

On November 19–20, 2025 OpenAI released two related but distinct upgrades: GPT-5.1-Codex-Max, a new agentic coding model for Codex that emphasizes long-horizon coding, token efficiency, and “compaction” to sustain multi-window sessions; and GPT-5.1 Pro, an updated Pro-tier ChatGPT model tuned for clearer, more capable answers in complex, professional work.
What is GPT-5.1-Codex-Max and what problem is it trying to solve?
GPT-5.1-Codex-Max is a specialized Codex model from OpenAI tuned for coding workflows that require sustained, long-horizon reasoning and execution. Where ordinary models can be tripped up by extremely long contexts — for example, multi-file refactors, complex agent loops, or persistent CI/CD tasks — Codex-Max is designed to automatically compact and manage session state across multiple context windows, enabling it to continue working coherently as a single project spans many thousands (or more) of tokens. OpenAI positions Codex-Max as the next step in making code-capable agents genuinely useful for extended engineering work.
What is GPT-5.1-Codex-Max and what problem is it trying to solve?
GPT-5.1-Codex-Max is a specialized Codex model from OpenAI tuned for coding workflows that require sustained, long-horizon reasoning and execution. Where ordinary models can be tripped up by extremely long contexts — for example, multi-file refactors, complex agent loops, or persistent CI/CD tasks — Codex-Max is designed to automatically compact and manage session state across multiple context windows, enabling it to continue working coherently as a single project spans many thousands (or more) of tokens.
It’s described by OpenAI as “faster, more intelligent, and more token-efficient at every stage of the development cycle,” and is explicitly intended to replace GPT-5.1-Codex as the default model in Codex surfaces.
Feature snapshot
- Compaction for multi-window continuity: prunes and preserves critical context to work coherently over millions of tokens and hours. 0
- Improved token efficiency compare to GPT-5.1-Codex: up to ~30% fewer thinking tokens for similar reasoning effort on some code benchmarks.
- Long-horizon agentic durability: internally observed to sustain multi-hour/multi-day agent loops (OpenAI documented >24-hour internal runs).
- Platform integrations: available today inside Codex CLI, IDE extensions, cloud, and code review tools; API access forthcoming.
- Windows environment support: OpenAI specifically notes Windows is supported for the first time in Codex workflows, expanding real-world developer reach.
How does it compare to competing products (e.g., GitHub Copilot, other coding AIs)?
GPT-5.1-Codex-Max is pitched as a more autonomous, long-horizon collaborator compared with per-request completion tools. While Copilot and similar assistants excel at near-term completions within the editor, Codex-Max’s strengths are in orchestrating multi-step tasks, maintaining coherent state across sessions, and handling workflows that require planning, testing, and iteration. That said, the best approach in most teams will be hybrid: use Codex-Max for complex automation and sustained agent tasks and use lighter-weight assistants for line-level completions.
How does GPT-5.1-Codex-Max work?
What is “compaction” and how does it enable long-running work?
A central technical advance is compaction—an internal mechanism that prunes session history while preserving the salient pieces of context so the model can continue coherent work across multiple context windows. Practically, that means Codex sessions approaching their context limit will be compacted (older or lower-value tokens summarized/preserved) so the agent has a fresh window and can continue iterating repeatedly until the task completes. OpenAI reports internal runs where the model worked on tasks continuously for more than 24 hours.
Adaptive reasoning and token efficiency
GPT-5.1-Codex-Max applies improved reasoning strategies that make it more token-efficient: in OpenAI’s reported internal benchmarks, the Max model achieves similar or better performance than GPT-5.1-Codex while using significantly fewer “thinking” tokens—OpenAI cites roughly 30% fewer thinking tokens on SWE-bench Verified when running at equal reasoning effort. The model also introduces an “Extra High (xhigh)” reasoning effort mode for non-latency-sensitive tasks that allows it to expend more internal reasoning to get higher-quality outputs.
System integrations and agentic tooling
Codex-Max is being distributed within Codex workflows (CLI, IDE extensions, cloud, and code review surfaces) so that it can interact with actual developer toolchains. Early integrations include the Codex CLI and IDE agents (VS Code, JetBrains, etc.), with API access planned to follow. The design goal is not only smarter code synthesis but an AI that can run multi-step workflows: open files, run tests, fix failures, refactor, and re-run.
How does GPT-5.1-Codex-Max perform on benchmarks and real work?
