

OpenAI, Anthropic, and Google continue to push the boundaries of large language models with their latest flagship offerings—OpenAI’s o3 (and its enhanced o3-pro variant), Anthropic’s Claude Opus 4, and Google’s Gemini 2.5 Pro. Each of these models brings unique architectural innovations, performance strengths, and ecosystem integrations that cater to different use cases, from enterprise-grade coding assistance to consumer-facing search enhancements. This in-depth comparison examines their release history, technical capabilities, benchmark performance, and recommended applications to help organizations choose the right model for their needs.
What is OpenAI’s o3, and how has it evolved?
OpenAI first introduced o3 on April 16, 2025, positioning it as “our most intelligent model” designed for extended context and highly reliable responses . Shortly thereafter, on June 10, 2025, OpenAI released o3-pro—a performance-tuned variant available to Pro users in ChatGPT as well as via the API—that delivers faster inference and higher throughput under heavy loads.
Context window and throughput
OpenAI o3 offers a 200K-token context window for both input and output, enabling the handling of extensive documents, codebases, or multi-turn conversations without frequent truncation. Its throughput measures around 37.6 tokens/sec, which—while not leading the pack—provides consistent responsiveness for sustained workloads.
Advanced Deliberative Reasoning
- “Private chain of thought”: o3 was trained with reinforcement learning to plan and reason through intermediate steps before producing its final output, markedly improving its capacity for logical deduction and problem decomposition.
- Deliberative alignment: It incorporates safety techniques that guide the model to adhere more reliably to guidelines through step-by-step reasoning, reducing major errors in complex, real-world tasks.
Pricing and enterprise integration
OpenAI’s pricing for o3 stands at approximately $2 per million input tokens and $8 per million output tokens. This positions it in the mid-range: more affordable than premium models like Claude Opus 4 on heavy workloads, but costlier than budget-friendly alternatives such as Gemini 2.5 Pro. Crucially, enterprises benefit from seamless integration with the broader OpenAI API ecosystem—covering embeddings, fine-tuning, and specialized endpoints—minimizing integration overhead .
How does Claude Opus 4 differentiate itself in the market?
Anthropic announced Claude Opus 4 on May 22, 2025, marketing it as “the world’s best coding model” with sustained performance on complex, long-running tasks and agent workflows . It launched simultaneously in Anthropic’s own API and via Amazon Bedrock, making it accessible to AWS customers through Bedrock’s LLM functions and REST API..
Extended “thinking” capabilities
A distinctive feature of Opus 4 is its “extended thinking” beta mode, which dynamically allocates compute between on-model reasoning and tool invocations (e.g., search, retrieval, external APIs). Coupled with “thinking summaries,” users gain visibility into the model’s internal reasoning chain—critical for compliance-sensitive applications in finance and healthcare .
Pricing and context trade-offs
At $15 per million input tokens and $75 per million output tokens, Claude Opus 4 sits at the top of the pricing spectrum. Its 200K-token input window (with a 32K-token output cap) is smaller than Gemini 2.5 Pro’s 1M-token window but suffices for most code review and long-form reasoning tasks. Anthropic justifies the premium by emphasizing internal compute intensity and sustained chain-of-thought fidelity .with up to 90% savings via prompt caching and 50% via batch processing . Extended thinking budgets are included for paid tiers; free users can access only the Sonnet variant.
What unique features and performance does Gemini 2.5 Pro bring?
Released as Google’s next-generation “Pro” tier, Gemini 2.5 Pro targets organizations needing massive context, multimodal inputs, and cost-effective scaling. Notably, it supports up to 1,048,576 tokens in a single prompt—inbound—and 65,535 tokens outbound, enabling end-to-end document workflows that span hundreds of thousands of pages.
Superior context and multimodality
Gemini 2.5 Pro shines with its 1M-token context window, facilitating use cases such as legal contract analysis, patent mining, and comprehensive codebase refactoring. The model natively accepts text, code, images, audio, PDFs, and video frames, streamlining multimodal pipelines without separate pre-processing steps .
How does Gemini enhance multimodal and conversational search?
Gemini 2.5 Pro stands out for its “query fan-out” methodology: it decomposes complex queries into sub-questions, runs parallel searches, and synthesizes comprehensive, conversational answers on the fly. With support for text, voice, and image inputs, AI Mode leverages Gemini’s multimodal capabilities to cater to diverse user interactions—though it remains in an early stage and may occasionally misinterpret queries .
