

In der sich rasant weiterentwickelnden Welt der KI-Coding-Assistenten sticht die Veröffentlichung von Kimi K2.7 Code am 12. Juni 2026 als bedeutender Schritt für Entwickler, KI-Agenten und Unternehmen hervor, die leistungsstarke, kosteneffiziente und Open-Source-Lösungen suchen.
Dieses spezialisierte Coding-Modell baut auf der K2-Familie auf und legt den Schwerpunkt auf langfristige Software-Engineering-Aufgaben über viele Schritte, verlässliche Befolgung von Anweisungen in massiven Kontexten, mehrstufige Tool-Aufrufe, Bild-/Videoeingaben und strukturierte Ausgaben für agentenorientierte Workflows. Mit insgesamt 1 Billion Parametern, aber nur 32 Milliarden aktivierten pro Token dank eines Mixture-of-Experts-(MoE)-Designs liefert es Fähigkeiten auf Frontier-Niveau zu einem Bruchteil der Kosten geschlossener Modelle wie Claude Opus 4.8 oder GPT-5.5.
CometAPI hat nun Kimi K2.7 Code integriert und macht es über einen einzigen OpenAI-kompatiblen Endpunkt nahtlos zugänglich – zu einem niedrigeren Preis als der offizielle. Diese Integration ermöglicht es Entwicklern, Modelle mühelos zu wechseln, Kosten zu optimieren und robuste KI-gestützte Anwendungen zu bauen, ohne mehrere Anbieter managen zu müssen.
Was ist Kimi K2.7 Code?
Kimi K2.7 Code (auch bezeichnet als Kimi-K2.7-Code oder kimi-k2.7-code) ist ein auf Coding fokussiertes, agentisches Mixture-of-Experts-(MoE)-Modell von Moonshot AI. Es ist ausdrücklich für langfristige Software-Engineering-Aufgaben gebaut – Szenarien, in denen eine KI über Tausende Schritte Kontext halten, Repositories navigieren, Tools aufrufen, Code über Module hinweg editieren, Tests ausführen, debuggen und bis zur Fertigstellung iterieren muss.
Wesentliche Merkmale:
- Offene Gewichte auf Hugging Face (
moonshotai/Kimi-K2.7-Code). - Modifizierte MIT-Lizenz – permissiv für kommerzielle Nutzung mit Namensnennungsanforderungen bei Bereitstellungen mit hohem Volumen.
- Native Multimodal-Unterstützung – Text + Bild + Video über den MoonViT-Encoder (~400 Mio. Parameter).
- Stets aktiver Reasoning-Modus – obligatorisch für zuverlässige agentische Performance; kann nicht deaktiviert werden.
Im Gegensatz zu allgemeinen Chat-Modellen ist K2.7 Code auf Zuverlässigkeit in langen Sitzungen abgestimmt. Es reduziert „Overthinking“ (übermäßige interne Reasoning-Tokens) gegenüber K2.6 um etwa 30 %, was zu geringeren Kosten, schnelleren Iterationen und höheren End-to-End-Erfolgsraten in komplexen Workflows führt.
Damit ist es ideal für:
- Refactorings im Repository-Maßstab.
- Mehrsprachen-Codegenerierung (Python, Rust, Go usw.).
- Agentenbasierte Tool-Nutzung (MCP, CI/CD, Dateisystemoperationen).
- Frontend-, DevOps-, Performance-Optimierung und ML-Engineering-Aufgaben.
Was ist neu in Kimi K2.7 Code?
1) Stärkeres langfristiges Codieren
Das größte Upgrade ist die bessere Leistung bei langfristigen Coding-Aufgaben. Moonshot sagt, dass K2.7 Code den End-to-End-Erfolg über komplexe Software-Engineering-Workflows hinweg verbessert – nicht nur beim One-Shot-Code-Completion. Das ist die Art von Upgrade, die Entwickler bemerken, wenn ein Modell den Faden eines Projekts über viele Turns hinweg hält, anstatt nach den ersten Schritten abzudriften.
