

Nano Banana Pro — officially Gemini 3 Pro Image — is Google/DeepMind’s new studio-grade image generation and editing model that combines advanced multimodal reasoning, high-fidelity text rendering, multi-image composition, and studio-level creative controls.
What is Nano Banana Pro and why should you care?
Nano Banana Pro is Google’s newest image-generation and image-editing model — the “Gemini 3 Pro Image” release — designed to produce high-fidelity, context-aware images and on-image text with studio quality up to 4K. It’s a successor to the earlier Nano Banana models (Gemini 2.5 Flash Image / “Nano Banana”) with improved reasoning, Search grounding (real-world facts), stronger text rendering, and more powerful local edit controls. The model is available inside the Gemini app for interactive users and access Nano Banana Pro through the standard Gemini API, but you select the specific model identifier (gemini-3-pro-image-preview or its stable successor). for programmatic access.
Why this matters: Nano Banana Pro is built not only to make pretty images but to visualize information — infographics, data-driven snapshots (weather, sports), text-heavy posters, product mockups and multi-image fusions (up to 14 input images and maintaining character consistency across up to 5 people). For designers, product teams and developers, that combination of accuracy, on-image text and programmatic access opens production workflows previously hard to automate
What functions are exposed via the API?
Typical API capabilities exposed to developers include:
- Text → Image generation (single-step or multi-step “thinking” composition flows).
- Image editing (local masks, inpainting, style adjustments).
- Multi-image fusion (combine reference images).
- Advanced request controls: resolution, aspect ratio, post-processing steps, and “composition thought” traces for debug/inspectability in preview modes.
Core Innovations and Functions of Nano Banana Pro
Smarter content reasoning
Uses Gemini 3 Pro’s reasoning stack to interpret complex, multi-step visual instructions (e.g., “create a 5-step infographic from this dataset and add a bilingual caption”). The API exposes a “Thinking” mechanism that can produce interim composition tests to refine the final output.
Why it matters: Instead of a single pass that maps prompt → pixel, the model performs an internal “thinking” process that refines composition and can call external tools (e.g., Google Search) for factual grounding (e.g., accurate diagram labels or locale-correct signage). This yields images that are not only prettier but more semantically correct for tasks like infographics, diagrams, or product mockups.
How to achieve: Nano Banana Pro’s “Thinking” is a controlled internal reasoning/composition pass where the model generates intermediate visuals and reasoning traces before producing the final image. The API exposes that the model may create up to two interim frames and that the final image is the last stage of that chain. In production this helps with composition, placement of text, and layout decisions.
More accurate text rendering
Significantly improved legible, localized text inside images (menus, posters, diagrams).Nano Banana Pro reaches new heights in image text rendering:
- Text in images is clear, legible, and accurately spelled;
- Supports multilingual generation (including Chinese, Japanese, Korean, Arabic, etc.);
- Allows users to write long paragraphs or multi-line descriptive text directly into images;
- Automatic translation and localization are available.
Why it matters: Traditionally image models struggle to render readable, well-aligned text. Nano Banana Pro is explicitly optimized for reliable text rendering and localization (e.g., translating and preserving layout), which unlocks real creative use cases like posters, packaging, or multi-language ads.
How to achieve: Text rendering improvements come from the underlying multimodal architecture and training on datasets emphasizing text-in-image examples, combined with targeted evaluation sets (human evaluations and regression sets). The model learns to align glyph shapes, fonts, and layout constraints to produce legible, localized text inside images — though small text and extremely dense paragraphs can still be error-prone.
Stronger visual consistency and fidelity
Studio controls (lighting, focus, camera angle, color grading) and multi-image composition (up to 14 reference images, with special allowances for multiple human subjects) help preserve character consistency(keep the same person/character across edits) and brand identity across generated assets. The model supports native 1K/2K/4K outputs.
Why it matters: Marketing and entertainment workflows require consistent characters across shots and edits. The model can maintain resemblance for up to five people and blend up to 14 reference images into a single composition while producing Sketch → 3D Render. This is useful for ad creative, packaging, or multi-shot storytelling.
