

OpenAI published a research preview of gpt-oss-safeguard, an open-weight inference model family engineered to let developers enforce their own safety policies at inference time. Rather than shipping a fixed classifier or a black-box moderation engine, the new models are fine-tuned to reason from a developer-provided policy, emit a chain-of-thought (CoT) explaining their reasoning, and produce structured classification outputs. Announced as a research preview, gpt-oss-safeguard is presented as a pair of reasoning models—gpt-oss-safeguard-120b and gpt-oss-safeguard-20b—fine-tuned from the gpt-oss family and explicitly designed to perform safety classification and policy enforcement tasks during inference.
What is gpt-oss-safeguard?
gpt-oss-safeguard is a pair of open-weight, text-only reasoning models that have been post-trained from the gpt-oss family to interpret a policy written in natural language and label text according to that policy. The distinguishing feature is that the policy is provided at inference time (policy-as-input), not baked into static classifier weights. The models are designed primarily for safety classification tasks—e.g., multi-policy moderation, content classification across multiple regulatory regimes, or policy compliance checks.
Why this matters
Traditional moderation systems typically rely on (a) fixed rule sets mapped to classifiers trained on labeled examples, or (b) heuristics / regexes for keyword detection. gpt-oss-safeguard attempts to change the paradigm: instead of re-training classifiers whenever policy changes, you supply a policy text (for example, your company’s acceptable-use policy, platform TOS, or a regulator’s guideline), and the model reasons about whether a given piece of content violates that policy. This promises agility (policy changes without retraining) and interpretability (the model outputs its chain of reasoning).
This is its core philosophy—”Replacing memorization with reasoning, and guessing with explanation.”
This represents a new stage in content security, moving from “passively learning rules” to “actively understanding rules.”
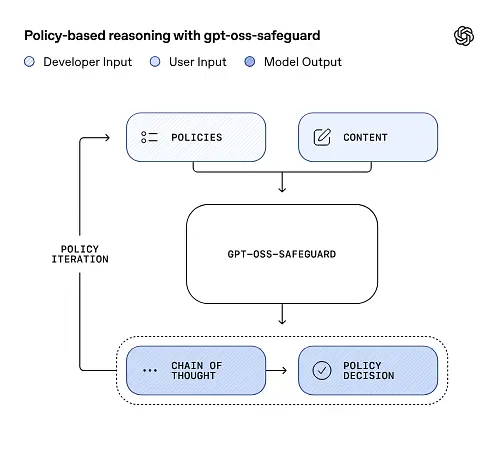
gpt-oss-safeguard can directly read the security policies defined by the developers and follow those policies to make judgments during inference.
How does gpt-oss-safeguard work?
Policy-as-input reasoning
At inference time, you provide two things: the policy text and the candidate content to be labeled. The model treats the policy as the primary instruction and then performs step-by-step reasoning to determine whether the content is allowed, disallowed, or requires additional moderation steps. At inference the model:
- produces a structured output that includes a conclusion (label, category, confidence) and a human-readable reasoning trace explaining why that conclusion was reached.
- ingests the policy and the content to be classified,
- internally reasons through the policy’s clauses using chain-of-thought-like steps, and
For example:
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
It will respond:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
Chain-of-Thought (CoT) and structured outputs
gpt-oss-safeguard can emit a full CoT trace as part of each inference. The CoT is intended to be inspectable—compliance teams can read why the model reached a conclusion, and engineers can use the trace to diagnose policy ambiguity or model failure modes. The model also supports structured outputs—for example, a JSON that contains a verdict, violated policy sections, severity score, and suggested remediation actions—making it straightforward to integrate into moderation pipelines.
Tunable “reasoning effort” levels
To balance latency, cost, and thoroughness the models support configurable reasoning effort: low / medium / high. Higher effort increases the depth of chain-of-thought and generally yields more robust, but slower and costlier, inferences. This allows developers to triage workloads—use low effort for routine content and high effort for edge cases or high-risk content.
What is the model structure and what versions exist?
Model family and lineage
gpt-oss-safeguard are post-trained variants of OpenAI’s earlier gpt-oss open models. The safeguard family currently includes two released sizes:
- gpt-oss-safeguard-120b — a 120-billion parameter model intended for high-accuracy reasoning tasks that still runs on a single 80GB GPU in optimized runtimes.
