

Kimi K2 Thinking is Moonshot AI’s new “thinking” variant of the Kimi K2 family: a trillion-parameter, sparse Mixture-of-Experts (MoE) model that is explicitly engineered to think while acting — i.e., to interleave deep chain-of-thought reasoning with reliable tool calls, long-horizon planning, and automated self-checks. It combines a large sparse backbone (≈1T total parameters, ~32B activated per token), a native INT4 quantization pipeline, and a design that scales inference-time reasoning (more “thinking tokens” and more tool-call rounds) rather than merely growing static parameter counts.
In plain terms: K2 Thinking treats the model as a problem-solving agent instead of a one-shot language generator. That shift — from “language model” to “thinking model” — is what makes this release notable and why many practitioners are framing it as a milestone in open-source agentic AI.
What exactly is “Kimi K2 Thinking”?
Architecture and key specifications
K2 Thinking is built as a sparse MoE model (384 experts, 8 experts selected per token) with about 1 trillion total parameters and ~32B activated parameters per inference. It uses hybrid architectural choices (MLA attention, SwiGLU activations) and was trained with Moonshot’s Muon/MuonClip optimizer on large token budgets described in their technical report. The thinking variant extends the base model with post-training quantization (native INT4 support), a 256k context window, and engineering to expose and stabilize the model’s internal reasoning trace during real use.
What “thinking” means in practice
“Thinking” here is an engineering goal: enable the model to (1) generate long, structured chains of internal reasoning (chain-of-thought tokens), (2) call external tools (search, python sandboxes, browsers, databases) as part of that reasoning, (3) evaluate and self-verify intermediate claims, and (4) iterate across many such cycles without collapsing coherence. Moonshot’s documentation and model card show K2 Thinking explicitly trained and tuned to interleave reasoning and function calls, and to retain stable agentic behavior across hundreds of steps.
What is the core objective
The limitations of traditional large-scale models are:
- The generation process is short-sighted, lacking cross-step logic;
- Tool usage is limited (usually only external tools can be called once or twice);
- They cannot self-correct in complex problems.
K2 Thinking’s core design goal is to solve these three problems. In practice, K2 Thinking can, without human intervention: execute 200–300 consecutive tool calls; maintain hundreds of steps of logically coherent reasoning; solve complex problems through contextual self-checking.
Repositioning: language model → thinking model
The K2 Thinking project illustrates a broader strategic shift in the field: moving beyond conditional text generation toward agentic problem solvers. The core objective is not primarily to improve perplexity or next-token prediction but to make models that can:
- Plan their own multi-step strategies;
- Coordinate external tools and effectors (search, code execution, knowledge bases);
- Verify intermediate results and correct mistakes;
- Sustain coherence across long contexts and long tool chains.
This reframing changes both evaluation (benchmarks emphasize processes and outcomes, not just text quality) and engineering (structures for tool routing, step counting, self-critique, etc.).
Working methods: how thinking models operate
In practice, K2 Thinking demonstrates several working methods that typify the “thinking model” approach:
- Persistent internal traces: The model produces structured intermediate steps (reasoning traces) that are kept in context and can be re-used or audited later.
- Dynamic tool routing: Based on each internal step, K2 decides which tool to call (search, code interpreter, web browser) and when to call it.
- Test-time scaling: During inference, the system can expand its “thinking depth” (more internal reasoning tokens) and increase the number of tool calls to better explore solutions.
- Self-verification and recovery: The model explicitly checks results, runs sanity tests, and re-plans when checks fail.
These methods combine model architecture (MoE + long context) with system engineering (tool orchestration, safety checks).
What technological innovations enable Kimi K2 Thinking?
Kimi K2 Thinking’s Reasoning mechanism Supports interleaved thinking and tool usage.The K2 Thinking reasoning loop:
- Understanding the problem (parse & abstract)
- Generating a multi-step reasoning plan (plan chain)
- Utilizing external tools (code, browser, math engine)
- Verifying and revising the results (verify & revise)
- Conclude reasoning (conclude reasoning)
Below, I will introduce three key techniques that make the reasoning loops in xx possible.
1) Test-time Scaling
What it is: Traditional “Scaling Laws” focus on increasing the number of parameters or data during training. K2 Thinking’s innovation lies in: Dynamically expanding the number of tokens (i.e., depth of thought) during the “reasoning phase”; Simultaneously expanding the number of tool calls (i.e., breadth of action). This method is called test-time scaling, and its core assumption is: “A longer reasoning chain + more interactive tools = a qualitative leap in actual intelligence.”
Why it matters: K2 Thinking explicitly optimizes for this: Moonshot shows that expanding “thinking tokens” and the number/depth of tool calls yields measurable improvements in agentic benchmarks, letting the model outperform other models of similar or larger size in FLOPs-matched scenarios.
2) Tool-Augmented Reasoning
What it is: K2 Thinking was engineered to natively parse tool schemas, decide autonomously when to call a tool, and incorporate tool results back into its ongoing reasoning stream. Moonshot trained and tuned the model to interleave chain-of-thought with function calls, then stabilized this behavior across hundreds of sequential tool steps.