How to achieve: Model inputs accept multiple images with explicit role assignments (e.g., “Image A: pose”, “Image B: face reference”, “Image C: background texture”). The architecture conditions generation on those images to maintain identity/pose/style while applying transformations (lighting, camera).
Performance Benchmarks of Nano Banana Pro
Nano Banana Pro (Gemini 3 Pro Image) “excels on Text→Image AI benchmarks” and that it demonstrates improved reasoning and contextual grounding compared to earlier Nano Banana models. It emphasize higher fidelity and improved text rendering relative to previous releases.
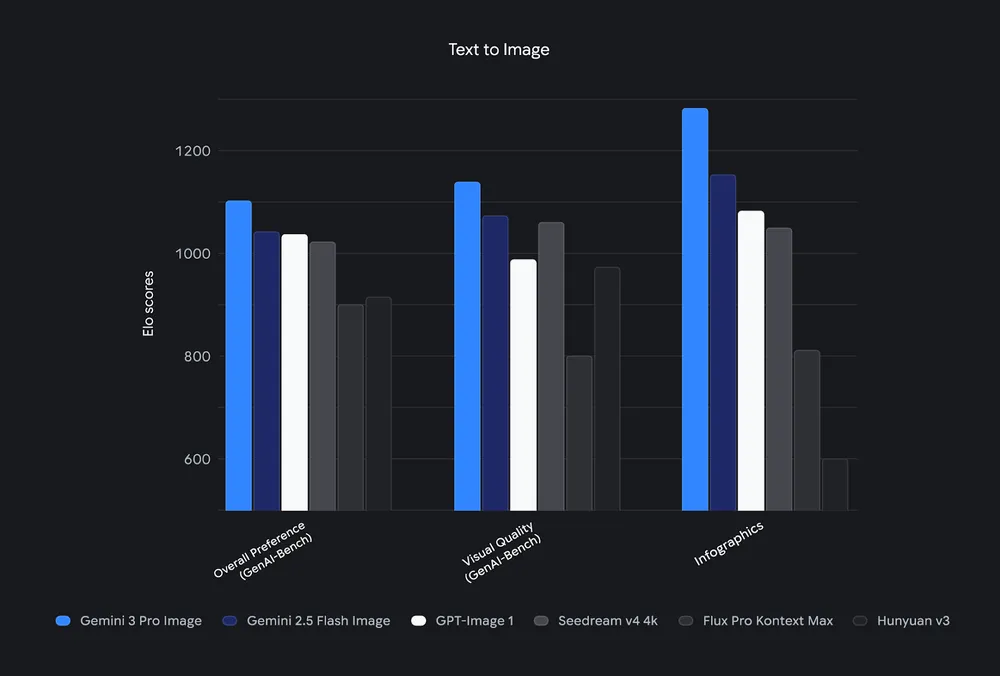
Practical performance guidance
Expect higher latency and cost for 2K/4K high-fidelity renders than for 1K or the “Flash” models optimized for speed. If throughput/latency are critical, use the flash variant (e.g., Gemini 2.5 Flash / Nano Banana) for high volume; use Nano Banana Pro / gemini-3-pro-image for quality and complex reasoning tasks.
How Can Developers Access Nano Banana Pro?
Which endpoints and models to pick
Model identifier (preview / pro): gemini-3-pro-image-preview (preview) — use this when you want the Nano Banana Pro capabilities. For faster, lower-cost work, gemini-2.5-flash-image (Nano Banana) remains available.
Surfaces to use
- Gemini API (generativelanguage endpoint): You can use a CometAPI key to access xx. CometAPI offers the same API at a more favorable price than the official website. Direct HTTP / SDK calls to
generateContentfor image generation (examples below). - Google AI Studio: Web surface for rapid experimentation and remixing demo apps.