Competitive pricing
With an input rate of $1.25–$2.50 per million tokens and $10–$15 per million output tokens, Gemini 2.5 Pro delivers the best price-to-token ratio among the three. This makes it particularly attractive for high-volume, document-intensive applications—where long contexts drive token consumption more than raw performance metrics .with premium plans unlocking “Deep Think” budgets and higher throughput. Google AI Pro and Ultra subscriptions bundle access to Gemini 2.5 Pro alongside other tools like Veo video generation and NotebookLM.
Underlying Architectures and capabilities
OpenAI o3: Reflective reasoning at scale
OpenAI’s o3 is a reflective generative pre-trained transformer designed to devote additional deliberation time to step-by-step logical reasoning tasks. Architecturally, it builds on the transformer backbone of GPT-4 but incorporates a “thinking budget” mechanism: the model dynamically allocates more compute cycles to complex problems, creating internal chains of thought before generating outputs . This results in markedly improved performance in domains requiring multi-step reasoning, such as advanced mathematics, scientific inquiry, and code synthesis.
Claude Opus 4: Hybrid reasoning for extended workflows
Anthropic’s Claude Opus 4 is its most powerful model yet, optimized for coding and sustained agentic workflows. Like o3, it leverages a transformer core but introduces hybrid reasoning modes—near-instant responses (“fast think”) versus extended deliberation (“deep think”)—enabling it to maintain context over thousands of steps and hours of computation . This hybrid approach makes Opus 4 uniquely suited for long-running software engineering pipelines, multi-stage research tasks, and autonomous agent orchestration.
Gemini 2.5 Pro: Multimodal thinking with adaptive budgets
Google DeepMind’s Gemini 2.5 Pro extends Gemini’s native multimodality and reasoning abilities. It introduces “Deep Think,” an adaptive parallel-thinking mechanism that fans out subtasks across internal modules, synthesizing results into coherent responses . Gemini 2.5 Pro also boasts an exceptionally long context window—enabling it to ingest entire codebases, large datasets (text, audio, video), and design documents in a single pass—while providing fine-grained controls over thinking budgets for performance-cost trade-offs.
How do performance benchmarks compare across these models?
Academic and scientific reasoning