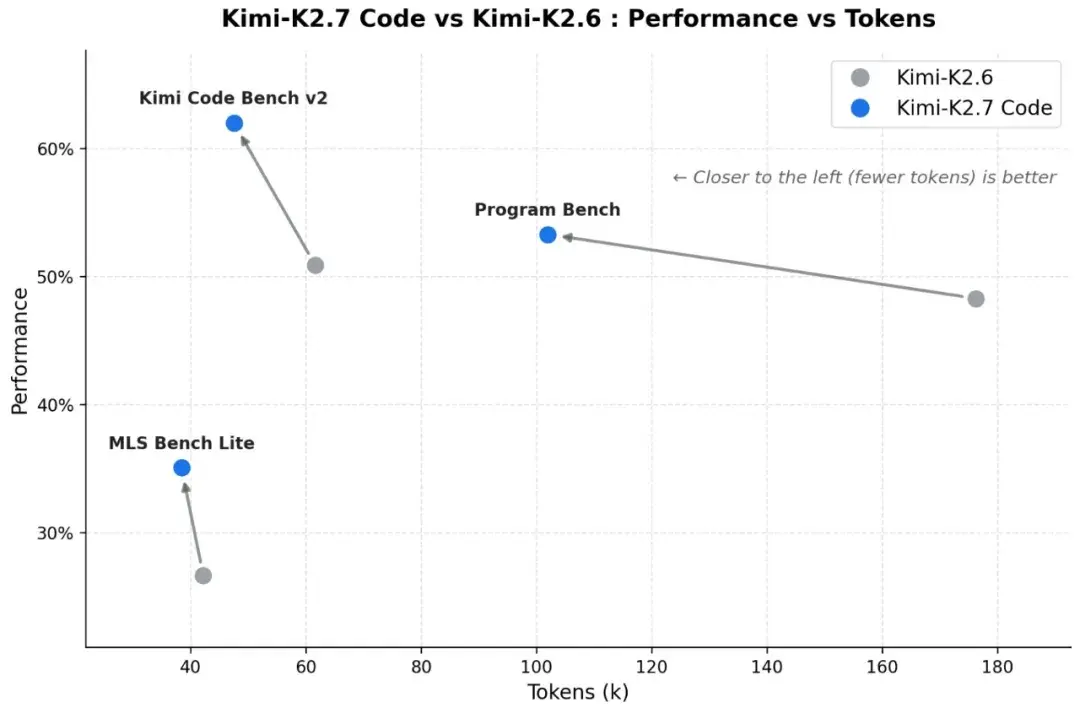
Deutliche Benchmark-Gewinne gegenüber K2.6:
- +21.8% auf Kimi Code Bench v2 (62.0% vs. 50.9%)
- +11.0% auf Program Bench (53.6% vs. 48.3%)
- +31.5% auf MLS Bench Lite (35.1% vs. 26.7%)
- +9.3% auf Kimi Claw 24/7 Bench
- +9.5% auf MCP Atlas
- +11.4% auf MCP Mark Verified (81.1% vs. 72.8%)
2) Bessere Reasoning-Effizienz
Moonshot berichtet, dass K2.7 Code etwa 30 % weniger Thinking-/Reasoning-Tokens als K2.6 nutzt. Cloudflares Workers AI Changelog bestätigt diese Effizienzbehauptung und fügt hinzu, dass geringerer Reasoning-Token-Verbrauch die Inferenzkosten bei reasoning-intensiven Workloads senken kann. Einfach gesagt: Das Modell ist nicht nur bei Coding-Aufgaben smarter, sondern denkt auch wirtschaftlicher.
3) Standardmäßiger Reasoning-Modus
Kimi K2.7 Code ist ausschließlich ein Thinking-Modell. Moonshot sagt, dass ein Nicht-Thinking-Modus nicht unterstützt wird, und in Kimi Code greift das System automatisch auf K2.6 zurück, wenn Thinking deaktiviert ist. Das ist ein nützliches Detail für Teams, die agentische Coding-Tools bauen, denn es bedeutet, dass ihr Reasoning als Standard einplanen solltet.
4) Erweiterte Long-Horizon-Fähigkeiten:
Bessere Generalisierung über Sprachen (Python, Rust, Go usw.) und Szenarien (Frontend, DevOps, Security, ML). Höhere End-to-End-Aufgabenerfolgsraten.
