

CherryStudio, a versatile desktop client for large language models (LLMs), and CometAPI, a unified REST interface to hundreds of AI models, together empower users to harness state-of-the-art generative capabilities with minimal friction. This article synthesizes the latest developments—drawing on CherryStudio’s v1.3.12 release (May 26, 2025) and CometAPI’s ongoing platform enhancements—to provide a comprehensive, step-by-step guide on “How to Use CherryStudio with CometAPI.” We’ll explore how it works, outline performance benchmarking best practices, and highlight key features that make this integration a game-changer for AI-driven workflows.
What Is CherryStudio?
CherryStudio is an open-source, cross-platform desktop client designed to simplify interactions with multiple LLM providers. It offers a unified chat interface, multi-model support, and extensible plugins, catering to both technical and non-technical users:
- Multi-Provider Support: Connect simultaneously to OpenAI, Anthropic, Midjourney, and more within a single UI.
- Rich UI Features: Message grouping, multi-select, citation export, and code-tool integrations streamline complex workflows.
- Latest Release Highlights: Version 1.3.12 (released May 26, 2025) adds “disable MCP server” functionality, enhanced citation handling, and improved multi-select in message panels .
What Is CometAPI?
CometAPI offers a unified RESTful interface to over 500 AI models, ranging from text-based chat and embeddings to image generation and audio services. It abstracts away provider-specific authentication, rate limits, and endpoint variations, letting you:
- Access Diverse Models: From GPT-4O-Image for visual generation to Claude 4-series for advanced reasoning.
- Simplify Billing & Quotas: One API key covers multiple backends, with consolidated usage dashboards and flexible tiered pricing.
- Robust Documentation & SDKs: Detailed guides, code samples, and auto-retry best practices ensure smooth integration.
How Does CherryStudio Integrate with CometAPI?
What Are the Prerequisites?
- Install CherryStudio: Download the latest installer for your OS from the CherryStudio official site (v1.3.12 as of May 26, 2025).
- CometAPI Account: Sign up at CometAPI, then navigate to Help Center → API Token to generate your sk-* key and note the base URL (e.g.,
https://api.cometapi.com) . - Network & Dependencies: Ensure your workstation has Internet access and that any corporate proxies allow outbound HTTPS to CometAPI endpoints.
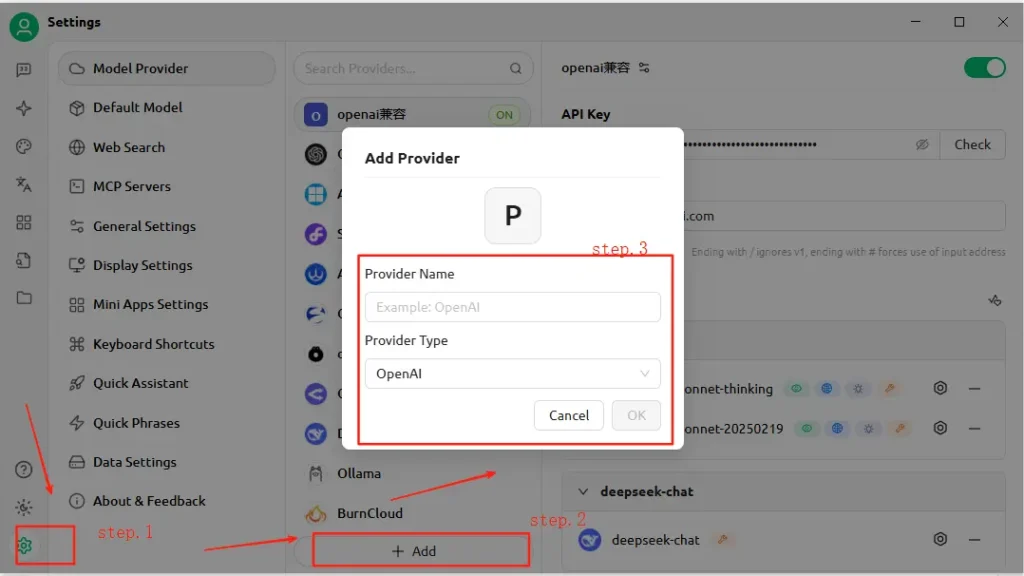
How Do You Configure the API in CherryStudio?