In a recent SciArena league table, o3 topped peers on technical reasoning questions evaluated by researchers, reflecting strong community trust in its scientific accuracy . Meanwhile, Claude Opus 4 demonstrated superior performance in agent-based benchmarks requiring sustained multi-hour problem solving, outperforming Sonnet models by up to 30% on TAU-bench and predictive reasoning tasks . Gemini 2.5 Pro leads many academic benchmarks as well, achieving #1 on LMArena for human preference measures and showing significant margins on math and science tests .
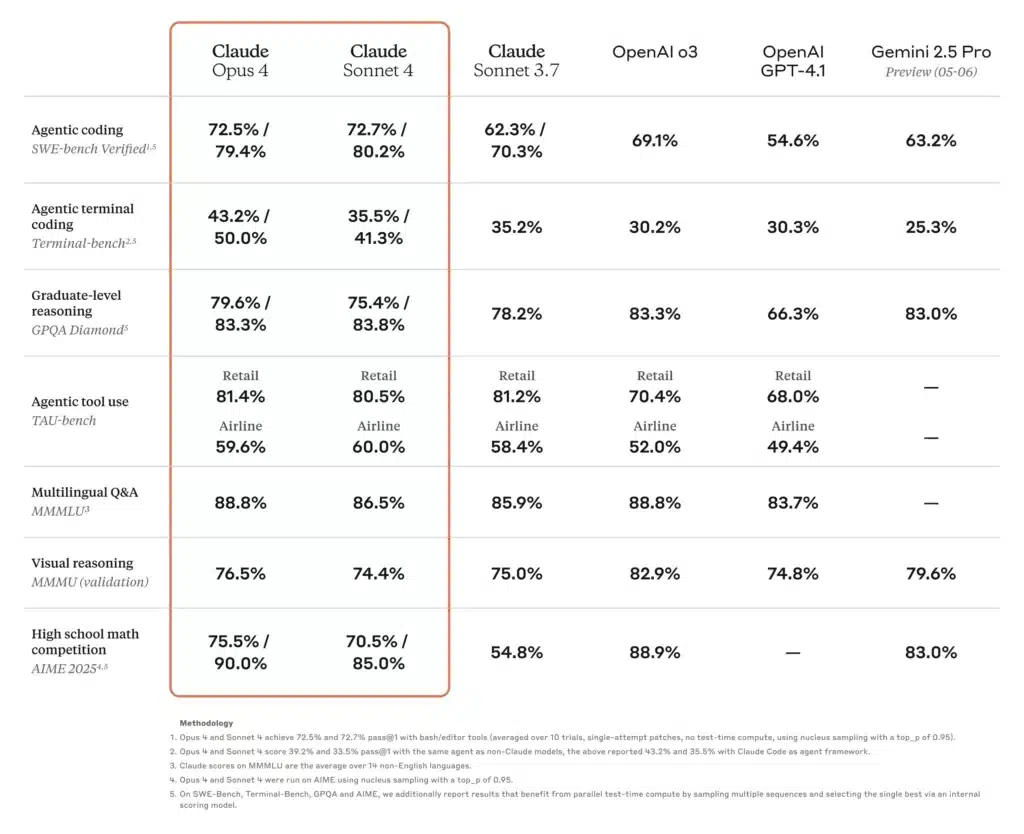
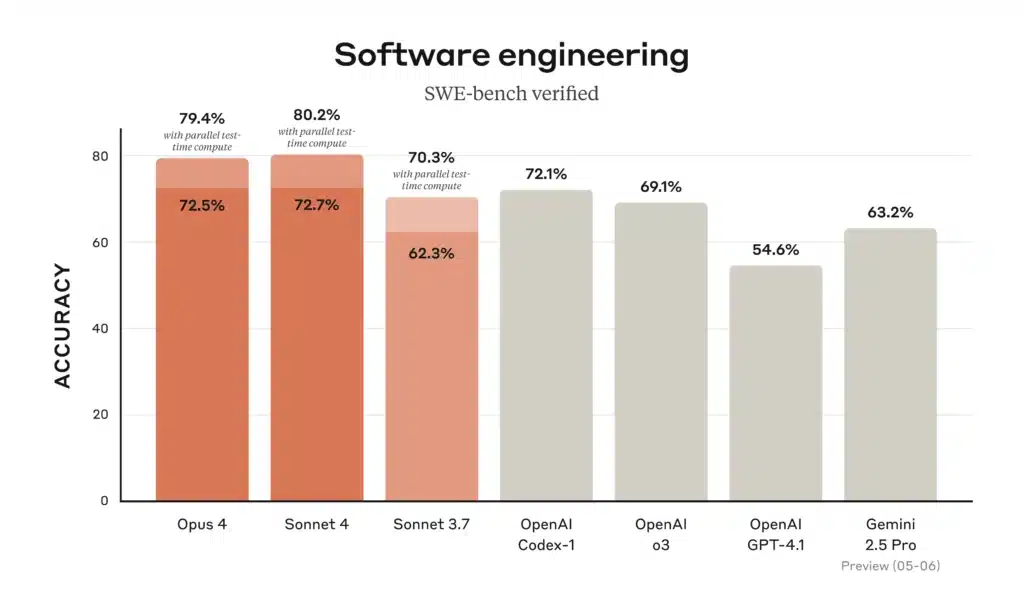
Coding and software engineering
On coding leaderboards, Gemini 2.5 Pro “tops the popular WebDev Arena” and leads common coding benchmarks, thanks to its ability to load and reason over entire repositories . Claude Opus 4 holds the title “world’s best coding model,” with 72.5% on SWE-bench and 43.2% on Terminal-bench—benchmarks focused on complex, long-running software tasks. o3 also excels in code synthesis and debugging, but falls slightly behind Opus 4 and Gemini in multi-step, large-scale engineering scenarios; nonetheless, its intuitive chain-of-thought makes it highly reliable for individual coding tasks .
Tool use and multimodal integration
Gemini 2.5 Pro’s multimodal design—processing text, images, audio, and video—gives it an edge in creative workflows such as interactive simulations, visual data analysis, and video storyboarding . Claude Opus 4’s agentic tool-use, including the Claude Code CLI and integrated file-system operations, excels in building autonomous pipelines across APIs and databases . o3 supports web browsing, file analysis, Python execution, and image reasoning, making it a versatile “Swiss Army knife” for mixed-format tasks, albeit with shorter context limits than Gemini 2.5 Pro.
How do these models compare in real-world coding scenarios?
When it comes to coding assistance, benchmarks tell only part of the story. Developers look for accurate code generation, refactoring prowess, and the ability to understand project context spread across multiple files.
Accuracy and hallucination rates
- Claude Opus 4 leads in hallucination avoidance, with fewer instances of non-existent API references or incorrect library signatures—key for mission-critical codebases. Its hallucination rate is reported at ~12% on extensive code audits versus ~18% for Gemini and ~20% for o3.
- Gemini 2.5 Pro excels at bulk transformations (e.g., migrating code patterns across tens of thousands of lines), thanks to its vast context window but occasionally struggles with subtle logic errors in large code blocks .
- OpenAI o3 remains the go-to for quick snippets, boilerplate generation, and interactive debugging due to its stable latency and high availability—but developers often cross-validate with another model to catch edge-case mistakes .
