

The rapid evolution of large language models (LLMs) has ushered in a new era of AI-driven productivity, with xAI’s Grok 4 and Anthropic’s Claude Opus 4 standing out as two of the most advanced offerings on the market. Both models promise to push the boundaries of reasoning, multimodal understanding, and real‐time data integration, yet they differ significantly in design choices, deployment strategies, and ethical safeguards. In this comprehensive analysis, we juxtapose Grok 4 and Claude Opus 4 across multiple dimensions—including their releases, architectures, performance benchmarks, real‐world applications, pricing models—to help organizations and developers make informed decisions.
What is Grok 4 and what are its key innovations?
Grok 4 is the fourth major iteration of xAI’s chatbot suite, officially launched on July 9, 2025. It introduces native tool use and real‑time search integration, positioning it as a versatile assistant capable of dynamic information retrieval and execution of external APIs. Available to SuperGrok and Premium+ subscribers as well as via the xAI API, Grok 4 also debuted a “Heavy” tier—Grok 4 Heavy—which runs on xAI’s Colossus supercomputer for enhanced performance and capacity.
Availability and deployment
Grok 4 is accessible via several tiers: SuperGrok and Premium+ subscribers receive priority access, while a new SuperGrok Heavy subscription at $300/month unlocks Grok 4 Heavy—an even more powerful variant optimized for latency‑sensitive or compute‑intensive workloads . Additionally, organizations can integrate Grok 4 via the xAI API, which supports RESTful calls and token‑based authentication for enterprise deployment.
How does Claude Opus 4 differentiate itself from previous Claude models?
Anthropic unveiled the Claude 4 series on May 22–23, 2025, comprising two variants: Claude Opus 4, the most powerful model optimized for complex coding and reasoning tasks, and Claude Sonnet 4, a leaner version tailored for everyday conversational use. Claude 4 introduces “extended thinking,” a paradigm enabling the model to call external tools mid‑conversation—such as web search, API calls, and code execution—thus functioning as an autonomous research assistant when enabled.
Anthropic’s Claude Opus 4 represents a significant leap over Claude 3.7 and Sonnet 4, focusing on long‑duration coherence, enhanced reasoning, and agentic capabilities.
Performance improvements
In benchmark tests, Opus 4 sustained coherent reasoning for up to seven hours on continuous, multi‑step tasks—far outpacing earlier models that typically degrade after minutes of context accumulation . Anthropic’s internal evaluations also show that Opus 4 outperforms competitors like Google’s Gemini 2.5 Pro and OpenAI’s GPT‑4.1 on complex coding challenges and multi‑agent simulations .
New features: extended thinking and tool use
Two flagship innovations in Opus 4 are Thinking Summaries—condensed synopses of the model’s reasoning chain—and Extended Thinking, a beta mode that toggles between pure reasoning and tool‑augmented workflows (e.g., calling external APIs, database queries) to optimize accuracy and efficiency. These allow developers to both inspect the model’s internal logic and seamlessly orchestrate multi‑step processes without manual intervention .
How do Grok 4 and Claude 4 compare in architecture and capabilities?
Model Architecture and Reasoning
Grok 4 employs a transformer backbone fine‐tuned with proprietary techniques to enhance logical reasoning and context retention across very long inputs. xAI claims a 256,000‑token context window, a substantial leap over prior models, enabling Grok 4 to handle entire books or long codebases in a single pass . Claude 4, by contrast, builds on Anthropic’s hybrid reasoning framework, which interleaves generative steps with internal chain‐of‐thought reasoning modules. Both Opus and Sonnet variants share the core extended thinking framework, but Opus 4 is scaled for maximum parameter counts and throughput, while Sonnet 4 balances performance with efficiency.
Context Window and Multimodality
While both models support multimodal inputs, their emphases differ. Grok 4’s enormous context window caters to large‐scale document analysis and long conversational threads, whereas Claude 4 focuses on modular reasoning with the ability to ingest documents, web data, and user files through its Files API. Both systems offer vision capabilities; Grok 4 integrates real‐time image understanding via X’s data stream, and Claude 4 ties into Google Workspace and web search for real‐time context enrichment .
What Tool‑Use Features Do They Offer?
Claude 4: “Extended thinking” allows sequential tool chaining—search, calculation, code exec—within one coherent workflow, easing complex multi‑step tasks without context loss .
Grok 4: Features real‑time web search and API calling via native tools; integrates with X’s ecosystem for on‑platform data retrieval.
How do Grok 4 and Claude Opus 4 compare in performance ?
While both models champion advanced reasoning, their design emphases lead to different sweet spots.
Benchmarks and coding prowess
- Coding tasks: Claude Opus 4 is marketed as “the world’s best coding model,” achieving up to 25–30% higher pass‑rates on coding benchmarks compared to GPT‑4 and rival models . Grok 4, although proficient, shows slightly lower code synthesis scores but compensates with its real‑time search integration for code snippets and libraries.
