

Anthropic released Claude Opus 4.5 in late November 2025 as a more capable, more efficient Opus-class model targeted at professional software engineering, agentic workflows, and long-horizon tasks. It’s available through Anthropic’s developer platform and via CometAPI and it introduces new API controls (notably the effort parameter), improved computer-use tooling, extended thinking, and token efficiency improvements that matter in production.
Below is a practical, professional walkthrough: what changed, how to get access, how to use the new controls (effort, extended thinking, tool use, files/computer use), cost & optimization guidance, safety/governance considerations, and real-world integration patterns.
What exactly is Claude Opus 4.5 and why does it matter?
Claude Opus 4.5 is Anthropic’s newest Opus-class model family member (released November 24–25, 2025) that focuses on maximum reasoning and coding capability while improving token efficiency and offering new API controls for balancing cost vs. thoroughness. Anthropic positions Opus 4.5 as the “most intelligent model” it has released, aiming at complex software engineering tasks, long-running agents, spreadsheet/Excel automation, and tasks requiring sustained multi-step reasoning.
What are the major updates in Opus 4.5?
Anthropic designed Opus 4.5 to improve depth of reasoning and agentic behavior while giving developers better control over cost/latency tradeoffs. The release highlights are:
- Effort parameter (beta): a first-class API knob that controls how much “thinking budget” Claude spends on a request (commonly
low,medium,high). It influences reasoning, tool calls, and internal “thinking” tokens so you can tune speed vs. thoroughness per-call rather than switching models. This is a signature Opus 4.5 capability. - Better agent and tool orchestration: improved accuracy at choosing tools, better structured tool calls and a more robust tool-result workflow for building agents and multi-step pipelines. Anthropic ships docs and SDK guidance for the “tool use” flow.
- Token / cost efficiency — Anthropic reports up to ~50% reductions in token usage for some workflows vs Sonnet 4.5, plus fewer tool call errors and fewer iterations for complex engineering tasks.
- Enhanced multimodal capabilities: Comprehensive improvements in visual, reasoning, and mathematical performance.
- Context window expanded to 200K tokens, supporting deep, long conversations and complex document analysis.
What practical capabilities improved?
Performance upgrade
- Better agent and tool orchestration: improved accuracy at choosing tools, better structured tool calls and a more robust tool-result workflow for building agents and multi-step pipelines. Anthropic ships docs and SDK guidance for the “tool use” flow. Improved context handling , compaction helpers for long agent runs, and first-class tool SDKs for registering and validating tools means Opus 4.5 is better for building agents that run unattended for many steps.
- Enhanced multimodal capabilities: Comprehensive improvements in visual, reasoning, and mathematical performance.
- Context window expanded to 200K tokens, supporting deep, long conversations and complex document analysis.
Coding and long-horizon work
Opus 4.5 continues to be benchmark-driven for coding tasks; it reduces the number of iterations and tool-call errors during long jobs (code migration, refactor, multi-step debugging). Early reports and Anthropic’s system card note improved sustained performance on engineering benchmarks and dramatic efficiency wins in tool-driven pipelines.
In SWE-bench , Opus 4.5 reports leading scores on software-engineering benchmarks (Anthropic lists an 80.9% on SWE-bench Verified in launch material), and customers report improvements on debugging, multi-file edits, and long-horizon code tasks.

Cost and Efficiency
Anthropic designed Opus 4.5 to improve depth of reasoning and agentic behavior while giving developers better control over cost/latency tradeoffs:
- Price Reduction Compare to opus 4.1: $5 (input) / $25 (output) per million tokens.
- Token Usage Improvement: Average reduction of 50–75% in consumption while maintaining performance.
- a first-class API knob that controls how much “thinking budget” Claude spends on a request (commonly
low,medium,high). It influences reasoning, tool calls, and internal “thinking” tokens so you can tune speed vs. thoroughness per-call rather than switching models. This is a signature Opus 4.5 capability( Compared to Sonnet 4.5: Medium Effort → 76% less tokens, comparable performance; High Effort → 4.3% performance improvement, 48% reduction in token usage).