Tool and API ecosystem
- Both o3 and Gemini leverage extensive tooling—OpenAI’s function calling API and Google’s integrated Actions framework respectively—allowing seamless orchestration of data retrieval, database queries, and external API calls.
- Claude Opus 4 is being integrated into agentic frameworks like Claude Code (Anthropic’s CLI tool) and Amazon Bedrock, offering high-level abstractions for building autonomous workflows without manual orchestration .
Which model delivers the best price-to-performance ratio?
Balancing raw capabilities, context length, and cost yields different “best value” conclusions depending on workload characteristics.
High-volume, document-centric use cases
If processing vast corpora—such as legal repositories, scientific literature, or enterprise archives—Gemini 2.5 Pro often emerges as the winner. Its 1M-token window and price point of $1.25–$2.50 (input) and $10–$15 (output) tokens provide an unbeatable cost structure for long-context tasks .
Deep reasoning and multi-step workflows
When accuracy, chain-of-thought fidelity, and long-running agent capabilities matter—such as in financial modeling, legal compliance checks, or R&D pipelines—Claude Opus 4, despite its higher price, can reduce error-handling overhead and improve end-to-end throughput by minimizing re-runs and human review cycles .
Balanced enterprise adoption
For teams seeking reliable general-purpose performance without extreme scale, OpenAI o3 offers a middle ground. With broad API support, moderate pricing, and solid benchmark results, it remains a compelling choice for data science platforms, customer support automation, and early-stage product integrations .
Which AI model should you choose for your specific needs?
Ultimately, your ideal model depends on three primary factors:
- Scale of context: For workloads requiring massive input windows, Gemini 2.5 Pro dominates.
- Depth of reasoning: If your tasks involve multi-step logic and low tolerance for errors, Claude Opus 4 offers superior consistency.
- Cost sensitivity and ecosystem fit: For general-purpose tasks within the OpenAI stack—especially where integration with existing data pipelines matters—o3 presents a balanced, cost-effective option.
By evaluating your application’s token profile (input vs. output), tolerance for hallucinations, and tooling requirements, you can select the model that optimally aligns with both technical needs and budget constraints.
Here’s a side-by-side comparison chart summarizing the key specs, performance metrics, pricing, and ideal use cases for OpenAI o3, Anthropic Claude Opus 4, and Google Gemini 2.5 Pro:
| Feature / Metric | OpenAI o3 | Claude Opus 4 | Gemini 2.5 Pro |
|---|---|---|---|
| Context Window (inbound / outbound) | 200 K tokens / 200 K tokens | 200 K tokens / 32 K tokens | 1 048 576 tokens / 65 535 tokens |
| Throughput (tokens/sec) | ~37.6 | ~42.1 | ~83.7 |
| Avg. Latency | ~2.8 sec | ~3.5 sec | ~2.52 sec |
| Coding Benchmark (SWE-bench) | 69.1 % | 72.5 % | 63.2 % |
| Math Benchmark (AIME-2025) | 78.4 %¹ | 81.7 %¹ | 83.0 % |
| Hallucination Rate (code audits) | ~20 % | ~12 % | ~18 % |
| Multimodal Inputs | Text & code | Text & code | Text, code, images, audio, PDFs, video |
| “Chain-of-Thought” Support | Standard | Extended-thinking with summaries | Standard |
| Function-/Tool-Calling API | Yes (OpenAI Functions) | Yes (via Anthropic agents & Bedrock) | Yes (Google Actions) |
| Pricing (input tokens) | $2.00 / M tokens | $15.00 / M tokens | $1.25–$2.50 / M tokens |
| Pricing (output tokens) | $8.00 / M tokens | $75.00 / M tokens | $10–$15 / M tokens |
| Ideal Use Cases | General-purpose chatbots, customer support, quick code snippets | Deep reasoning, complex codebases, autonomous agents | Massive-scale document analysis, multimodal workflows |
AIME-2025 math scores for o3 and Opus 4 are approximate mid-range values based on reported benchmarks.
Getting Started
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
Developers can access Gemini 2.5 Pro,Claude Opus 4 and O3 API through CometAPI, the latest models version listed are as of the article’s publication date. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ultimately, the choice between OpenAI’s o3 series, Anthropic’s Claude Opus 4, and Google’s Gemini 2.5 Pro hinges on specific organizational priorities—be they top-tier technical performance, secure enterprise integration, or seamless multimodal consumer experiences. By aligning your use cases with each model’s strengths and ecosystem, you can harness the cutting edge of AI to drive innovation across research, development, education, and beyond.
Author’s note: As of July 31, 2025, each of these models continues to evolve, with frequent minor updates and ecosystem improvements. Always refer to the latest CometAPI API documentation and performance benchmarks before making a final decision.