- Reasoning: In logical puzzles and step‑by‑step math problems, both models perform robustly, but Anthropic’s extended context window gives Opus 4 an edge in problems requiring sustained, layered reasoning over hundreds of tokens .with lower hallucination rates in math and logic problems.
- Grok 4 Code, launched alongside, excels in hard reasoning and debugging; theoretical SWE‑Bench suggests 75 % vs Opus’s ~72 % .
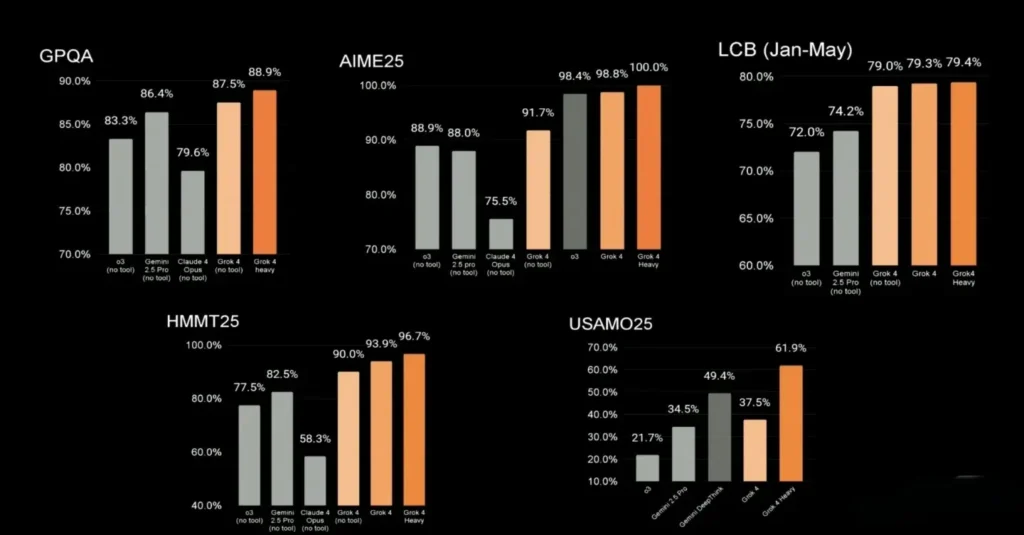
Agentic workflows and long‑term tasks
Grok 4’s native function calling enables on‑the‑fly API execution (e.g., booking tools, scheduling), making it a strong candidate for interactive agents . In contrast, Claude Opus 4 excels in autonomous, continuous workflows—such as monitoring data streams, updating reports, or orchestrating multi‑agent simulations—running reliably for several hours without context drift.
Inference & Throughput
- Grok 4: ~75 tokens/s, with latency ~5.7 s.
- Claude Opus 4 (GPT‑4o comparator): ~138 tokens/s, latency ~0.43 s.
What are pricing and access options?
How much does Grok 4 cost?
- Standard Grok‑4 – $30/month,$300 annually: Access to core model, basic multimodal input, and live search.SuperGrok () includes Grok 4 with increased access and 128,000 context memory tokens.
- SuperGrok Heavy – $300/month,$3,000 annually: Multiple agent instances, advanced research tools, priority support, and early feature access .SuperGrok Heavy offers exclusive Grok 4 Heavy preview access with dedicated support and early feature access.
- API Access (pay‑as‑you‑go): The API pricing model charges $3.00 per 1M input tokens and $15.00 per 1M output tokens, with cached input tokens offering significant cost savings at $0.75 per 1M tokens.
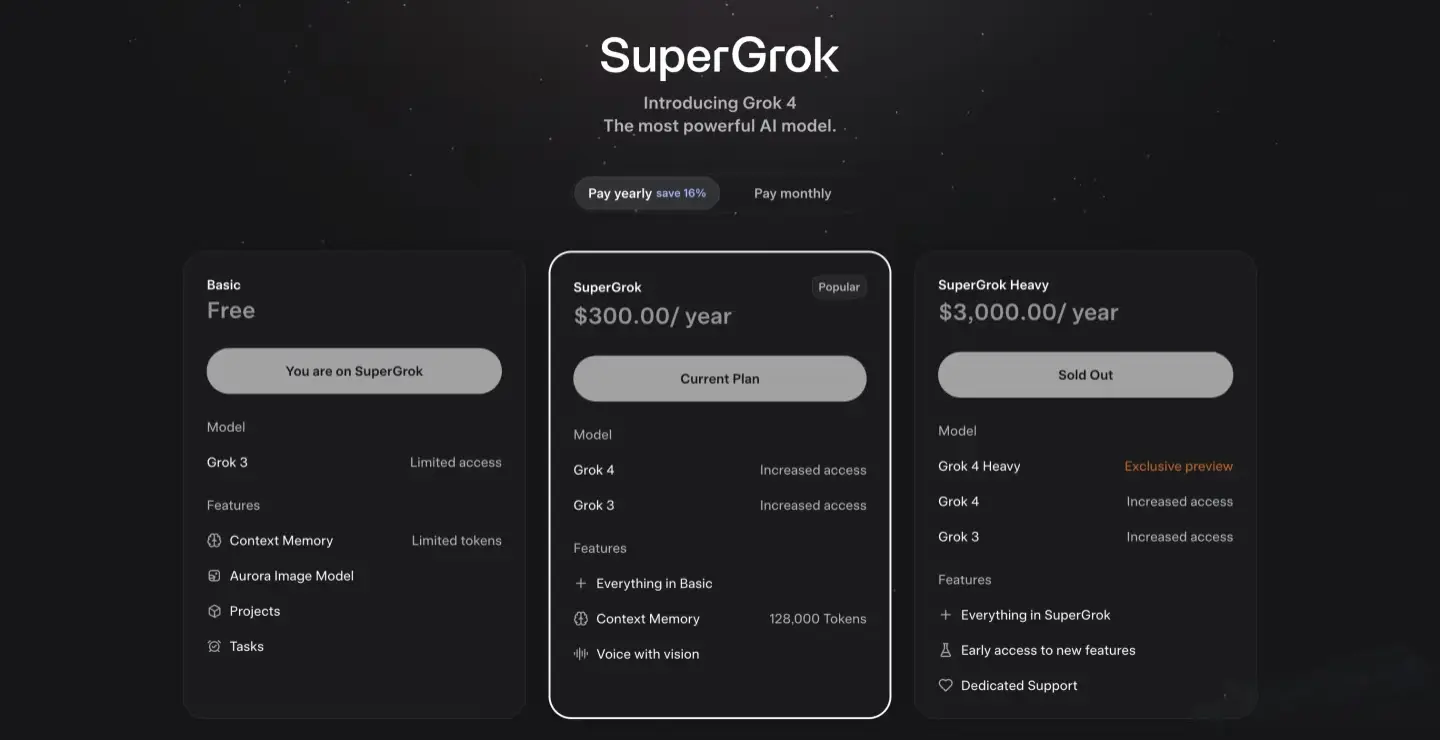
How much does Claude Opus 4 cost?
Pro, Max, Team, Enterprise: $20–$200 /month, unlocking Sonnet 4 and Opus 4, plus extended thinking in beta for higher plans .Anthropic’s Claude Opus 4 is priced based on the number of tokens processed. Billing is divided into input tokens (what you send to the model) and output tokens (what the model returns):
- Input tokens — $15 per 1 million tokens
- Output tokens — $75 per 1 million tokens
Cost‑saving features:
- Prompt caching — Re‑use cached outputs for identical prompts within a one‑hour window, yielding up to 90 % savings on repeated requests.