- gpt-oss-safeguard-20b — a 20-billion parameter model optimized for lower-cost inference and edge or on-prem environments (can run on 16GB VRAM devices in some configurations).
Architecture notes and runtime characteristics (what to expect)
- Active parameters per token: The underlying gpt-oss architecture uses techniques that reduce the number of parameters activated per token (a mix of dense and sparse attention / mixture-of-experts style design in the parent gpt-oss).
- practically, the 120B class fits on single large accelerators and the 20B class is designed to operate on 16GB VRAM setups in optimized runtimes.
Safeguard models were not trained with additional biological or cybersecurity data, and that analyses of worst-case misuse scenarios performed for the gpt-oss release roughly apply to the safeguard variants. The models are intended for classification rather than content generation for end users.
What are the goals of gpt-oss-safeguard
Goals
- Policy flexibility: let developers define any policy in natural language and have the model apply it without custom label collection.
- Explainability: expose reasoning so decisions can be audited and policies iterated.
- Accessibility: provide an open-weight alternative so organizations can run safety reasoning locally and inspect model internals.
Comparison with classic classifiers
Pros vs. traditional classifiers
- No retraining for policy changes: If your moderation policy changes, update the policy document rather than collecting labels and retraining a classifier.
- Richer reasoning: CoT outputs can reveal subtle policy interactions and provide narrative justification useful to human reviewers.
- Customizability: A single model can apply many different policies simultaneously during inference.
Cons vs. traditional classifiers
- Performance ceilings for some tasks: OpenAI’s evaluation notes that high-quality classifiers trained on tens of thousands of labeled examples can outperform gpt-oss-safeguard on specialized classification tasks. When the objective is raw classification accuracy and you have labeled data, a dedicated classifier trained on that distribution can be better.
- Latency and cost: Reasoning with CoT is compute-intensive and slower than a lightweight classifier; this can make purely safeguard-based pipelines expensive at scale.
In short: gpt-oss-safeguard is best used where policy agility and auditability are priorities or when labeled data is scarce — and as a complementary component in hybrid pipelines, not necessarily as a drop-in replacement for a scale-optimized classifier.
How did gpt-oss-safeguard perform in OpenAI’s evaluations?
OpenAI published baseline results in a 10-page technical report summarizing internal and external evaluations. Key takeaways (selected, load-bearing metrics):
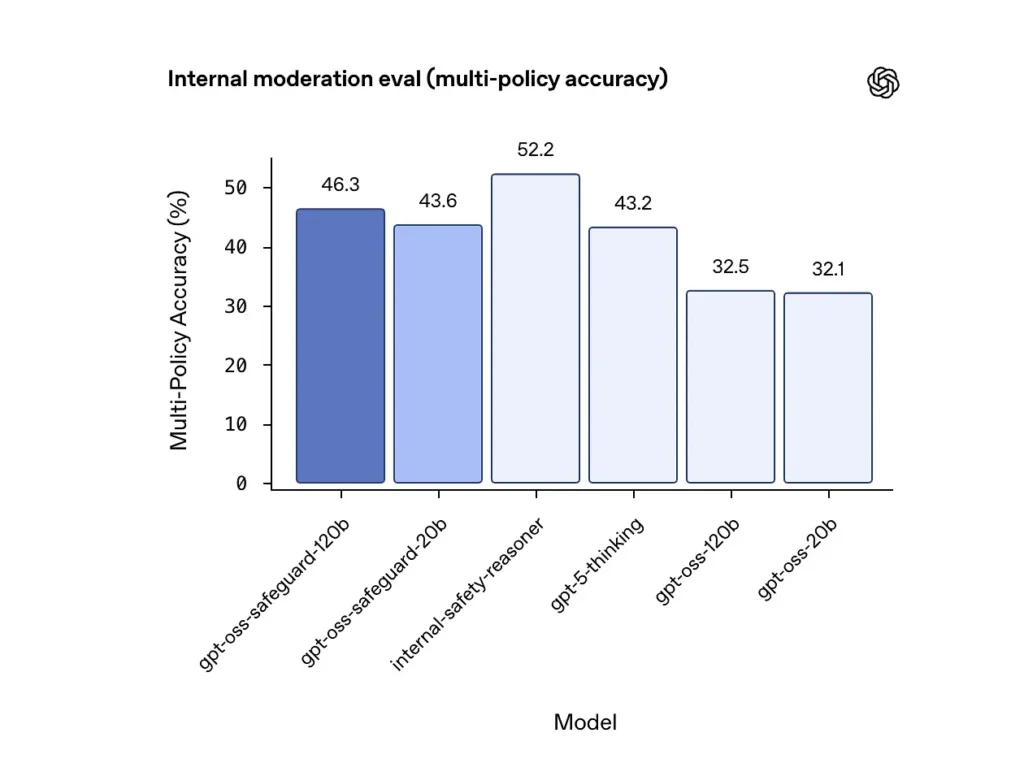
Multi-policy accuracy (internal evaluation)
OpenAI evaluated multi-policy accuracy by giving the model multiple policies simultaneously and counting a prediction as correct only if it matched the golden labels across all policies. Results:
- gpt-oss-safeguard-120b: 46.3% multi-policy accuracy
- gpt-oss-safeguard-20b: 43.6%
- For comparison: gpt-5-thinking: 43.2%; gpt-oss-120b: 32.5%; gpt-oss-20b: 32.1%.