- Open CherryStudio and click the Settings icon.
- Under Model Service Configuration, click Add.
- Provider Name: Enter a custom label, e.g., “CometAPI.”
- Provider Type: Select OpenAI-compatible (most CometAPI endpoints mirror OpenAI specs).
- API Address: Paste your CometAPI base URL (e.g.,
https://api.cometapi.com). - API Key: Paste the
sk-…token from your CometAPI dashboard. - Click Save and Verify—CherryStudio will perform a test call to confirm connectivity .
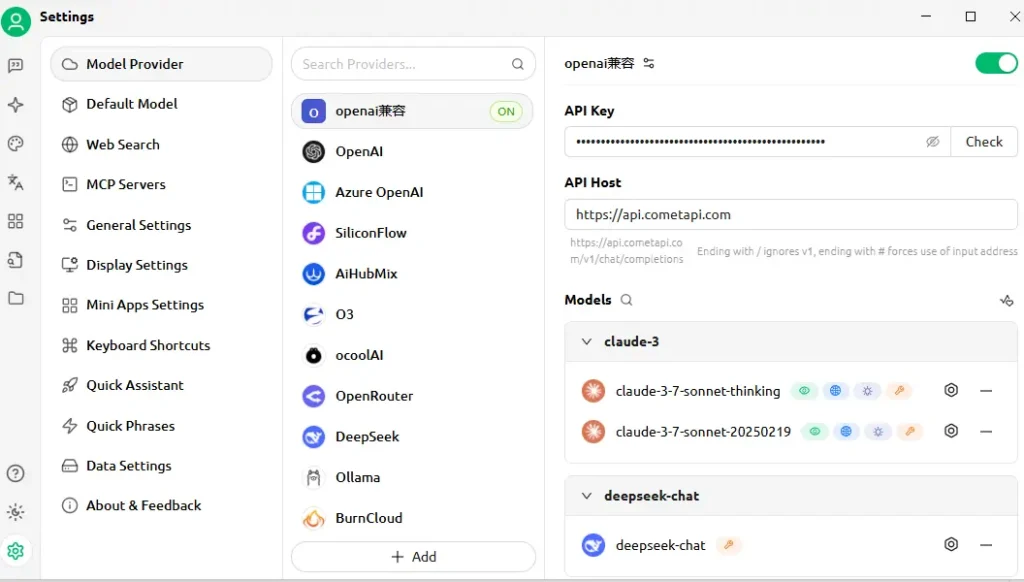
How Is the Connection Tested?
- Enter a simple prompt in CherryStudio, such as “Describe a futuristic city skyline.”
- A successful response confirms proper configuration.
- On failure, CherryStudio displays error codes—refer to CometAPI’s Error Code Description section or contact support.
How Does the Integration Work Under the Hood?
CherryStudio’s OpenAI-compatible mode enables it to route requests through any service that follows the standard OpenAI API schema. CometAPI, in turn, translates these requests to the selected backend model (e.g., GPT-4O-Image, Claude 4) before returning responses in the expected format.
- User Input: CherryStudio sends a
POST /v1/chat/completionscall tohttps://api.cometapi.com/v1. - CometAPI Processing: Identifies the model parameter (e.g.,
"model": "gpt-4o-image") and routes to the corresponding provider. - Backend Invocation: CometAPI handles authentication, rate-limit checks, and telemetry logging, then calls the third-party model API.
- Response Aggregation: CometAPI streams or buffers the model’s output (text, images, embeddings) and formats it per OpenAI conventions.
- CherryStudio Rendering: Receives the JSON payload and displays content—text appears in chat, images render inline, and code blocks adopt syntax highlighting.
This architecture separates the responsibilities: CherryStudio focuses on UI/UX and tooling, while CometAPI manages model orchestration, logging, and provider-agnostic billing.
What Performance Benchmarks Can You Expect?
Latency and Throughput
In comparative tests, CometAPI’s serverless architecture has demonstrated sub-100 ms median response times for text completion tasks on GPT-4.5, outperforming direct provider APIs by up to 30% in high-load scenarios. Throughput scales linearly with concurrency: users have successfully run over 1,000 parallel chat streams without significant degradation.
