

Anthropic’s Claude Sonnet 4.5 (often shortened to Sonnet 4.5) arrived as a performance-focused successor in Anthropic’s Claude family. For teams deciding whether to adopt Claude Sonnet 4.5 for chatbots, code assistants, or long-running autonomous agents, cost is a top question — and it’s not just the sticker price per token that matters, but how you deploy the model, what savings features you use, and which competitor models you compare it to.
What is Claude Sonnet 4.5 and why use it?
Claude Sonnet 4.5 is Anthropic’s latest Sonnet-family flagship model optimized for long-horizon agentic workflows, coding, and complex multi-step reasoning. Anthropic positions Claude Sonnet 4.5 as a “frontier” model with a large context window and improvements in sustained task execution, code editing, and domain reasoning compared to prior Sonnet releases.
Notable technical and user-facing features
- Extended long-context performance — designed to maintain coherent work over many steps (Anthropic cites multi-hour continuous work use cases).
- Improved code editing and execution primitives — features for checkpoints, code execution in some integrations, and better edit accuracy compared with earlier Sonnet/Opu s models.
- Improved reasoning, coding, and agentic performance — Anthropic highlights longer continuous autonomous runs and more dependable behavior for multi-step workflows.
- Designed for long-context usage (Sonnet variants commonly target large context windows applicable to codebases and multi-document workflows), with system-level improvements and safety-focused guardrails.
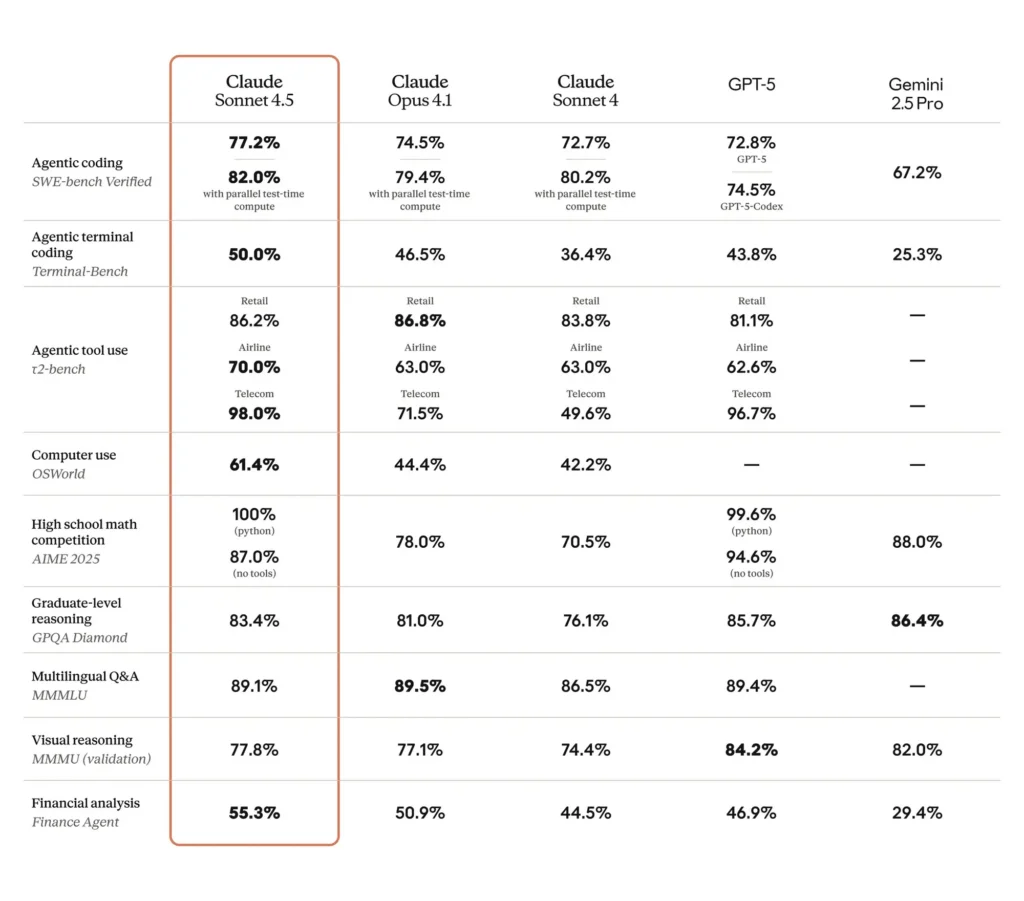
*Stronger “computer use” and coding performance
If your product or team needs one or more of the following, Claude Sonnet 4.5 is specifically designed to be compelling:
- Long, stateful agent runs (autonomous app builders, multi-hour code synthesis or automated testing).
