

China’s Z.ai (formerly Zhipu AI) has once again seized headlines with the launch of its open‑source GLM 4.5 Series. Positioned as a cost‑efficient, high‑performance alternative to existing large language models, GLM‑4.5 promises to reshape token‑economics and democratize access for startups, enterprises, and research institutions alike. this comprehensive article explores the GLM‑4.5 Series’s origins, pricing structure, and real‑world value—addressing the two key questions on every stakeholder’s mind: how much does it cost, and is it worth it?
What is the GLM 4.5 Series?
Z.ai’s GLM 4.5 Series is built on an “agentic” AI framework, meaning the model can autonomously decompose complex tasks into smaller, sequential sub‑tasks—enhancing precision and reducing redundant computation. This stands in contrast to more monolithic LLMs that handle prompts in a single pass. According to Z.ai, GLM 4.5 natively embeds reasoning and action planning within its core architecture, enabling multi‑step workflows such as data visualization generation or end‑to‑end document processing without external orchestration.
The GLM 4.5 Series, developed by Z.ai, represents the latest generation of open‑source, Mixture‑of‑Experts (MoE) large language models designed to unify advanced reasoning, code generation, and agentic capabilities within a single architecture. It comes in two main flavors: the flagship GLM 4.5 (355 B total parameters, 32 B active) and the lighter GLM 4.5‑Air (106 B total, 12 B active). Both variants leverage a hybrid inference mechanism—“thinking mode” for complex, tool‑enabled reasoning and “non‑thinking mode” for rapid, straightforward completions—catering to a broad spectrum of use cases from full‑stack development to autonomous agent workflows .
core technical specifications:
- Parameters: GLM 4.5 features 355 billion parameters, with an active subset of 32 billion engaged per inference to optimize hardware usage and throughput.
- Mixture-of-Experts (MoE): The Series leverages MoE architecture, routing tokens to expert sub-networks dynamically for efficiency.
- Context Window: Extended to 128 K tokens on select platforms (e.g., SiliconFlow), accommodating large documents and codebases .
- Generation Speed: High‑speed variants exceed 100 tokens/sec, suitable for real‑time applications .
- Hybrid Inference Modes: Users can toggle between “thinking” mode (full MoE activation for deep reasoning) and “non‑thinking” mode (minimal activation for rapid, on‑the‑fly responses), granting developers fine‑grained control over performance versus speed.
What variants exist within the Series?
- GLM 4.5 (Standard): 355 B total / 32 B active parameters. Primarily designed for balanced performance across reasoning, coding, and agentic tasks.
- GLM 4.5‑Air: A lightweight 106 B total / 12 B active parameter version, tailored for scenarios with stringent hardware or latency constraints—delivering competitive accuracy in its class .
How much does the GLM 4.5 Series cost?
What are the input and output token prices?
According to Z.ai’s public API pricing disclosures, GLM 4.5 is priced at:
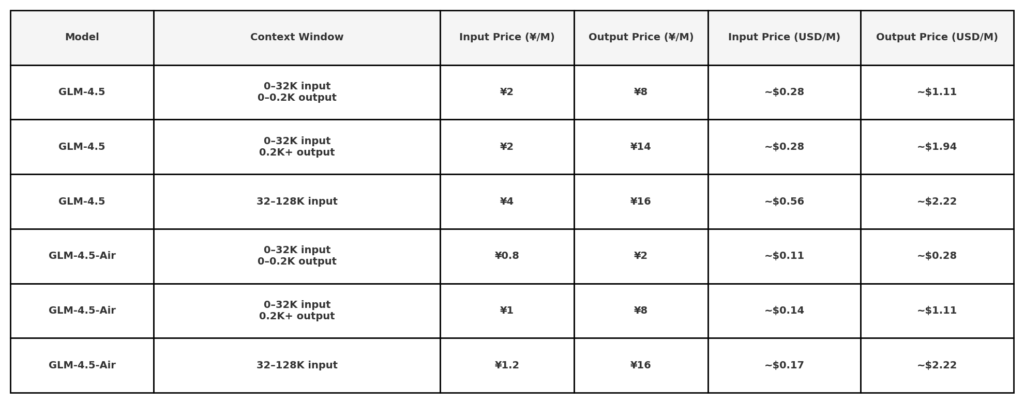
Note: very low rates ($0.11/$0.28) may be limited to small token lengths or specific promotions. 50% off all models for a limited time, valid until August 31, 2025. other model refer to office price page.