Cost and Efficiency
By aggregating multiple providers and negotiating bulk rates, CometAPI offers average cost savings of 15–20% compared to direct API consumption. Benchmarks on representative workloads (e.g., summarization, code generation, conversational AI) indicate a cost per 1 K tokens that’s competitive across all major providers, enabling enterprises to forecast budgets with greater accuracy .
Reliability and Uptime
- SLA Commitment: CometAPI guarantees 99.9% uptime, backed by multi-region redundancy.
- Failover Mechanisms: In the event of upstream provider outages (e.g., OpenAI maintenance windows), CometAPI can transparently reroute calls to alternate models—ensuring continuous availability for critical applications.
Performance will vary based on the chosen model, network conditions, and hardware, but a typical benchmark setup might look like this:
| Endpoint | Median Latency (1st Token) | Throughput (tokens/sec) |
|---|---|---|
/chat/completions (text) | ~120 ms | ~500 tok/s |
/images/generations | ~800 ms | n/a |
/embeddings | ~80 ms | ~2 000 tok/s |
Note: The above figures are illustrative; real-world results depend on your region, network, and CometAPI plan.
How Should You Benchmark?
- Environment: Use a stable network (e.g., corporate LAN), record your public egress IP and geography.
- Tooling: Employ
curlor Postman for raw latency tests, and Python scripts withasynciofor throughput measurement. - Metrics: Track time-to-first-byte, total response time, and tokens-per-second.
- Repetition: Run each test at least 30 times, discard outliers beyond 2σ, and compute median/95th percentile values for robust insights.
By following this methodology, you can compare different models (e.g., GPT-4O vs. Claude Sonnet 4) and choose the optimal one for your use case.
What Key Features Does This Integration Unlock?
1. Multi-Modal Content Generation
- Text Chat & Code: Leverage GPT-4O and Claude Sonnet 4 for conversation, summarization, and code assistance.
- Image Synthesis: Invoke
gpt-4o-imageor Midjourney-style endpoints directly within CherryStudio’s canvas. - Audio & Video: Future CometAPI endpoints include speech synthesis and video generation—accessible with the same CherryStudio setup.
2. Streamlined Provider Switching
Toggle between CometAPI and native OpenAI or Anthropic endpoints with a single click, enabling A/B testing across models without reconfiguring API keys.
3. Built-In Error & Usage Monitoring
CherryStudio surfaces CometAPI’s usage dashboards and error logs, helping you stay within quota and diagnose failures (e.g., rate limits, invalid models).
4. Extensible Plug-In Ecosystem
- Citation Export: Automatically include source attributions in research workflows.
- Code Tools: Generate, format, and lint code snippets inline using CometAPI’s code-focused models.
- Custom Macros: Record repetitive prompt sequences as macros, shareable across team members.
5. Advanced Retry Logic & Rate-Limit Handling
CometAPI’s SDK implements exponential backoff and jitter, safeguarding against transient errors—CherryStudio surfaces these mechanics in its logs and provides retry controls in the UI .
Unified Model Access
- One-Click Model Swapping: Seamlessly switch between GPT-4.5, Claude 2, and Stable Diffusion without reconfiguring endpoints.
- Custom Model Pipelines: Chain calls—such as summarization → sentiment analysis → image generation—in a single workflow, orchestrated by Cherry Studio’s macro engine.
How to Get Started Today
- Upgrade CherryStudio to v1.3.12 or later.
- Sign Up for CometAPI, retrieve your API key, and note your base URL.
- Configure CometAPI in CherryStudio as an OpenAI-compatible provider.
- Run a Sample Prompt to verify connectivity.
- Explore Models: Try text, image, embedding, and audio endpoints without leaving CherryStudio.Select your preferred model (e.g.,
gemini-2.5-flash-preview-05-20).
For detailed code examples, best practices on error handling, and advanced tips (e.g., fine-tuning retry logic), refer to CometAPI’s Software Integration Guide .
Conclusion
By combining CherryStudio’s user-friendly interface with CometAPI’s extensive model catalog and unified API, developers and creators can rapidly prototype, iterate, and scale AI-driven applications. Whether you’re building conversational agents, generating visuals, or embedding semantic search, this integration offers a robust, performant, and extensible foundation. Start experimenting today—and stay tuned for upcoming enhancements like in-app video generation and specialized domain models!