- High-quality code editing and refactoring — Anthropic reports direct improvements in internal code-editing error rates vs previous Sonnet versions.
- Complex reasoning and domain work in finance, law, medicine and STEM where longer context and fewer “reminders” increases throughput and reduces manual orchestration.
What is the pricing for using Claude 4.5 via the Claude app?
What are the consumer subscription tiers (web/mobile)?
Anthropic’s consumer tiers still look like this (public pricing pages and back-end docs):
- Free — useful for casual use; limited message/usage throughput.
- Pro — $20/month billed monthly (discounted to roughly $17/month billed annually), intended for everyday power users and advanced productivity features. Pro increases session/usage limits (roughly ~5× Free during peak windows).
- Max plan — Anthropic announced higher-usage “Max” tiers ($100/month for ~5× Pro usage, $200/month for ~20× Pro usage) for power/professional users who need sustained heavy usage without enterprise procurement. These plans are explicitly targeted at people who would otherwise max out Pro’s session limits.
How many hours/messages does a subscription buy?
Pro users can expect something like ~45 messages per five hours or ~40–80 hours of Sonnet weekly use depending on workload; Max tiers scale this dramatically (Max 5× and 20× give proportionate increases). These are approximation bands—actual consumption depends on prompt length, attachment sizes, model choices (Sonnet vs Opus vs Haiku), and features like Claude Code.
What are the API pricing details for Claude Sonnet 4.5?
How is API billing measured?
Anthropic bills API usage by tokens and separates input tokens (what you send) from output tokens (what the model returns). For Claude Sonnet 4.5 Anthropic’s published baseline rates are:
- Input (standard API): $3.00 per 1,000,000 input tokens.
- Output (standard API): $15.00 per 1,000,000 output tokens.
What discounts or alternative modes exist?
- Batch API (asynchronous bulk processing) carries a ~50% discount in Anthropic docs — commonly represented as $1.50 / M input and $7.50 / M output for Sonnet models in batch mode. Batch is ideal for large offline workloads like codebase analysis or bulk summarization.
- Prompt caching can produce up to very large effective savings when repeatedly calling identical prompts. Use caching for repetitive assistant prompts or agent plans where the same seed prompt repeats.
- third-party channels: CometAPI offers a 20% discount on the official API, and has a specially adapted cursor API version: Input (prompt) tokens is $2.4 per 1,000,000 (1M) input tokens; Output (generation) tokens: $12 per 1,000,000 (1M) output tokens.
Note: “prompt caching” and “batch processing” are implementation patterns that reduce repeated compute on identical prompts and amortize work across multiple calls — how much they save depends entirely on your application’s workload patterns.
How do subscription and API options compare for cost?
It depends entirely on usage profile:
- For interactive human productivity (writing, research, occasional code assistance) the Pro or Max subscriptions often give the best cost/experience because they bundle capacity, app features, and higher session caps for a predictable monthly fee. Anthropic’s Pro is positioned for writers and small teams; Max targets professionals who need many more hours and prompts per month.
- For programmatic, high-volume, or per-transaction usage (webhooks, product features that call the model thousands/millions of times a day), API pay-as-you-go is usually the correct choice: cost scales with tokens, and you can use batch pricing and caching to reduce billable tokens.
Practical rule of thumb
If your expected monthly API bill (at $3/$15 per M) would be substantially more expensive than the Pro/Max slot you need (after converting your expected hours/messages to tokens), buy a subscription or an enterprise plan. Conversely, if your product needs fine-grained programmatic calls, API is the only practical option.
Claude Sonnet 4.5 — Estimated costs by application scenario
Below are practical, actionable monthly cost estimates for Claude Sonnet 4.5 across typical application scenarios (text generation, code, RAG, agents, long-document summarization, etc.). Each scenario shows the assumptions (tokens per call and calls/month), the base monthly cost using Anthropic’s published rates ($3 / 1M input tokens, $15 / 1M output tokens), and two common optimization views: a batch discount (50% off token rates) and prompt-caching examples (70% cache hit and 90% cache hit). These discounts/benefits are supported by Anthropic’s documentation (batch ≈ 50% and prompt caching up to ~90% savings).
What are the calculation rules and assumptions?
- 1,000,000 tokens is the billing unit.
- The monthly cost = (total_input_tokens / 1,000,000) × input_rate + (total_output_tokens / 1,000,000) × output_rate.