How do I access and use Claude Opus 4.5 API?
How can I obtain access and keys?
- Create an Anthropic / Claude Developer account. Sign up at the Claude/Anthropic developer portal and create an API key via the Console (organization/admin flows exist for teams). The Messages API is the primary endpoint for chat/assistant-style interactions.
- Cloud partners: Opus 4.5 is also available through major cloud marketplaces Google Vertex AI, CometAPI(An AI API aggregation platform, need to uses its authentication)), In CometAPI, you can access Claude opus 4.5 API via Anthropic Messages format and Chat format.
How should I authenticate my requests?
Use standard bearer tokens: include an Authorization: Bearer $_API_KEY header with every API call. Requests are JSON over HTTPS; the Messages API accepts a list of structured messages (system + user + assistant).
Quickstart — Python (official SDK)
Install the SDK:
pip install anthropic
Minimal example (synchronous):
import os
from anthropic import Anthropic
# expects ANTHROPIC_API_KEY in env
client = Anthropic(api_key=os.environ)
resp = client.messages.create(
model="claude-opus-4-5-20251101",
messages=,
max_tokens=512,
)
print(resp.content.text) # SDK returns structured content blocks
This call uses the canonical Opus 4.5 model identifier. For provider-managed endpoints (Vertex, CometAPI, Foundry) follow the provider docs to construct the client and supply the provider’s url and key(e.g., https://api.cometapi.com/v1/messages for CometAPI).
Quickstart — Python (CometAPI)
You need to log in to CometAPI and obtain a key.
curl
--location
--request POST 'https://api.cometapi.com/v1/messages' \
--header 'Authorization: Bearer ' \
--header 'Content-Type: application/json' \
--data-raw '{ "model": "claude-opus-4-5-20251101", "max_tokens": 1000, "thinking": { "type": "enabled", "budget_tokens": 1000 }, "messages": }'
How do I use the new effort parameter and extended thinking?
What is the effort parameter and how do I set it?
The effort parameter is a first-class API control introduced with Opus 4.5 that adjusts how much internal computation and token budget the model spends producing its output. Typical values are low, medium, and high. Use it to balance latency and token cost versus thoroughness:
low— fast, token-efficient answers for high-volume automation and routine tasks.medium— balanced quality/cost for production use.high— deep analysis, multi-step reasoning, or when accuracy matters most.
Anthropic introduced effort for Opus 4.5 (beta). You must include a beta header (e.g., effort-2025-11-24) and specify output_config: { "effort": "low|medium|high" } (example shown below). high is the default behavior. Lowering effort reduces token use and latency but can modestly reduce thoroughness. Use it for high-throughput or latency-sensitive tasks.
Example:
# Example using the beta messages API shown in Anthropic docs
from anthropic import Anthropic
import os
client = Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
response = client.beta.messages.create(
model="claude-opus-4-5-20251101",
betas=, # required beta header
messages=,
max_tokens=1500,
output_config={"effort": "medium"} # low | medium | high
)
print(response)
When to use which: use low for automated pipelines (e.g., email categorization), medium for standard assistants, and high for code generation, deep research, or risk-sensitive tasks. Anthropic highlights this parameter as a key control for Opus 4.5.
