/VS Code fork). Cursor does not (as of writing) provide a general external HTTP API for Composer that matches OpenAI’s Responses API; Composer’s strength is in-IDE, stateful workspace integration. Therefore measure Composer like a human developer would:
- Open the same project inside Cursor 2.0.
- Use Composer to run the identical prompt as an agent task (create route, refactor, multi-file change).
- Start a stopwatch when you submit the Composer plan; stop when Composer emits the atomic diff and runs the test suite (Cursor’s interface can run tests and show a consolidated diff).
- Repeat 10× and use median.
Cursor’s published materials and hands-on reviews show Composer completing many common tasks in under ~30 seconds in practice; this is an interactive latency target rather than raw model inference time.
Takeaway: Composer’s design goal is rapid interactive edits inside an editor; if your priority is low-latency, conversational coding loops, Composer is built for that use case. GPT-5-Codex is optimized for correctness and agentic reasoning across longer sessions; it can trade a bit more latency for deeper planning. Vendor numbers support this positioning.
How do Composer and GPT-5-Codex compare in accuracy?
What accuracy means in coding AI
Accuracy here is multi-faceted: functional correctness (does the code compile and pass tests), semantic correctness (does the behavior meet the spec), and robustness (handles edge cases, security concerns).
Vendor and press numbers
OpenAI reports GPT-5-Codex strong performance on SWE-bench verified datasets and highlighted a 74.5% success rate on a real-world coding benchmark (reported in press coverage) and a notable lift in refactoring success (51.3% vs 33.9 for base GPT-5 on their internal refactor test).
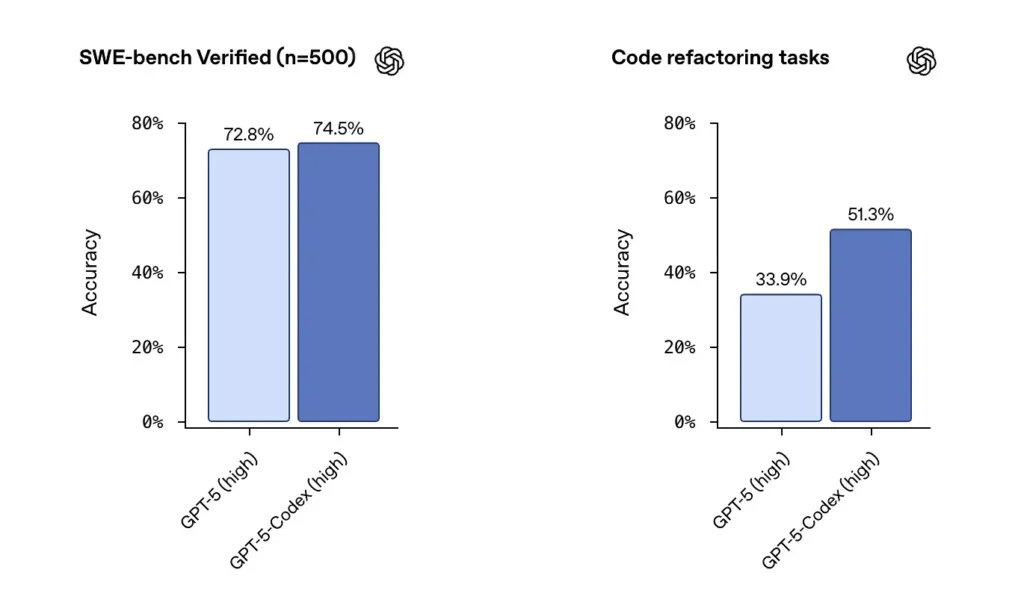
Cursor’s release indicate Composer often excels at multi-file, context-sensitive edits where editor integration and repo visibility matter. After my testing reported that Composer produced fewer missed dependency errors during multi-file refactors and scored higher on blind review tests for some multi-file workloads.Composer’s latency and parallel-agent features also help me improve iteration speed.
Independent accuracy testing (recommended method)
A fair test uses a mixture of:
- Unit tests: feed the same repo and test suite to both models; generate code, run tests.
- Refactor tests: provide an intentionally messy function and ask model to refactor and add tests.
- Security checks: run static analysis and SAST tools on generated code (e.g., Bandit, ESLint, semgrep).
- Human review: code review scores by experienced engineers for maintainability and best practices.
Example: automated test harness (Python) — run generated code and unit tests
# python3 run_generated_code.py
# This is a simplified harness: it writes model output to file, runs pytest, captures results.
import subprocess, tempfile, os, textwrap
def write_file(path, content):
with open(path, "w") as f:
f.write(content)
# Suppose `generated_code` is the string returned from model
generated_code = """
# sample module
def add(a,b):
return a + b
"""
tests = """
# test_sample.py
from sample import add
def test_add():
assert add(2,3) == 5
"""
with tempfile.TemporaryDirectory() as d:
write_file(os.path.join(d, "sample.py"), generated_code)
write_file(os.path.join(d, "test_sample.py"), tests)
r = subprocess.run(, cwd=d, capture_output=True, text=True, timeout=30)
print("pytest returncode:", r.returncode)
print(r.stdout)
print(r.stderr)
Use this pattern to automatically assert whether model output is functionally correct (passes tests). For refactoring tasks, run the harness against the original repo plus model’s diff and compare test pass rates and coverage changes.
