

Seedream 4.0 — ByteDance’s newest image model — landed with a splash in the generative-AI world. It’s being hailed for professional-grade fidelity, unified generation + editing, multi-image consistency, and very fast inference times, and it’s already surfacing on partner platforms and model marketplaces.
What is Seedream 4.0?
Seedream 4.0 is the fourth-generation image model released by ByteDance’s Seed team. It unifies text-to-image generation and image editing in a single architecture, supports high-resolution outputs (up to 4K in vendor documentation), and handles complex multimodal prompts and multiple reference images for consistent visual identity across generated outputs. The model is explicitly targeted at creators, studios, and commercial workflows rather than casual mobile experiments, emphasizing speed, consistency, and precise control.
Emphasize:
- Single-step prompt editing and complex multimodal requests (generate + edit).
- Multi-reference support and batch input/output (upload several references and generate consistent variants).
- High fidelity text rendering and layout awareness for posters/infographics.
What modes does Seedream 4.0 support?
- Text-to-image generation (single-image and batch).
- Image editing / image-to-image (inpainting, structural edits, style transfer, attribute adjustments).
- Group / multi-image generation (create consistent sets of images from references or a seed).
- Reference-guided generation (accepts multiple reference images to maintain character or brand consistency).
What is the architecture behind Seedream 4.0?
Unified multimodal backbone (high level)
ByteDance describes Seedream 4.0 as an integrated architecture that combines prompt understanding (transformer-style encoders) with diffusion-like pixel refinement for final output, enabling both generation and fine-grained inpainting or instruction-based editing in the same model flow. The model is trained on mixed high-resolution photo, synthetic, and layout datasets to improve text handling and scene coherence.
Key architectural elements
- Prompt encoder / reasoning stack: converts plain-language instructions into structured goals (object edits, layout changes, style cues).
- Reference fusion module: ingests 1–multiple reference images and establishes appearance and composition constraints so generated outputs stay consistent across a set. (Many vendor listings mention support for multi-reference inputs — common practical limits range from 3–10 depending on the provider.)
- Diffusion-based renderer: refines pixels and enforces text-layout fidelity and fine detail (fonts, small text, iconography).
- Production tooling layer: APIs, batch generation, and “group” generation helpers let the same model produce multiple images with consistent identity (useful for brand sets and A/B creative).
Why does Seedream 4.0 dominate AI image-editing leaderboards?
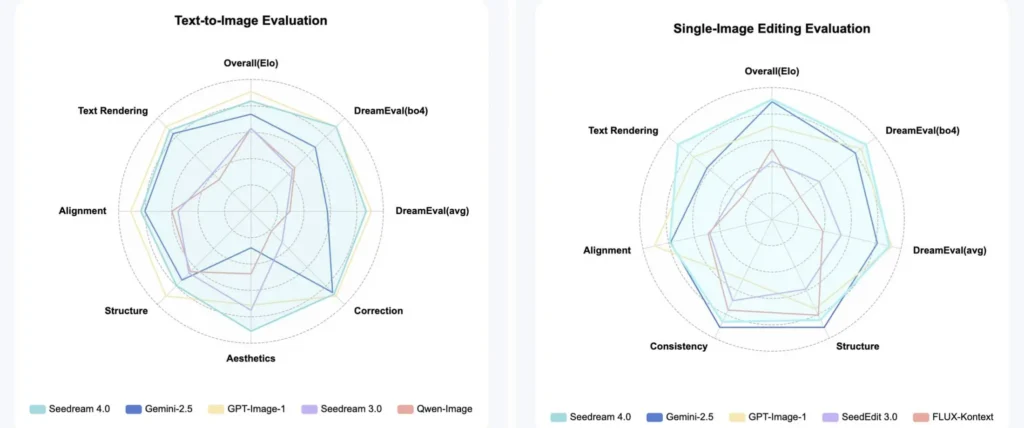
Seedream 4.0 has reported strong benchmark performance across both generation quality and edit fidelity. Independent evaluations and media coverage indicate it slightly outperforms very strong competitors (e.g., Google’s Nano Banana / Gemini-based image models) on composite benchmarks that assess realism, detail, and editing consistency. Real-world impressions emphasize how Seedream reduces the “uncanny valley” effect and produces highly plausible textures, anatomy, and scene composition — all crucial for perceived quality.