OpenAI’s internal “safety-reasoner” ensemble scored 52.2% in the same test. These numbers show the safeguard models outperform their gpt-oss base models substantially on the multi-policy task, and they even exceeded the larger gpt-5-thinking baseline in the internal multi-policy metric.
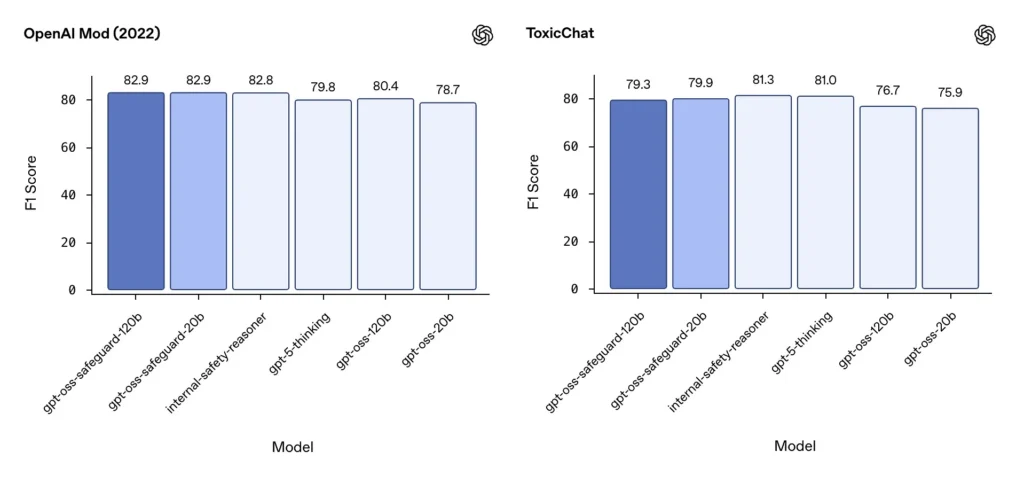
Moderation F1 (external benchmarks)
On OpenAI’s 2022 moderation dataset and the public ToxicChat benchmark, gpt-oss-safeguard models achieved solid F1 scores:
- OpenAI Mod (2022) F1: gpt-oss-safeguard-120b = 82.9%, gpt-oss-safeguard-20b = 82.9%
- ToxicChat F1: gpt-oss-safeguard-120b = 79.3%, gpt-oss-safeguard-20b = 79.9%
These scores place gpt-oss-safeguard near or slightly behind specialized OpenAI internal systems on some benchmarks, and generally ahead of the unfine-tuned gpt-oss counterparts.
Observed limitations
OpenAI flags two practical limitations:
- Classifiers trained on large, task-specific labeled datasets can still outperform safeguard models when classification accuracy is the only objective.
- Compute and latency costs: CoT reasoning increases inference time and compute consumption, which complicates scaling to platform-level traffic unless paired with triage classifiers and asynchronous pipelines.