- I report three cost columns: Base, Batch (50% off rates), Caching (two representative cache-hit assumptions: 70% and 90% of calls served from cache).
- These are estimate models — actual bills will vary with cache-hit quality, exact prompt sizes, response lengths, and any negotiated discounts or partner/cloud margins.
Below are 9 scenarios. For each I list: calls/month, average input tokens (prompt / context) and average output tokens (model reply), then monthly totals and costs.
Token-to-word rough guide: 1,000 tokens ≈ 750–900 words depending on language and formatting.
1) Short-form content (blog outlines, social posts)
Assumptions: 1,000 calls/month; 200 input tokens / call; 1,200 output tokens / call.
Totals: 200,000 input tokens; 1,200,000 output tokens.
| Cost view | Monthly cost |
|---|---|
| Base (no discounts) | $18.60 |
| Batch (50% token-rate) | $9.30 |
| 70% cache hit (only 30% billed) | $5.58 |
| 90% cache hit (only 10% billed) | $1.86 |
When this fits: small creators and agencies generating many short pieces. Caching templated prompts (e.g., fixed outline templates) is high-impact.
2) Long-form article generation (multi-page outputs)
Assumptions: 200 calls/month; 500 input tokens; 5,000 output tokens.
Totals: 100,000 input tokens; 1,000,000 output tokens.
| Cost view | Monthly cost |
|---|---|
| Base | $15.30 |
| Batch | $7.65 |
| Cache 70% | $4.59 |
| Cache 90% | $1.53 |
When this fits: outlets producing long articles; use batch for scheduled bulk generation and cache for repeated templates. Because output tokens dominate here, Sonnet’s per-token output rate matters but these costs are modest for low-to-moderate article volumes. For high throughput (hundreds–thousands of long articles/month), batch + careful truncation still materially reduces cost.
3) Customer-support chatbot (mid-sized deployment)
Assumptions: 30,000 sessions/month; 600 input tokens; 800 output tokens.
Totals: 18,000,000 input tokens; 24,000,000 output tokens.
| Cost view | Monthly cost |
|---|---|
| Base | $387.00 |
| Batch | $193.50 |
| Cache 70% | $116.10 |
| Cache 90% | $38.70 |
When this fits: conversational support for medium apps—RAG/knowledge retrieval plus caching canned answers drastically reduces cost. For chatbots, output tokens usually drive cost. Reducing verbosity (targeted answers) and using streaming/early-stop helps. Caching helps only if the same prompts are repeated.
4) Code assistant (IDE integrations, editing & fixes)
Assumptions: 10,000 calls/month; 1,200 input tokens; 800 output tokens.
Totals: 12,000,000 input tokens; 8,000,000 output tokens.
| Cost view | Monthly cost |
|---|---|
| Base | $258.00 |
| Batch | $129.00 |
| Cache 70% | $77.40 |
| Cache 90% | $25.80 |
When this fits: per-edit assistance inside an IDE. Consider routing lint/format tasks to lighter models and escalating to Claude Sonnet 4.5 for higher-value code edits. Reuse system prompts and templates with caching when calling similar code-generation prompts to reduce input costs.
5) Document summarization — long documents (legal / finance)
Assumptions: 200 calls/month; 150,000 input tokens (large doc/chunking included); 5,000 output tokens.
Totals: 30,000,000 input tokens; 1,000,000 output tokens.
| Cost view | Monthly cost |
|---|---|
| Base (≤200k input → standard rates) | $615.00 |
| Batch | $307.50 |
| Cache 70% | $184.50 |
| Cache 90% | $61.50 |
Important: this example keeps per-call input ≤200k so standard rates apply. If your per-call input exceeds 200k tokens, long-context pricing applies (see next scenario).
6) Ultra long-document review ( >200k tokens per request → long-context rates)
Assumptions: 20 calls/month; 600,000 input tokens / call; 20,000 output tokens / call.
Totals: 12,000,000 input tokens; 400,000 output tokens.
Because input per request > 200k, Anthropic’s long-context premium rates apply (example: $6 / 1M input and $22.50 / 1M output used here).
| Cost view (long-context rates) | Monthly cost |
|---|---|
| Long-context base | $81.00 |
| (For comparison at standard rates if long context not charged) | $42.00 |
When this fits: single-call analysis of extremely large evidence sets or books. Use chunking + retrieval and RAG to avoid premium per-call long-context charges when possible.
7) RAG / enterprise Q&A (very high QPS)
Assumptions: 1,000,000 calls/month; 400 input tokens; 200 output tokens.