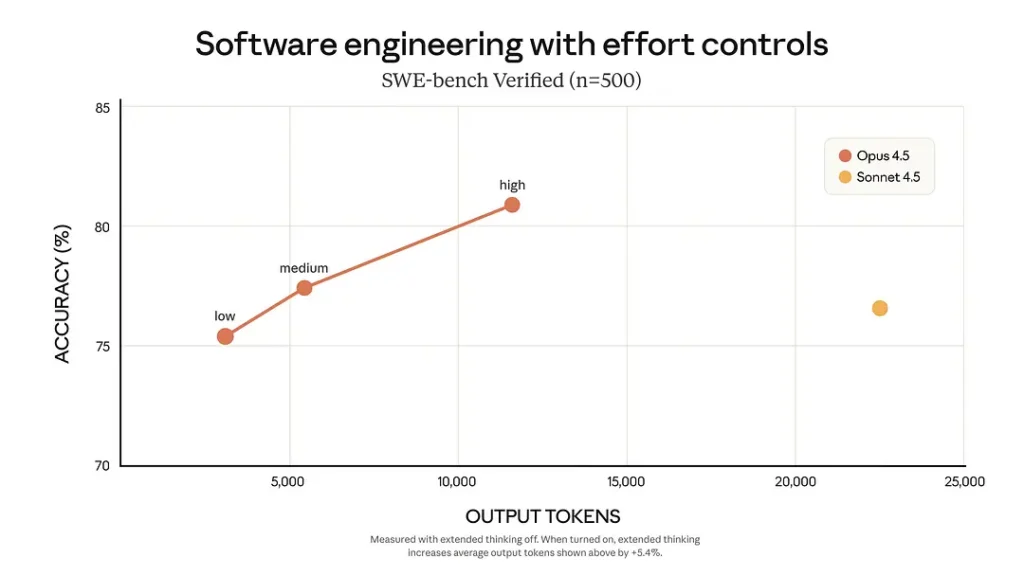
In the SWE-bench test:
- In Medium Effort mode: performance is comparable to Sonnet 4.5, but output tokens are reduced by 76%;
- In High Effort mode: performance exceeds Sonnet 4.5 by approximately 4.3 percentage points, and tokens are reduced by 48%.
What is Extended Thinking and how do I invoke it?
Extended Thinking (also called “extended thinking” or “thinking blocks”) lets the model perform intermediate chains of thought or stepwise reasoning while optionally preserving or summarizing the internal thought blocks. The Messages API supports this behavior and Anthropic added controls for preserving previous thinking blocks so multi-turn agents can reuse earlier reasoning without repeating expensive recomputation. Use extended thinking when the task requires multi-step planning, long-horizon problem solving, or tool orchestration.
How do I integrate tools and build agents with Opus 4.5?
One of Opus 4.5’s major strengths is improved tool use: define tools in your client, let Claude decide when to call them, execute the tool, and return the tool_result — Claude will use those results in its final reply. Anthropic provides Agent SDKs that let you register typed tool functions (e.g., run_shell, call_api, search_docs) that Claude can discover and call during extended thinking. The platform converts tool definitions into callable functions the model can call and receive results from. This is how you build agentic workflows safely (with controlled inputs/outputs).
Below is a practical pattern and an end-to-end Python example.
Tool-use pattern (conceptual)
- Client supplies
toolsmetadata with name, description, and JSON schema (input_schema). - Model returns a
tool_useblock (the model’s structured instruction to call a particular tool with specific inputs). The API responsestop_reasonmay betool_use. - Client executes the tool (your code calls the external API or local function).
- Client sends a follow-up message with
role:"user"and atool_resultcontent block containing the tool’s outputs. - Model consumes the tool result and returns final answer or further tool calls.
This flow allows safe client-side control over what the model executes (the model proposes tool calls; you control execution).
End-to-end example — Python (simple weather tool)
# 1) Define tools metadata and send initial request
from anthropic import Anthropic
import os, json
client = Anthropic(api_key=os.environ)
tools = [
{
"name": "get_weather",
"description": "Return the current weather for a given city.",
"input_schema": {"type":"object","properties":{"city":{"type":"string"}},"required":}
}
]
resp = client.messages.create(
model="claude-opus-4-5-20251101",
messages=,
tools=tools,
max_tokens=800,
)
# 2) Check if Claude wants a tool call
stop_reason = resp.stop_reason # SDK field
if stop_reason == "tool_use":
# Extract the tool call (format varies by SDK; this is schematic)
tool_call = resp.tool_calls # e.g., {"name":"get_weather", "input":{"city":"Tokyo"}}
tool_name = tool_call
tool_input = tool_call
# 3) Execute the tool client-side (here: stub)
def get_weather(city):
# Replace this stub with a real weather API call
return {"temp_c": 12, "condition": "Partly cloudy"}
tool_result = get_weather(tool_input)
# 4) Send tool_result back to Claude
follow_up = client.messages.create(
model="claude-opus-4-5-20251101",
messages=[
{"role":"user", "content":[{"type":"tool_result",
"tool_use_id": resp.tool_use_id,
"content": json.dumps(tool_result)}]}
],
max_tokens=512,
)
print(follow_up.content.text)
else:
print(resp.content.text)
How should you structure agents for reliability?
