

Claude Opus 4.5 is Anthropic’s newest “Opus-class” model (released in late November 2025). It’s positioned as a top-tier model for professional software engineering, long-horizon agentic workflows, and high-stakes enterprise tasks, and Anthropic intentionally priced it to make high capability more accessible to production users. Below I unpack what the Claude Opus 4.5 API is, how the model performs on real engineering benchmarks, exactly how its pricing works (API and subscription), how that compares to legacy Anthropic models and competitors (OpenAI, Google Gemini), and practical best practices for running production workloads cost-efficiently. I also include supporting code and a small benchmarking & cost-calculation toolkit you can copy and run.
What is the Claude Opus 4.5 API?
Claude Opus 4.5 is the newest Opus-class model: a high-capability, multimodal model tuned specifically for professional software engineering, agentic tool use (i.e., calling and composing external tools), and computer-use tasks. It retains extended-thinking capabilities (transparent step-by-step internal reasoning you can stream) and adds fine-grained runtime controls (notably the effort parameter). Anthropic positions this model as suitable for production agents, code migration / refactor, and enterprise workflows that require robustness and lower iteration counts.
Core API capabilities and developer UX
Opus 4.5 supports:
- Standard text generation + high fidelity instruction following.
- Extended Thinking / multi-step reasoning modes (useful for coding, long documents).
- Tool use (web search, code execution, custom tools), memory and prompt caching.
- “Claude Code” and agentic flows (automating multi-step tasks across codebases).
How does Claude Opus 4.5 perform?
Opus 4.5 is state-of-the-art on software engineering benchmarks — claiming ~80.9% on SWE-bench Verified, and strong scores on “computer-use” benchmarks like OSWorld as well. Opus 4.5 can match or exceed Sonnet 4.5 performance at lower token usage (i.e., more token efficient).
Software-engineering benchmarks (SWE-bench / Terminal Bench / Aider Polyglot): Anthropic reports Opus 4.5 leads on SWE-bench Verified, improves Terminal Bench by ~15% vs Sonnet 4.5, and shows a 10.6% jump on Aider Polyglot vs Sonnet 4.5 (their internal comparisons).
Long-run, autonomous coding: Anthropic: Opus 4.5 keeps performance stable in 30-minute autonomous coding sessions and shows fewer dead-ends in multi-step workflows. This is a repeated internal finding across their agent tests.
Real-world task improvements (Vending-Bench / BrowseComp-Plus etc.): Anthropic cites +29% on Vending-Bench (long-horizon tasks) vs Sonnet 4.5 and improved agentic search metrics on BrowseComp-Plus.
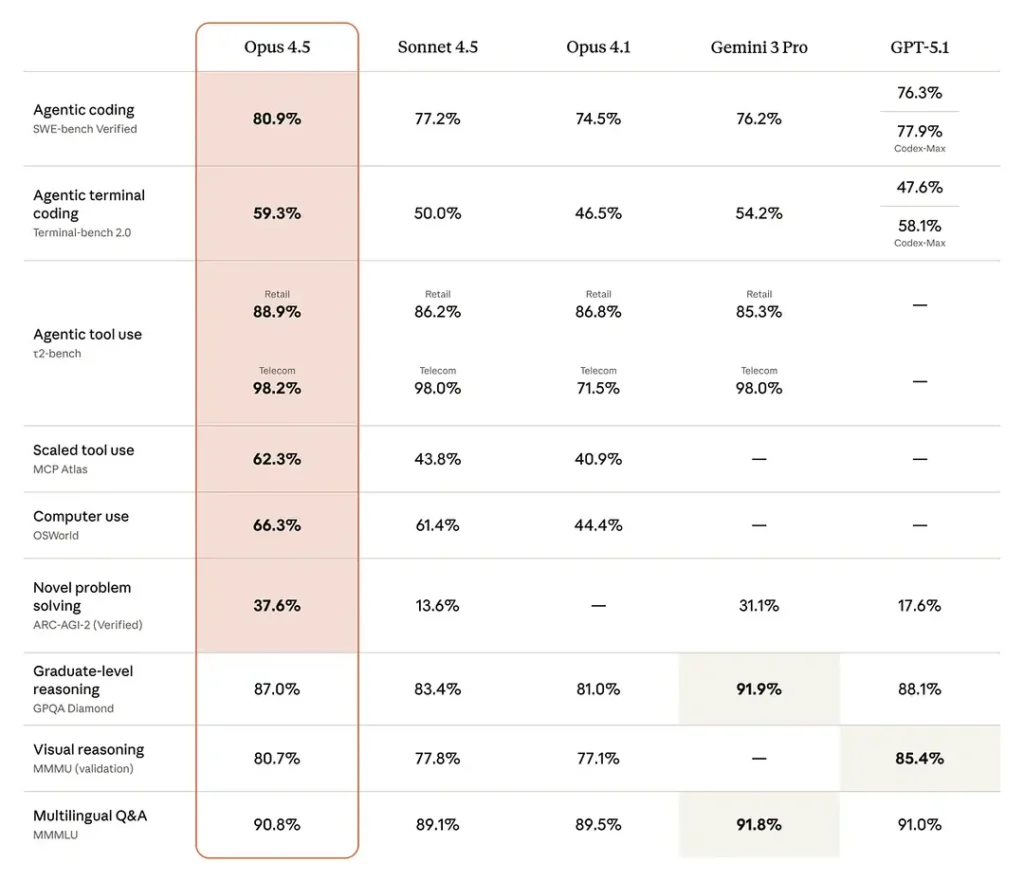
A few concrete takeaways from the reporting:
- Coding leadership: Opus 4.5 often beats previous Opus/Sonnet variants and many contemporaneous competitor models on software engineering benchmark aggregates (SWE-bench Verified and Terminal-bench variants).