Totals: 400,000,000 input tokens; 200,000,000 output tokens.
| Cost view | Monthly cost |
|---|---|
| Base | $3,300.00 |
| Batch | $1,650.00 |
| Cache 70% | $990.00 |
| Cache 90% | $330.00 |
When this fits: high-volume document QA. RAG + prefiltering + local caches dramatically reduce calls that must hit Claude Sonnet 4.5.
8) Agentic automation (continuous agents, many turns)
Assumptions: 50,000 agent sessions/month; 2,000 input tokens; 4,000 output tokens.
Totals: 100,000,000 input tokens; 200,000,000 output tokens.
| Cost view | Monthly cost |
|---|---|
| Base | $3,300.00 |
| Batch | $1,650.00 |
| Cache 70% | $990.00 |
| Cache 90% | $330.00 |
When this fits: background agents that run many steps. Architecture matters: compress state, summarize history, and cache repeated sub-prompts to control costs.
9) Batch translation (large batch jobs)
Assumptions: 500 batch jobs/month; 50,000 input tokens; 50,000 output tokens.
Totals: 25,000,000 input tokens; 25,000,000 output tokens.
| Cost view | Monthly cost |
|---|---|
| Base | $450.00 |
| Batch | $225.00 |
| Cache 70% | $135.00 |
| Cache 90% | $45.00 |
When this fits: scheduled bulk processing — batch API is the single biggest lever here.
How does Claude Sonnet 4.5’s price compare with other mainstream models?
Token-price comparison (simple view)
- Claude Sonnet 4.5: $3 / 1M input, $15 / 1M output (standard API).
- OpenAI GPT-4o (examples reported): approx $2.50 / 1M input, $10 / 1M output.
- OpenAI GPT-5 (example public pricing for its flagship): approx $1.25 / 1M input, $10 / 1M output (OpenAI’s published API pricing when GPT-5 launched).
Interpretation: Sonnet’s output cost is materially higher than some OpenAI flagship output prices, but Sonnet aims to offset that with better agentic efficiency (fewer back-and-forth steps because it can hold longer context and do more internally), and Anthropic’s caching/batch options can bring effective costs down significantly for repeated prompts.
Capability-per-dollar matters
If Claude Sonnet 4.5 can finish a multi-hour agent task in fewer API calls or generate more compact, correct outputs that don’t need post-processing, the real cost (engineering hours + API fees) may be lower despite a higher per-token output rate. Benchmark costs should be computed per workflow, not per token alone.
What cost-optimization strategies work best with Claude Sonnet 4.5?
1) Exploit prompt caching aggressively
Anthropic advertises up to 90% savings for repeated prompts. If your app often sends the same system prompts or repeated instruction scaffolding, caching dramatically reduces token processing. Implement caching layers in front of the API to avoid re-sending unchanged prompts. ()
2) Batch requests where possible
For data-processing or multi-item inference, batch multiple items in one API call. Anthropic and other vendors report substantial savings for batch modes — the exact savings depend on how the vendor charges batched compute. ()
3) Reduce output token volume proactively
- Use stricter maximum-token settings and instruct models to be concise where acceptable.
- For UI flows, send partial responses or summaries rather than full verbose outputs. Because Sonnet’s output price is the larger cost contributor, trimming generated tokens yields outsized savings.
4) Model selection and routing
- Route low-value or extraction tasks to cheaper models (or smaller Claude variants) and reserve Sonnet 4.5 for mission-critical code/agent work.
- Evaluate smaller “mini” variants or older Claude models for background tasks.
5) Cache generated outputs for repeated queries
If users frequently request the same answer (e.g., product descriptions, policy snippets), cache the model’s output and serve cached responses instead of re-generating.
6) Use embeddings + retrieval to reduce prompt size
Store long documents in a vector DB and retrieve only the most relevant snippets to include in prompts — this reduces input tokens and keeps context tight.
How to call Claude Sonnet API more cheaply?
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
Developers can access Claude Sonnet 4.5 API through CometAPI, the latest model version is always updated with the official website. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
Conclusion
Claude Sonnet 4.5 is a high-capability model positioned for long, agentic, and coding tasks. Anthropic’s published API list price for Sonnet 4.5 is approximately $3 per million input tokens and $15 per million output tokens, with batch and caching mechanisms that often cut effective costs by half or more for the right workload. Subscription tiers (Pro, Max) and enterprise deals provide alternative ways to buy capacity for interactive or very heavy human workloads. When planning adoption, measure tokens per workflow, pilot Sonnet on your hardest flows, and use prompt caching, batch processing and model selection to optimize cost-effectiveness.