On the CometAPI, the Series is bundled with slightly different tiered pricing,refer to GLM‑4.5 API:
| Model | introduce | Price |
glm-4.5 | Our most powerful reasoning model, with 355 billion parameters | Input Tokens $0.48 Output Tokens $1.92 |
glm-4.5-air | Cost-Effective Lightweight Strong Performance | Input Tokens $0.16 Output Tokens $1.07 |
glm-4.5-x | High Performance Strong Reasoning Ultra-Fast Response | Input Tokens $1.60 Output Tokens $6.40 |
glm-4.5-airx | Lightweight Strong Performance Ultra-Fast Response | Input Tokens $0.02 Output Tokens $0.06 |
glm-4.5-flash | Strong Performance Excellent for Reasoning Coding & Agents | Input Tokens $3.20 Output Tokens $12.80 |
How does GLM 4.5 pricing compare to DeepSeek and Western LLMs?
At the 2025 World AI Conference, Z.ai explicitly positioned GLM 4.5 as a challenger to DeepSeek—the prior cost‑leader in China—promising “a fraction of the token cost” and half the hardware footprint of DeepSeek’s R1 model .
- DeepSeek R1: Approximately USD 0.14 input, USD 0.60 output per million tokens.
- GLM 4.5: Claimed to undercut DeepSeek by 20–30% on both input and output.
- Western Benchmarks: OpenAI’s GPT‑4 and Google’s Gemini range from USD 3–15 per million tokens, positioning GLM 4.5 as an order‑of‑magnitude cost reduction .
This pricing strategy reflects China’s broader AI economic model: leaner compute, smaller models, and aggressive undercutting to capture market share.
Are the GLM 4.5 Series Worth It?
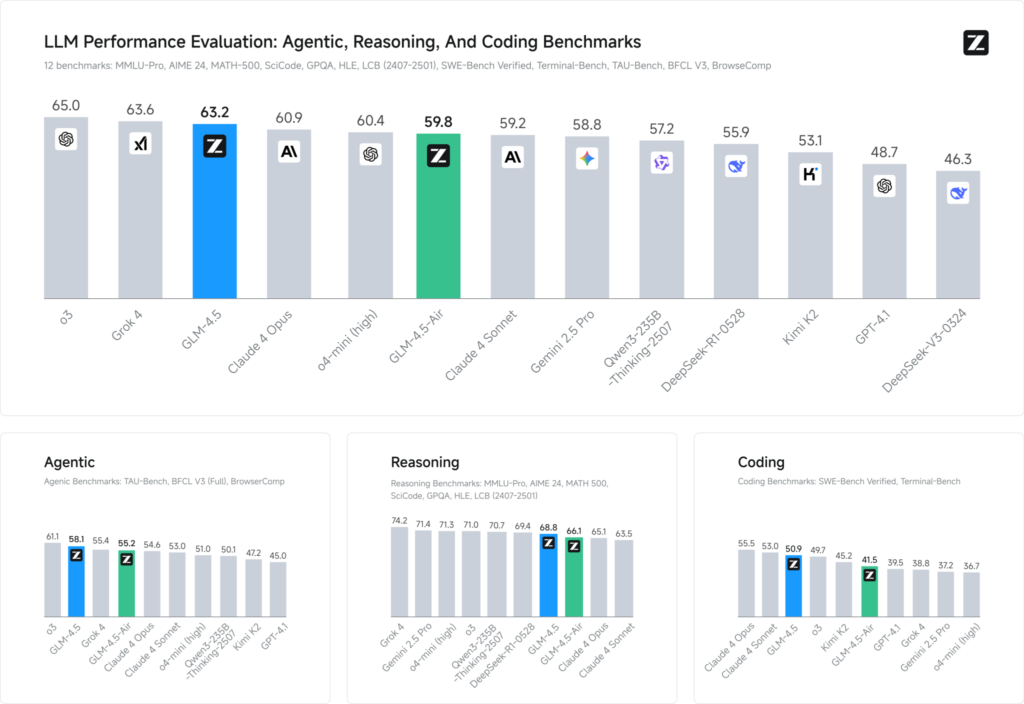
Benchmark evaluations across 12 representative datasets (spanning MMLU Pro, MATH 500, SciCode, Terminal‑Bench, and TAU‑Bench) reveal that GLM 4.5 secures a global #3 ranking behind xAI’s Grok 4 and OpenAI’s o3—yet ranks #1 among open‑source offerings .