Why it matters: That combination — reliable parsing + stable internal state + API tooling — is what enables the model to do web browsing, run code, and orchestrate multi-stage workflows as part of a single session.
Within its internal architecture, the model forms a “visualized thought process” execution trajectory: prompt → reasoning tokens → tool call → observation → next reasoning → final answer
3) Long-horizon Coherence & Self-verification
What it is: Long-horizon coherence is the model’s ability to keep a coherent plan and internal state across many steps and over very long contexts . Self-verification means the model proactively checks its intermediate outputs and reruns or revises steps when a verification fails. Long tasks often cause models to drift or hallucinate. K2 Thinking tackles this with multiple techniques: very long context windows (256k), training strategies that preserve state across long CoT sequences, and explicit sentence-level faithfulness/judge models to detect unsupported claims.
Why it matters: The “Recurrent Reasoning Memory” mechanism maintains the persistence of the reasoning state, giving it human-like “thinking stability” and “contextual self-supervision” characteristics.. As tasks stretch over many steps (e.g., research projects, multi-file coding tasks, long editorial processes), maintaining a single coherent thread becomes essential. Self-verification reduces silent failures; rather than returning a plausible but incorrect answer, the model can detect inconsistencies and re-consult tools or re-plan.
Capabilities:
- Contextual Consistency: Maintains semantic continuity across 10k+ tokens;
- Error Detection & Rollback: Identifies and corrects logical deviations in early thought processes;
- Self-verification Loop: Automatically verifies the reasonableness of the answer after reasoning is complete;
- Multi-path reasoning merging: Selects the optimal path from multiple logical chains.
What are the four core capabilities of K2 Thinking?
Deep & Structured Reasoning
K2 Thinking is tuned to generate explicit, multi-stage reasoning traces and to use them to reach robust conclusions. The model shows strong scores on math and rigorous reasoning benchmarks (GSM8K, AIME, IMO-style benchmarks) and demonstrates an ability to keep reasoning intact over long sequences — a basic requirement for research-grade problem solving. Its excellent performance on Humanity’s Last Exam (44.9%) demonstrates expert-level analytical capabilities. It can extract logical frameworks from fuzzy semantic descriptions and generate reasoning graphs.
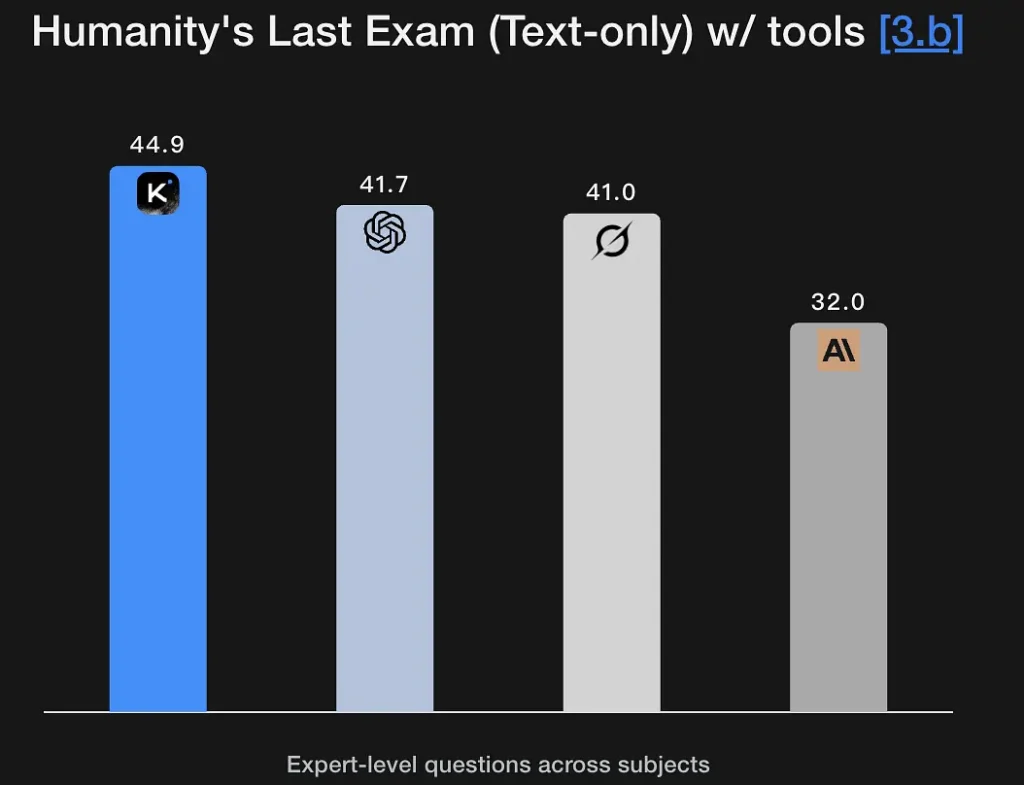
Key Features:
- Supports Symbolic Reasoning: Understands and operates on mathematical, logical, and programming structures.