Sustained reasoning and long-horizon tasks
Evaluations point to measurable improvements in sustained reasoning and long-horizon tasks:
- OpenAI internal evaluations: Codex-Max can work on tasks for “more than 24 hours” in internal experiments and that integrating Codex with developer tooling increased internal engineering productivity metrics (e.g., usage and pull request throughput). These are OpenAI’s internal claims and indicate task-level improvements in real-world productivity.
- Independent evaluations (METR): METR’s independent report measured the observed 50% time horizon (a statistic representing the median time the model can coherently sustain a long task) for GPT-5.1-Codex-Max at about 2 hours 40 minutes (with a wide confidence interval), up from GPT-5’s 2 hours 17 minutes in comparable measurements — a meaningful on-trend improvement in sustained coherence. METR’s methodology and CI emphasize variability, but the result supports the narrative that Codex-Max improves practical long-horizon performance.
Code Benchmarks
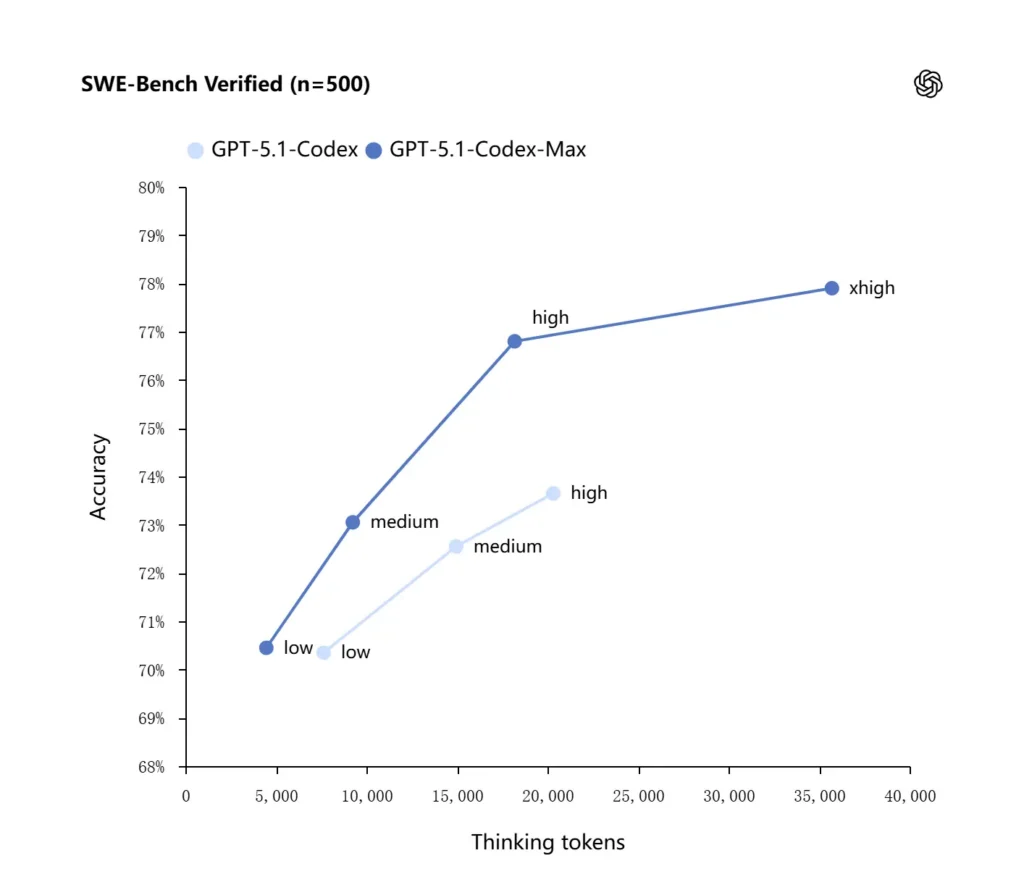
OpenAI reports improved results on frontier coding evaluations, notably SWE-bench Verified where GPT-5.1-Codex-Max outperforms GPT-5.1-Codex with better token efficiency. The company highlights that for the same “medium” reasoning effort the Max model produces better results while using roughly 30% fewer thinking tokens; for users who permit longer internal reasoning, the xhigh mode can further elevate answers at the cost of latency.
| GPT‑5.1-Codex (high) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench Verified (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
How does GPT-5.1-Codex-Max compare to GPT-5.1-Codex?
Performance and purpose differences
- Scope: GPT-5.1-Codex was a high-performance coding variant of the GPT-5.1 family; Codex-Max is explicitly an agentic, long-horizon successor meant to be the recommended default for Codex and Codex-like environments.