In coding tasks (LiveCodeBench, SWE‑Bench), GLM 4.5’s Mixture‑of‑Experts design contributes to top‑tier code generation quality, while in reasoning (AIME 24, MMLU Pro) its multi‑step planning yields robust accuracy comparable to closed‑source counterparts. The lightweight Air variant maintains competitive scores within its parameter bracket (100 B scale), making it a tempting choice for edge deployments and embedded systems.
Performance Benchmarks
- Intelligence Index: GLM 4.5 scores 66 on a composite Intelligence Index (MMLU Pro, MATH 500, AIME 24), outpacing many open‑source and commercial mid‑tier models.
- Inference Latency: Time‑to‑first‑token averages 0.89 s, competitive for complex reasoning tasks, though slightly slower in throughput (≈45.7 tokens/s) compared to some optimized closed‑source models .
- Agentic Workflow: Demonstrates robust command of multi‑step tool use and dynamic code generation, with head‑to‑head win rates of ~54% against Kimi K2 and 81% against Qwen3‑Coder in independent coding evaluations .
What practical use cases showcase ROI?
- Full‑Stack Development: GLM‑4.5 can scaffold entire web applications—from frontend layouts in HTML/CSS/JavaScript to backend database schemas—through multi‑turn prompts, slashing prototyping cycles from days to hours .
- Complex Document Analysis: The extended 128 K context window empowers legal, financial, and scientific firms to parse multi‑page contracts or research reports in one shot, reducing segmentation overhead.
- Automated Agent Workflows: Hybrid inference allows the creation of autonomous scripts (e.g., web scraping bots, trading agents) that reason through multi‑step processes with minimal human intervention.
Quantitative case studies suggest up to 60 percent reduction in developer hours for code‑centric tasks and 40 percent faster turnaround on long‑form content analysis.
What Are the Potential Drawbacks and Considerations?
No technology is without trade‑offs. Prospective adopters should be mindful of regulatory, operational, and ecosystem factors.
Limitations
Support & SLAs: Open‑source providers may not offer enterprise‑grade SLAs or 24/7 support, unlike commercial counterparts.
Throughput Constraints: While the context window is massive, token‑per‑second rates lag behind some inference‑optimized closed‑source counterparts, potentially affecting real‑time applications.
Operational Overhead: Self‑hosting MoE models requires careful orchestration (expert routing, memory management) to avoid performance bottlenecks and cost overruns.
What infrastructure investments are required?
- Compute Footprint: Even with MoE efficiency, hosting GLM‑4.5’s standard variant demands GPUs with ≥80 GB of memory and robust NVLink interconnects for low-latency inference.
- Fine‑Tuning Overhead: Customizing the model for domain‑specific tasks may require substantial GPU cycles, driving up upfront costs before token‑billing savings materialize.
- Maintenance: On‑premise deployments shift responsibility for updates, security patches, and scaling from the vendor to in‑house DevOps teams.
How Can You Get Started with GLM‑4.5?
Embarking on a GLM‑4.5 integration involves a few straightforward steps—especially given the open‑source playbook and extensive third‑party support.
Which APIs and platforms support GLM‑4.5?
- CometAPI API: Fully OpenAI‑compatible endpoint, featuring SDKs in Python, JavaScript, and Java.
- Direct Z.ai Endpoint: Offers official support and early‑access features such as multi‑agent orchestration.
- Community Mirrors: Rapidly growing host of open‑source runtimes (e.g., Ollama, AutoGPT‑CLI) that enable local inference.
Where can developers find tooling and documentation?
- Z.ai Official Docs: Comprehensive guides on installation, prompt engineering, and MoE optimization.
- GitHub Repositories: Sample notebooks for code generation, retrieval‑augmented generation (RAG), and agent frameworks compatible with major orchestration tools.
- Community Forums: Active discussion boards on platforms like Hugging Face, where practitioners share fine‑tuning recipes, prompt libraries, and performance benchmarks.
Conclusion
The GLM‑4.5 series stakes a bold claim in today’s hyper‑competitive AI landscape: unmatched cost‑performance for developers, enterprises, and research institutions alike. With token pricing as low as $0.11 per million input tokens and $0.28 per million outputs—further slashed by a 50 percent promotional discount—and benchmark performance rivalling or exceeding larger proprietary models, GLM‑4.5 delivers substantial ROI for code‑centric applications, long‑form understanding, and agentic workflows.
Getting Started
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
Developers can access GLM-4.5 Air API and GLM‑4.5 API through CometAPI, the latest claude models version listed are as of the article’s publication date. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.