- Possesses Hypothesis Testing Capabilities: Can spontaneously propose and verify hypotheses.
- Can Perform Multi-Stage Problem Decomposition: Breaks down complex objectives into multiple sub-tasks.
Agentic Search
Instead of a single retrieval step, agentic search lets the model plan a search strategy (what to look for), execute it via repeated web/tool calls, synthesize the incoming results, and refine the query. K2 Thinking’s BrowseComp and Seal-0 tool-enabled scores indicate strong performance on this capability; the model is explicitly designed to sustain multi-round web searches with stateful planning.
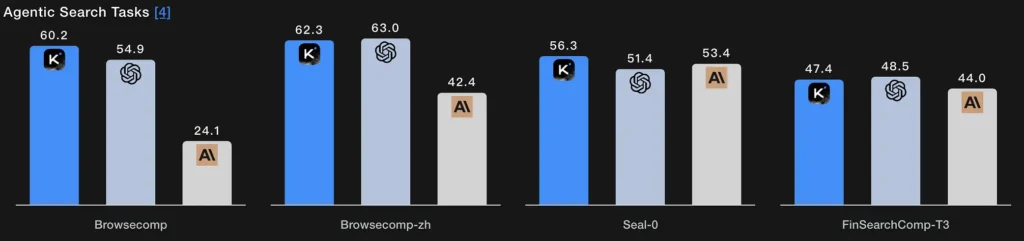
Technical essence:
- The search module and language model form a closed loop: query generation → webpage retrieval → semantic filtering → reasoning fusion.
- The model can adaptively adjust its search strategy, for example, searching for definitions first, then data, and finally verifying hypotheses.
- Essentially, it is a composite intelligence of “information retrieval + understanding + argumentation”.
Agentic Coding
This is the ability to write, execute, test, and iterate on code as part of a reasoning loop. K2 Thinking posts competitive results on live coding and code-verification benchmarks, supports Python toolchains in its tool calls, and can run multi-step debugging loops by calling a sandbox, reading errors, and repairing code across repeated passes. Its EvalPlus/LiveCodeBench scores reflect these strengths. Achieving a 71.3% score in the SWE-Bench Verified test means it can correctly complete over 70% of real-world software repair tasks.
It also demonstrates stable performance in the LiveCodeBench V6 competition environment, showcasing its algorithm implementation and optimization capabilities.

Technical essence:
- It adopts a process of “semantic parsing + AST-level refactoring + automatic verification”;
- Code execution and testing are achieved through tool calls at the execution layer;
- It realizes a closed-loop automated development from understanding code → diagnosing errors → generating patches → verifying success.
Agentic Writing
Beyond creative prose, agentic writing is structured, goal-directed document production that may require external research, citation, table generation, and iterative refinement (e.g., produce a draft → fact-check → revise). K2 Thinking’s long-context and tool orchestration make it well suited for multi-stage writing workflows (research briefs, regulations summaries, multi-chapter content). The model’s open-ended win rates on Arena-style tests and longform writing metrics support that claim.
Technical essence:
- Automatically generates text segments using agentic thought planning;
- Internally controls text logic through reasoning tokens;
- Can simultaneously invoke tools such as search, calculation, and chart generation to achieve “multimodal writing”.
How can you use K2 Thinking today?
Modes of access
K2 Thinking is available as an open-source release (model weights and checkpoints) and through platform endpoints and community hubs (Hugging Face, Moonshot platform). You can self-host if you have sufficient compute, or use CometAPI’s API/hosted UI for faster onboarding. it also documents a reasoning_content field that surfaces the internal thought tokens to the caller when enabled.
Practical tips for usage
- Start with agentic building blocks: expose a small set of deterministic tools first (search, python sandbox, and a trustworthy facts DB). Provide clear tool schemas so the model can parse/validate calls.
- Tune test-time compute: for hard problem solving, allow longer thinking budgets and more tool-call rounds; measure how quality improves versus latency/cost. Moonshot champions test-time scaling as a primary lever.
- Use INT4 modes for cost efficiency: K2 Thinking supports INT4 quantization, which offers meaningful speedups; but validate edge-case behavior on your tasks.
- Surface reasoning content carefully: exposing internal chains can help debugging, but also increases exposure to raw model mistakes. Treat internal reasoning as diagnostic not authoritative; pair it with automated verification.
Conclusion
Kimi K2 Thinking is a deliberately engineered answer to the next era of AI: not just bigger models, but agents that think, act, and verify. It brings together MoE scaling, test-time compute strategies, native low-precision inference, and explicit tool orchestration to enable sustained, multi-step problem solving. For teams who need multi-step problem solving and have the engineering discipline to integrate, sandbox, and monitor agentic systems, K2 Thinking is a major, usable step forward — and an important stress-test for how industry and society will govern increasingly capable, action-oriented AI.
Developers can access Kimi K2 Thinking API through CometAPI, the latest model version is always updated with the official website. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!