- Vertex AI (enterprise): Provisioned throughput, billing choices (pay-as-you-go / enterprise tiers), and safety filters for large scale production. Use Vertex when integrating into large pipelines or batch rendering jobs.
The free tier has a limited usage limit; exceeding the limit will revert to Nano Banana. The Plus/Pro/Ultra tiers offer higher limits and watermark-free output, but Ultra can be used in Flow video tools and Antigravity IDE in 4K mode.
How do I generate an image with Nano Banana Pro (step-by-step)?
1) Quick interactive recipe tu use Gemini app
- Open Gemini → Tools → Create images.
- Select Thinking (Nano Banana Pro) as the model.
- Enter a prompt: explain subject, action, mood, lighting, camera, aspect ratio, and any text to appear on the image. Example:
“Create a 4K poster of a robotics workshop: a diverse team around a table, blueprint overlay, bold headline ‘Robots in Action’ in sans serif, warm tungsten light, shallow depth of field, cinematic 16:9.” - (Optional) Upload up to 14 images to fuse or use as references. Use the selection/mask tool to local-edit areas.
- Generate, iterate with natural language (e.g., “make the headline blue and aligned top-center; increase contrast on the blueprint”), then export
2) Use HTTP to Send to Gemini image endpoint
You need to log in to CometAPI to obtain the key.
# save your API key to $CometAPI_API_KEY securely before running
curl -s -X POST \
"https://api.cometapi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: $CometAPI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"role": "user",
"parts": [{
"text": "Photorealistic 4K image of a yellow banana floating over Earth, studio lighting, cinematic composition. Add bold text overlay: \"Nano Banana Pro\" in top right corner."
}]
}],
"generationConfig": {
"imageConfig": {
"resolution": "4096x4096",
"aspectRatio": "1:1"
}
}
}' \
| jq -r '.candidates.content.parts[] | select(.inlineData) | .inlineData.data' \
| base64 --decode > nano_banana_pro_4k.png
This sample writes the base64 image payload to a PNG file. The generationConfig.imageConfig.resolution parameter requests 4K output (available for the 3 Pro Image model)
3) Direct SDK calls to generateContent for image generation
Requires installing the Google SDK and obtaining Google authentication. Python example (text + reference images + grounding):
# pip install google-genai pillow
from google import genai
from PIL import Image
import base64
client = genai.Client() # reads credentials from env / config per SDK docs
# Read a reference image and set inline_data
with open("ref1.png", "rb") as f:
ref1_b64 = base64.b64encode(f.read()).decode("utf-8")
prompt_parts = [
{"text": "Create a styled product ad for a yellow banana-based energy bar. Use studio lighting, shallow DOF. Include a product label with the brand name 'Nano Bar'."},
{"inline_data": {"mime_type": "image/png", "data": ref1_b64}}
]
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=,
generation_config={
"imageConfig": {"resolution":"4096x4096", "aspectRatio":"4:3"},
# tools can be provided to ground facts, e.g. "google_search"
"tools":
}
)
for part in response.candidates.content.parts:
if part.inline_data:
image = part.as_image()
image.save("product_ad.png")
This example shows uploading an inline reference image and requesting a 4K composition while enabling google_search as a tool. The Python SDK will handle low-level REST details.
Multi-image fusion & character consistency
To produce a composite that preserves the same person across scenes, pass multiple inline_data parts (selected from your photo set), and specify the creative instruction that the model should “preserve identity across outputs.”
Short practical example — a real prompt and expected flow
Prompt:
"Generate a 2K infographic: 'Q4 Sales by Region 2025' — stacked bar chart with North America 35%, EMEA 28%, APAC 25%, LATAM 12%. Include title top-center, caption with source bottom-right, clean sans-serif labels, neutral palette, vector look, 16:9."
Expected pipeline: app → prompt template + CSV data → replace placeholders in prompt → API call with image_size=2048x1152 → receive base64 PNG → save asset + provenance metadata → optionally overlay exact font via compositor if needed.
How should I design a production pipeline and handle safety / provenance?