- Sanitize tool inputs (avoid injection via prompts).
- Validate tool outputs before feeding them back to the model (schema checks).
- Limit tool scope (principle of least privilege).
- Use compaction helpers (from Anthropic SDKs) to keep context manageable over long runs.
How should I design prompts & structure messages for Opus 4.5?
What message roles and prefill strategies work best?
Use a three-part pattern:
- System (role: system): global instructions — tone, guardrails, role.
- Assistant (optional): canned examples or priming content.
- User (role: user): the immediate request.
Prefill the system message with constraints (format, length, safety policy, JSON schema if you want structured output). For agents, include tool specifications and usage examples so Opus 4.5 can call those tools correctly.
How do I use context compaction and prompt caching to save tokens?
- Context compaction: compress older parts of a conversation into concise summaries the model can still use. Opus 4.5 supports automation to compact context without losing critical reasoning blocks.
- Prompt caching: cache model responses for repeated prompts (Anthropic provides prompt caching patterns to reduce latency/cost).
Both features reduce the token footprint of long interactions and are recommended for long-running agent workflows and production assistants.
Error handling and best practices
Below are pragmatic reliability and safety recommendations for production integration with Opus 4.5.
Reliability & retries
- Handle rate limits (HTTP 429) with exponential backoff and jitter (start at 500–1000ms).
- Idempotency: for non-mutating LLM calls you can safely retry, but be careful in workflows where the model triggers external side-effects (tool calls) — deduplicate by tracking
tool_use_idor your own request IDs. - Streaming stability: handle partial streams and reconnect gracefully; if an interruption occurs, prefer to retry the whole request or resume using application-level state to avoid inconsistent tool interactions.
Security & safety
- Prompt injection & tool safety: never allow the model to directly execute arbitrary shell commands or code without validation. Always validate tool inputs and sanitize outputs. The model proposes tool calls; your code decides whether to run them. Anthropic’s system card and docs describe alignment constraints and safety levels—follow them for high-risk domains.
- Data handling & compliance: treat prompts and tool inputs/outputs containing PII or regulated data according to your legal/compliance policy. Use provider VPC/enterprise controls if you have strict data residency or audit requirements (Bedrock / Vertex / Foundry provide enterprise options).
Observability & cost control
- Log request/response metadata (not raw sensitive content unless permitted) — token counts,
effortlevel, latency, model id, and provider. These metrics are essential for cost attribution and debugging. - Use effort to control cost per-call: prefer
loweffort for routine summarization or high-QPS endpoints; usehigheffort for deep debugging or investigations. Monitor quality vs. token consumption to pick defaults for different endpoints.
Conclusion — When (and how) should you choose Opus 4.5?
Claude Opus 4.5 is a natural choice when your product needs:
- deep multi-step reasoning (long chains of logic, research, or debugging),
- robust agent/tool orchestration (complex workflows invoking external APIs), or
- production-grade code assistance across large codebases.
Operationally, use effort to tune per-call budgets; rely on the tool-use pattern to retain execution safety and choose a cloud partner (or Anthropic API direct) based on your compliance needs. Benchmark with your own corpus: vendor numbers (SWE-bench etc.) are useful signals but your real task and data determine ROI. For safety, follow the Opus 4.5 system card and put guardrails around tool execution and PII handling.
Developers can access Claude Opus 4.5 API through CometAPI. To begin, explore the model capabilities ofCometAPI in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!