- Token efficiency: Codex-Max shows material token efficiency gains (OpenAI’s ~30% fewer thinking tokens claim) on SWE-bench and in internal usage.
- Context management: Codex-Max introduces compaction and native multi-window handling to sustain tasks that exceed a single context window; Codex did not natively provide this capability at the same scale.
- Tooling readiness: Codex-Max ships as the default Codex model across the CLI, IDE, and code review surfaces, signaling a migration for production developer workflows.
When to use which model?
- Use GPT-5.1-Codex for interactive coding assistance, quick edits, small refactors, and lower-latency use cases where the entire relevant context easily fits in a single window.
- Use GPT-5.1-Codex-Max for multi-file refactors, automated agentic tasks that require many iteration cycles, CI/CD-like workflows, or when you need the model to hold a project-level perspective across many interactions.
Practical prompt patterns, and examples for best results?
Prompting patterns that work well
- Be explicit about goals and constraints: “Refactor X, preserve public API, keep function names, and ensure tests A,B,C pass.”
- Provide minimal reproducible context: link to the failing test, include stack traces, and relevant file snippets rather than dumping entire repositories. Codex-Max will compact history as needed.
- Use stepwise instructions for complex tasks: break large jobs into a sequence of subtasks, and let Codex-Max iterate through them (e.g., “1) run tests 2) fix top 3 failing tests 3) run linter 4) summarize changes”).
- Ask for explanations and diffs: request both the patch and a short rationale so human reviewers can quickly assess safety and intent.
Example prompt templates
Refactor task
“Refactor the
payment/module to extract payment processing intopayment/processor.py. Keep public function signatures stable for existing callers. Create unit tests forprocess_payment()that cover success, network failure, and invalid card. Run the test suite and return failing tests and a patch in unified diff format.”
Bugfix + test
“A test
tests/test_user_auth.py::test_token_refreshfails with traceback . Investigate root cause, propose a fix with minimal changes, and add a unit test to prevent regression. Apply patch and run tests.”
Iterative PR generation
“Implement feature X: add endpoint
POST /api/exportwhich streams export results and is authenticated. Create the endpoint, add docs, create tests, and open a PR with summary and checklist of manual items.”
For most of these, start with medium effort; switch to xhigh when you need the model to do deep reasoning across many files and multiple test iterations.
How do you access GPT-5.1-Codex-Max
Where it’s available today
OpenAI has integrated GPT-5.1-Codex-Max into Codex tooling today: the Codex CLI, IDE extensions, cloud, and code-review flows use Codex-Max by default (you can opt for Codex-Mini). API availability is to be prepared ; GitHub Copilot has public previews that include GPT-5.1 and Codex series models.
Developers can access GPT-5.1-Codex-Max and GPT-5.1-Codex API through CometAPI. To begin, explore the model capabilities ofCometAPI in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!
Quick start (practical step-by-step)
- Make sure you have access: confirm your ChatGPT/Codex product plan (Plus, Pro, Business, Edu, Enterprise) or your developer API plan supports GPT-5.1/Codex family models.
- Install Codex CLI or IDE extension: if you want to run code tasks locally, install the Codex CLI or the Codex IDE extension for VS Code / JetBrains / Xcode as applicable. The tooling will default to GPT-5.1-Codex-Max in supported setups.
- Choose reasoning effort: start with medium effort for most tasks. For deep debugging, complex refactors, or when you want the model to think harder and you don’t care about response latency, switch to high or xhigh modes. For quick small fixes, low is reasonable.
- Provide repository context: give the model a clear starting point — a repo URL or a set of files and a short instruction (e.g., “refactor the payment module to use async I/O and add unit tests, keep function-level contracts”). Codex-Max will compact history as it approaches context limits and continue the job.
- Iterate with tests: after the model produces patches, run test suites and feed back failures as part of the ongoing session. Compaction and multi-window continuity let Codex-Max retain important failing test context and iterate.
Conclusion:
GPT-5.1-Codex-Max represents a substantial step toward agentic coding assistants that can sustain complex, long-running engineering tasks with improved efficiency and reasoning. The technical advances (compaction, reasoning effort modes, Windows environment training) make it exceptionally well suited to modern engineering organizations — provided teams pair the model with conservative operational controls, clear human-in-the-loop policies, and robust monitoring. For teams that adopt it carefully, Codex-Max has the potential to shift how software is designed, tested, and maintained — turning repetitive engineering grunt work into a higher-value collaboration between humans and models.