Recommended production architecture
- Prompt + draft pass (fast model): Use
gemini-2.5-flash-image(Nano Banana) to produce many small-resolution variations cheaply. - Selection & refinement: pick best candidates, refine prompts, apply inpainting/mask edits for precision.
- High-fidelity final render: call
gemini-3-pro-image-preview(Nano Banana Pro) for final 2K/4K renders and postprocessing (upsampling, color grade). - Provenance & metadata: store prompt, model version, timestamps, and SynthID info in your asset metadata store — the model attaches a SynthID watermark and outputs can be traced back for compliance and content audit.
Safety, rights, and moderation
- Copyright & rights clearance: don’t upload or generate content that infringes rights. Use explicit user confirmations for user-supplied images or prompts that could create recognizable likenesses. Google’s Prohibited Use Policy and model safety filters must be respected.
- Filtering & automated checks: run generated images through an internal content moderation pipeline (NSFW, hate symbols, political/binding content detection) before downstream consumption or public display.
How do I do image editing (inpainting), multi-image composition and text rendering?
Nano Banana Pro supports multimodal editing workflows: provide one or more input images and a textual instruction describing edits (remove an object, change sky, add text). The API accepts image + text in the same request; the model can produce interleaved text and images as responses. Example patterns include masked edits and multi-image blends (style transfer / composition). See the docs for contents arrays combining text blobs and binary images.
Example: Edit (Python pseudo-flow)
from google import genai
from PIL import Image
client = genai.Client()
prompt = "Remove the person on the left and add a small red 'Nano Banana Pro' sticker on the top-right of the speaker"
# contents can include Image objects or binary data per SDK; see doc for exact call
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=, # order matters: image + instruction
)
# Save result as before
This conversational editing lets you iteratively adjust results until you reach a production-ready asset.
Node.js example — image edit with mask and multiple references
// npm install google-auth-library node-fetch
const { GoogleAuth } = require('google-auth-library');
const fetch = require('node-fetch');
const auth = new GoogleAuth({ scopes: });
async function runEdit() {
const client = await auth.getClient();
const token = await client.getAccessToken();
const API_URL = "https://api.generativemodels.googleapis.com/v1alpha/gemini:editImage";
const MODEL = "gemini-3-pro-image";
// Attach binary image content or URLs depending on API.
const payload = {
model: MODEL,
prompt: { text: "Replace background with an indoor studio set, keep subject, add rim light." },
inputs: {
referenceImages: [
{ uri: "gs://my-bucket/photo_subject.jpg" },
{ uri: "gs://my-bucket/target_studio.jpg" }
],
mask: { uri: "gs://my-bucket/mask.png" },
imageConfig: { resolution: "2048x2048", format: "png" }
},
options: { preserveIdentity: true }
};
const res = await fetch(API_URL, {
method: 'POST',
headers: {
'Authorization': `Bearer ${token.token}`,
'Content-Type': 'application/json'
},
body: JSON.stringify(payload)
});
const out = await res.json();
console.log(JSON.stringify(out, null, 2));
}
runEdit();
(APIs sometimes accept Cloud Storage URIs or base64 image payloads; check Gemini API docs for exact input formats.)
For information on generating and editing images using the CometAPI, please refer to Guide to calling gemini-3-pro-image .
Conclusion
Nano Banana Pro (Gemini 3 Pro Image) is a production-grade jump in image generation: a tool for visualizing data, producing localized edits, and powering developer workflows. Use the Gemini app for fast prototyping, the API for production integration, and follow the recommendations above to control cost, ensure safety and maintain brand quality. Always test real user workflows and store provenance metadata to meet transparency and audit needs.
Use Nano Banana Pro when you need studio-quality assets, precise control over composition, improved text rendering inside images, and the ability to fuse multiple references into one coherent output.
Developers can access Gemini 3 Pro Image( Nano Banana Pro) API through CometAPI. To begin, explore the model capabilities ofCometAPI in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!