Multilingual parity
gpt-oss-safeguard performs at parity with the underlying gpt-oss models across many languages in MMMLU-style tests, indicating the fine-tuned safeguard variants retain broad reasoning ability.
How can teams access and deploy gpt-oss-safeguard?
OpenAI provides the weights under Apache 2.0 and links the models for download (Hugging Face). Because gpt-oss-safeguard is an open-weight model, Local and self-managed deployment (recommended for privacy and customization)
- Download model weights (from OpenAI / Hugging Face) and host them on your own servers or cloud VMs. Apache 2.0 allows modification and commercial use.
- Runtime: Use standard inference runtimes that support large transformer models (ONNX Runtime, Triton, or optimized vendor runtimes). Community runtimes like Ollama and LM Studio are already adding support for gpt-oss families.
- Hardware: 120B typically requires high-memory GPUs (e.g., 80GB A100 / H100 or multi-GPU sharding), while 20B can be run more cheaply and has options optimized for 16GB VRAM setups. Plan capacity for peak throughput and multi-policy evaluation costs.
Managed and third-party runtimes
If running your own hardware is impractical, CometAPI is rapidly adding support for gpt-oss models. These platforms may provide easier scaling but reintroduce third-party data exposure tradeoffs. Evaluate privacy, SLAs, and access controls before choosing managed runtimes.
Effective moderation strategies with gpt-oss-safeguard
1) Use a hybrid pipeline (triage → reason → adjudicate)
- Triage layer: small, fast classifiers (or rules) filter out trivial cases. This reduces load on the expensive safeguard model.
- Safeguard layer: run gpt-oss-safeguard for ambiguous, high-risk, or multi-policy checks where policy nuance matters.
- Human adjudication: escalate edge cases and appeals, storing CoT as evidence for transparency. This hybrid design balances throughput and precision.
2) Policy engineering (not prompt engineering)
- Treat policies as software artifacts: version them, test them against datasets, and keep them explicit and hierarchical.
- Write policies with examples and counterexamples. When possible, include disambiguating instructions (e.g., “If user intent is clearly exploratory and historical, label as X; if intent is operational and real-time, label as Y”).
3) Configure reasoning effort dynamically
- Use low effort for bulk processing and high effort for flagged content, appeals, or high-impact verticals (legal, medical, finance).
- Tune thresholds with human review feedback to find the cost/quality sweet spot.
4) Validate CoT and watch for hallucinated reasoning
The CoT is valuable, but it can hallucinate: the trace is a model-generated rationale, not ground truth. Audit CoT outputs routinely; instrument detectors for hallucinated citations or mismatched reasoning. OpenAI documents hallucinated chains of thought as an observed challenge and suggests mitigation strategies.
5) Build datasets from system operation
Log model decisions and human corrections to create labeled datasets that can improve triage classifiers or inform policy rewrites. Over time, a small, high-quality labeled dataset plus an efficient classifier often reduces reliance on full CoT inference for routine content.
6) Monitor compute & costs; employ asynchronous flows
For consumer-facing low-latency applications, consider asynchronous safety checks with a short-term conservative UX (e.g., temporarily hide content pending review) rather than performing high-effort CoT synchronously. OpenAI notes Safety Reasoner uses asynchronous flows internally to manage latency for production services.
7) Consider privacy and deployment location
Because weights are open, you can run inference wholly on-premises to comply with strict data governance or reduce exposure to third-party APIs—valuable for regulated industries.
Conclusion:
gpt-oss-safeguard is a practical, transparent, and flexible tool for policy-driven safety reasoning. It shines when you need auditable decisions tied to explicit policies, when your policies change frequently, or when you want to keep safety checks on-premises. It is not a silver bullet that will automatically replace specialized, high-volume classifiers—OpenAI’s own evaluations show that dedicated classifiers trained on large labeled corpora can outperform these models on raw accuracy for narrow tasks. Instead, treat gpt-oss-safeguard as a strategic component: the explainable reasoning engine at the heart of a layered safety architecture (fast triage → explainable reasoning → human oversight).
Getting Started
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
The latest integration gpt-oss-safeguard will soon appear on CometAPI, so stay tuned!While we finalize gpt-oss-safeguard Model upload, developers can access GPT-OSS-20B API and GPT-OSS-120B API through CometAPI, the latest model version is always updated with the official website. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!