- Office automation: reviewers highlight better spreadsheet generation and PowerPoint production — improvements that reduce post-edit work for analysts and product teams.
- Agent & tool reliability: Opus 4.5 improves in multi-step agentic workflows and long-running tasks, reducing failures in multi-call pipelines.
How Much Does Claude Opus 4.5 Cost?
This is the central question you asked. Below I break it down by API pricing structure, subscription tiers, example cost calculations, and what that means in practice.
API Pricing Structure — what Anthropic published
Anthropic for Opus 4.5 set the model’s API price at:
- Input (tokens): $5 per 1,000,000 input tokens
- Output (tokens): $25 per 1,000,000 output tokens
Anthropic explicitly framed this price as a deliberate reduction to make Opus-class performance broadly accessible. The model identifier for developers is the claude-opus-4-5-20251101 string .
In CometAPI, Claude Opus 4.5 API is $4 / 1M input tokens and $20 / 1M output tokens for Opus 4.5, about 20% cheaper than the official Google price.
Pricing table (simplified, USD per million tokens)
| Model | Input ($ / MTok) | Output ($ / MTok) | Notes |
|---|---|---|---|
| Claude Opus 4.5 (base) | $5.00 | $25.00 | Anthropic list price. |
| Claude Opus 4.1 | $15.00 | $75.00 | Older Opus release — higher list prices. |
| Claude Sonnet 4.5 | $3.00 | $15.00 | Cheaper family for many tasks. |
Important note: these are token-based prices (not per-request). You are billed on tokens consumed by your requests — both input (prompt + context) and output (model tokens generated).
Subscription plans and app tiers (consumer/Pro/Team)
The API is well-suited for custom builds, while Claude’s subscription plan bundles Opus 4.5 access with the UI tools, eliminating concerns about per-to-per-token usage in interactive scenarios. The free plan ($0) is limited to basic chat and the Haiku/Sonnet model and does not include Opus.
The Pro plan ($20 per month or $17 per year) and the Max plan ($100 per person per month, providing 5 to 20 times the Pro usage) unlock Opus 4.5, Claude Code, file execution, and unlimited projects.
How do I optimize token usage?
- Use
effortappropriately: chooselowfor routine answers,highonly when necessary. - Prefer structured outputs & schemas to avoid verbose back-and-forth.
- Use the Files API to avoid re-sending large documents in the prompt.
- Compact or summarize context programmatically before sending it.
- Cache repeated responses and reuse them when prompt inputs are identical or similar.
Practical rule: instrument usage early (track tokens per request), run load tests with representative prompts, and compute cost per successful task (not cost per token) so optimizations target real ROI.
Quick sample code: call Claude Opus 4.5 + compute cost
Below are copy-ready examples: (1) curl, (2) Python using Anthropic’s SDK, and (3) a small Python helper that computes cost given measured input/output tokens.
Important: store your API key securely in an environment variable. The snippets assume
ANTHROPIC_API_KEYis set. The model id shown isclaude-opus-4-5-20251101(Anthropic).