- Batch processing — Submit multiple inputs in a single call, reducing overhead and cutting costs by up to 50 %.
Side-by-Side Comparison Table
| Feature | Grok 4 (xAI) | Claude Opus 4 (Anthropic) |
|---|---|---|
| Release Date | July 9, 2025 | May 22, 2025 |
| Context Window | 256k tokens | 200k tokens |
| Academic Benchmarks | Top-tier (45 %+ HLE; 16 % ARC) | Strong, but behind |
| Coding Ability | ~75 % SWE‑Bench; “Code” mode | ~75 %+ HumanEval; widely acclaimed |
| Inference Speed | ~75 tokens/s; 5.7 s latency | ~138 tokens/s; ~0.43 s latency |
| Pricing | $30 basic, $300 Heavy/month | Premium API, varied pricing |
| Safety & Ethics | Emerging-but-miss moderations | ASL‑3 safety, strict filters |
| Multimodal & Memories | Image input now; video soon | Multimodal + memory and tool use enabled |
Choosing the Right Model: Use‑Case Guide
1. For raw academic research & ultra‑hard reasoning
Choose Grok 4 Heavy: top benchmark accuracy, largest context.
2. For professional software development and coding
Go with Claude Opus 4: market‑leading accuracy, longer context reliability, faster throughput.
3. For general multimodal tasks with memory and compliance
Claude Opus 4 wins with mature tooling and safeguards.
4. For real‑time search, creativity, and systems that favor flexibility
Grok 4 appeals to developers desiring less-filtered access and emergent agentic behavior.
Getting Started
CometAPI provides a unified REST interface that aggregates hundreds of AI models—under a consistent endpoint, with built-in API-key management, usage quotas, and billing dashboards. Instead of juggling multiple vendor URLs and credentials.
Developers can access Grok 4 API and Claude Opus 4 API through CometAPI, the latest models version listed are as of the article’s publication date. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
In summary
Grok 4 and Claude Opus 4 each push the boundaries of large language modeling through divergent philosophies: Grok prioritizes transparency and real‑time agility, while Claude emphasizes coding excellence and preventive safety. Selecting between them hinges on your organization’s appetite for live data integration, tolerance for tooling risk, and need for rigorous ethical safeguards. As both platforms mature, cross‑model benchmarks and interoperability—such as leveraging Claude connectors alongside Grok’s search—may further blur these distinctions, ushering in an era of hybrid AI solutions.