Takeaway: On raw benchmark suites, GPT-5-Codex reports excellent numbers and strong refactoring prowess. In real-world, multi-file repair and editor workflows, Composer’s workspace awareness can yield higher practical acceptance and fewer “mechanical” errors (missing imports, wrong filenames). For maximal functional correctness in single-file algorithmic tasks, GPT-5-Codex is a strong candidate; for multi-file, convention-sensitive changes inside an IDE, Composer often shines.
Composer vs GPT-5: How do they compare for code quality?
What counts as quality?
Quality includes readability, naming, documentation, test coverage, use of idiomatic patterns, and security hygiene. It’s measured both automatically (linters, complexity metrics) and qualitatively (human review).
Observed differences
- GPT-5-Codex: strong at producing idiomatic patterns when asked explicitly; excels in algorithmic clarity and can produce comprehensive test suites when prompted. OpenAI’s Codex tooling includes integrated test/reporting and execution logs.
- Composer: optimized to observe a repo’s style and conventions automatically; Composer can follow existing project patterns and coordinate updates to multiple files (renaming/refactoring propagation, importing updates). It offers excellent on-demand maintainability for large projects.
Example Code Quality checks you can run
- Linters — ESLint / pylint
- Complexity — radon / flake8-complexity
- Security — semgrep / Bandit
- Test coverage — run coverage.py or vitest/nyc for JS
Automate these checks after applying the model’s patch to quantify improvements or regressions. Example command sequence (JS repo):
# after applying model patch
npm ci
npm test
npx eslint src/
npx semgrep --config=auto .
Human review & best practices
In practice, models require instruction to follow best practices: ask for docstrings, type annotations, dependency pinning, or specific patterns (e.g., async/await). GPT-5-Codex is excellent when given explicit directives; Composer benefits from the implicit repository context. Use a combined approach: instruct the model explicitly and let Composer enforce project style if you’re inside Cursor.
Recommendation: For multi-file engineering work inside an IDE, prefer Composer; for external pipelines, research tasks, or toolchain automation where you can call an API and supply large context, GPT-5-Codex is a strong choice.
Integrations and deployment options
Composer ships as part of Cursor 2.0, embedded in the Cursor editor and UI. Cursor’s approach stresses a single vendor control plane that runs Composer alongside other models — letting users run multiple model instances on the same prompt and compare outputs inside the editor. ()
GPT-5-Codex is being rolled into OpenAI’s Codex offering and ChatGPT product family, with availability through ChatGPT paid tiers and API that third-party platforms such as CometAPI offer better value for money. OpenAI is also integrating Codex into developer tooling and cloud partner workflows (for example Visual Studio Code/GitHub Copilot integrations ).
Where might Composer and GPT-5-Codex push the industry next?
Short-term effects
- Faster iteration cycles: Editor-embedded models like Composer reduce friction on small fixes and PR generation.
- Rising expectations for verification: Codex’s emphasis on tests, logs, and autonomous capability will push vendors to provide stronger out-of-the-box verification for model-produced code.
Mid to long term
- Multi-model orchestration becomes normal: Cursor’s multi-agent GUI is an early hint that engineers will soon expect to run several specialized agents in parallel (linting, security, refactoring, performance optimization) and accept best outputs.
- Tighter CI/AI feedback loops: As models improve, CI pipelines will increasingly incorporate model-driven test generation and automated repair suggestions — but human review and staged rollout remain crucial.
Conclusion
Composer and GPT-5-Codex are not identical weapons in the same arms race; they are complementary tools optimized for different parts of the software lifecycle. Composer’s value proposition is velocity: rapid, workspace-grounded iteration that keeps developers in flow. GPT-5-Codex’s value is depth: agentic persistence, test-driven correctness and auditability for heavyweight transformations. The pragmatic engineering playbook is to orchestrate both: short-loop Composer-like agents for everyday flow, and GPT-5-Codex-style agents for gated, high-confidence operations. Early benchmarks suggest both will be part of the near-term developer toolkit rather than one supplanting the other.
There’s no single objective winner across all dimensions. The models trade strengths:
- GPT-5-Codex: stronger on deep correctness benchmarks, large-scope reasoning, and autonomous multi-hour workflows. It shines when task complexity requires long reasoning or heavy verification.
- Composer: stronger in tight editor-integrated use cases, multi-file context consistency, and fast iteration speed inside Cursor’s environment. It can be better for day-to-day developer productivity where immediate, accurate context-aware edits are needed.
See also Cursor 2.0 and Composer: how a multi-agent rethink surprised AI coding
Getting Started
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
Developers can access GPT-5-Codex APIthrough CometAPI, the latest model version is always updated with the official website. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!