1) cURL example (simple prompt)
curl https://api.anthropic.com/v1/complete \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model":"claude-opus-4-5-20251101",
"prompt":"You are an assistant. Given the following requirements produce a minimal Python function that validates emails. Return only code.",
"max_tokens": 600,
"temperature": 0.0
}'
2) Python (anthropic SDK) — basic request
# pip install anthropic
import os
from anthropic import Anthropic, HUMAN_PROMPT, AI_PROMPT
client = Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
prompt = HUMAN_PROMPT + "Given the following requirements produce a minimal Python function that validates emails. Return only code.\n\nRequirements:\n- Python 3.10\n- Use regex\n" + AI_PROMPT
resp = client.completions.create(
model="claude-opus-4-5-20251101",
prompt=prompt,
max_tokens_to_sample=600,
temperature=0.0
)
print(resp.completion) # model output
Note: Anthropic’s Python SDK names and call signatures can vary; the above follows common patterns in their public SDK and docs — check your installed version docs for exact method names. GitHub+1
3) Cost calculator (Python) — compute cost from tokens
def compute_claude_cost(input_tokens, output_tokens,
input_price_per_m=5.0, output_price_per_m=25.0):
"""
Compute USD cost for Anthropic Opus 4.5 given token counts.
input_price_per_m and output_price_per_m are dollars per 1,000,000 tokens.
"""
cost_input = (input_tokens / 1_000_000) * input_price_per_m
cost_output = (output_tokens / 1_000_000) * output_price_per_m
return cost_input + cost_output
# Example: 20k input tokens and 5k output tokens
print(compute_claude_cost(20000, 5000)) # => ~0.225 USD
Tip: measure tokens for real requests using server logs / provider telemetry. If you need exact tokenization counts locally, use a tokenizer compatible with Claude’s tokenization scheme or rely on the provider’s token counters when available.
When should you choose Opus 4.5 vs cheaper models?
Use Opus 4.5 when:
- You have mission-critical engineering workloads where correctness on first pass is materially valuable (complex code generation, architecture suggestions, long agentic runs).
- Your tasks need tool orchestration or deep multi-step reasoning within a single workflow. Programmatic tool calling is a key differentiator.
- You are trying to reduce human review loops — the model’s higher first-pass accuracy can reduce downstream human time and thus total cost.
Consider Sonnet / Haiku or competitor models when:
- Your use case is chatty, high-volume, low-risk summarization where cheaper tokens and higher throughput matter. Sonnet (balanced) or Haiku (lightweight) can be more cost-effective.
- You need the absolute cheapest per-token processing and are willing to trade some capability/accuracy (e.g., simple summarization, basic assistants).
How should I design prompts for Opus 4.5?
What message roles and prefill strategies work best?
Use a three-part pattern:
- System (role: system): global instructions — tone, guardrails, role.
- Assistant (optional): canned examples or priming content.
- User (role: user): the immediate request.
Prefill the system message with constraints (format, length, safety policy, JSON schema if you want structured output). For agents, include tool specifications and usage examples so Opus 4.5 can call those tools correctly.
How do I use context compaction and prompt caching to save tokens?
- Context compaction: compress older parts of a conversation into concise summaries the model can still use. Opus 4.5 supports automation to compact context without losing critical reasoning blocks.
- Prompt caching: cache model responses for repeated prompts (Anthropic provides prompt caching patterns to reduce latency/cost).
Both features reduce the token footprint of long interactions and are recommended for long-running agent workflows and production assistants.
Best Practices: Getting Opus-level results while controlling cost
1) Optimize prompts and context
- Minimize extraneous context — send only the necessary history. Trim and summarize earlier conversation when you expect long back-and-forth.
- Use retrieval/embedding + RAG to fetch only the documents needed for a specific query (instead of sending entire corpora as prompt tokens). Anthropic’s docs recommend RAG and prompt caching to reduce token spend.
2) Cache and reuse responses where possible
Prompt caching: If many requests have identical or near-identical prompts, cache outputs and serve cached versions rather than re-call the model every time. Anthropic documents specifically call out prompt caching as a cost optimization.
3) Choose the right model for the job
- Use Opus 4.5 for business-critical, high-value tasks where human rework is expensive.
- Use Sonnet 4.5 or Haiku 4.5 for high-volume, lower-risk tasks. This mixed-model strategy yields better price/performance across the stack.
4) Control max tokens and streaming
Limit max_tokens_to_sample for outputs when you don’t need full verbosity. Use streaming where supported to stop generation early and save output token costs.
Final thoughts: is Opus 4.5 worth adopting now?
Opus 4.5 is a meaningful step forward for organizations that need higher-fidelity reasoning, lower token costs for long interactions, and safer, more robust agent behavior. If your product relies on sustained reasoning (complex code tasks, autonomous agents, deep research synthesis, or heavy Excel automation), Opus 4.5 gives you additional knobs (effort, extended thinking, improved tool handling) to tune for real-world performance and cost.
Developers can access Claude Opus 4.5 API through CometAPI. To begin, explore the model capabilities ofCometAPI in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!