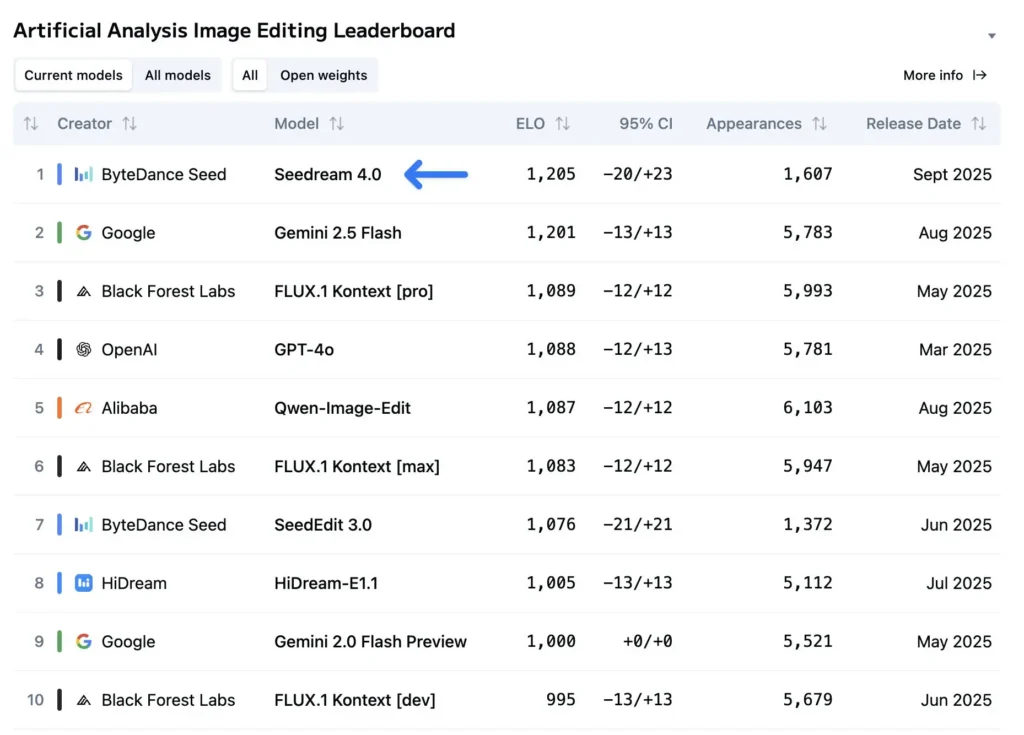
Leading comparative rankings for image generation and editing quality. I think three reasons for this quick rise:
- Prompt fidelity and edit alignment. Seedream 4.0’s editing head is tuned to obey textual edit commands while preserving the rest of the image — a historically thorny problem for image editors.
- Text rendering and layout accuracy. Where many models struggle with legible typography in images, Seedream 4.0 delivers sharper text and composition control, which is crucial for marketing assets.
- Speed + multi-reference consistency. Faster inference combined with the ability to condition on several references means teams can generate consistent batches quickly — a huge productivity boost.
How to Use the Seedream 4.0 API?
There are several ways to access Seedream 4.0: direct access through ByteDance’s Seed pages (where available), or via third-party marketplaces and API aggregators (CometAPI, Wavespeed, Fal.ai, Segmind, etc.). Below I’ll show practical curl and Python examples using a widely advertised aggregator pattern (CometAPI) and explain the parameters you’ll commonly need. Use this as a template — if you have direct credentials from ByteDance the request body and endpoints may differ slightly but the principles are the same.
Example — cURL (CometAPI style)
curl --location --request POST 'https://api.cometapi.com/v1/images/generations' \
--header 'Authorization: Bearer YOUR_COMETAPI_KEY' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "bytedance-seedream-4-0-250828",
"prompt": "A cinematic close-up portrait of a young woman, golden hour lighting, film grain, shallow depth of field",
"image": "https://example.com/reference1.jpg",
"size": "2K",
"response_format": "url",
"enable_sync_mode": true,
"watermark": false
}'
This pattern follows the example payload commonly published by API aggregators, and shows useful toggles: enable_sync_mode (wait for image and return directly), response_format (url or base64), and size.
Important API knobs to watch
- Model parameter / model id — required to choose the Seedream 4.0 variant.
- prompt — natural language description or edit instruction.
- image(s) — single URL or list of URLs used as references.
- size — 2K / 4K / custom pixels depending on vendor support.
- response_format — URL or base64. Useful for embedding directly versus hosting a returned URL.
- sync vs async / stream — synchronous returns are easier for small jobs; asynchronous jobs + webhooks scale better for batch pipelines.
What are quick troubleshooting tips for common API issues?
- 403 / auth errors: ensure API key is correct and in Authorization header; check that the key has permission for the Seedream model.
- Slow responses or timeouts: use async job endpoints if available; check provider’s recommended
enable_sync_modeand use a polling pattern. - Poor text rendering / unreadable labels: offload text to design overlays or request vector/SVG render steps where available.
- Inconsistent character across batches: pass more reference images and use seed values or synchronous reproducible modes.
Getting Started
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
Developers can access Seedream 4.0 through CometAPI,the latest model version is always updated with the official website. To begin, explore the model’s capabilities in the Playground and consult the Seedream 4.0 API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
Conclusion
Seedream 4.0 represents a practical inflection in image models: the bar has shifted from “can we make something cool” to “can we integrate this reliably into production workflows?” With its combined generation/editing architecture, multi-reference consistency, and improved text/layout handling, Seedream is already being adopted across playgrounds and API providers. If you’re evaluating adoption, begin with a small pilot (3–5 common marketing templates), measure iteration velocity and final human revision time, and use those metrics to decide how quickly to scale the model into daily creative operations.