5) Verbesserte Multimodalität und Tool-Nutzung
Vision-Encoder (400 Mio. Parameter) für Bilder/Videos; nahtlose MCP/Tool-Integration für reale Umgebungen (GitHub, Postgres, Browser usw.).
Architektur und Parameter von Kimi K2.7 Code
Kimi K2.7 Code verwendet eine Mixture-of-Experts-Architektur. Laut offiziellem Model Card auf Hugging Face hat es 1T Gesamtparameter und 32B aktivierte Parameter. Es umfasst 61 Layer, 384 Experten, 8 ausgewählte Experten pro Token, 1 Shared Expert, MLA-Attention, SwiGLU-Aktivierung, ein 160K-Vokabular und 256K Kontextlänge. Der Vision-Encoder ist MoonViT mit 400 Mio. Parametern.
Diese Architektur erklärt die Attraktivität des Modells. Ein MoE-Modell mit einer Billion Parametern kann eine enorme Kapazitätsdecke bewahren, während pro Token nur ein Teil der Parameter aktiviert wird – ein Grund, weshalb MoE-Systeme für leistungsfähige Inferenz attraktiv sind. K2.7 Code übernimmt denselben nativen INT4-Quantisierungsansatz wie K2 Thinking, was die Bereitstellungseffizienz verbessert.
Auch das Kontextfenster ist ein großer Pluspunkt. Die offiziellen Docs beschreiben ein 256K-Fenster – groß genug für umfangreiche Codebasen, lange Unterhaltungen und mehrstufige Agentensitzungen, in denen Kontextbeibehaltung geschäftskritisch ist.
K2.7 Code teilt das gleiche verschachtelte Thinking- und Multi-Step-Tool-Call-Design wie K2 Thinking und empfiehlt die Kimi Code CLI als das am besten passende Agenten-Framework. Das ist ein starkes Signal, dass Moonshot K2.7 Code als agentischen Arbeitspferd-Stack sieht, nicht lediglich als Chat-Interface-Modell.
Kernspezifikationen (aus dem offiziellen Model Card):
- Gesamtparameter: 1T (1 Billion)
- Aktivierte Parameter pro Token: 32B (rund 3 % spärliche Aktivierung für Effizienz)
- Experten: 384 insgesamt (8 pro Token ausgewählt + 1 Shared Expert)
- Layer: 61 (einschließlich 1 dichten Layer)
- Attention: MLA (Multi-head Latent Attention)
- Feed-Forward-Aktivierung: SwiGLU
- Vokabulargröße: ~160K–166K
- Vision-Encoder: MoonViT (~400 Mio. Parameter) für native Multimodalität (Text + Bild/Video)
- Kontextlänge: 256K Tokens (262,144)
- Quantisierung: Native INT4-Unterstützung für effiziente Bereitstellung
- Training: Muon-Optimizer, trainiert auf massiven gemischten Text-/Visuellen Tokens mit Stabilitätsverbesserungen.
Warum MoE wichtig ist: Nur ~3 % der Parameter werden pro Token aktiviert, wodurch nahezu Frontier-Fähigkeit zu einem Bruchteil der Rechenkosten dichter Modelle ähnlicher Gesamtgröße erreicht wird. Dies ermöglicht erschwingliches Self-Hosting oder API-Nutzung für hochvolumige Coding-Aufgaben.
Das Modell ist groß (~595 GB Gewichte) und zielt auf Inferenz der Serverklasse (vLLM, SGLang, KTransformers). Es nutzt Bereitstellungsmuster aus K2.5/K2.6 wieder.
Performance-Benchmarks: Wie gut ist es?
Moonshot liefert detaillierte First-Party-Benchmarks, die K2.7 Code mit K2.6, GPT-5.5 und Claude Opus 4.8 vergleichen. Während unabhängige Verifizierung läuft (z. B. berichten manche Praktiker über gemischte Ergebnisse auf öffentlichen Kernels), sind die Zugewinne für einen Coding-Spezialisten beeindruckend.
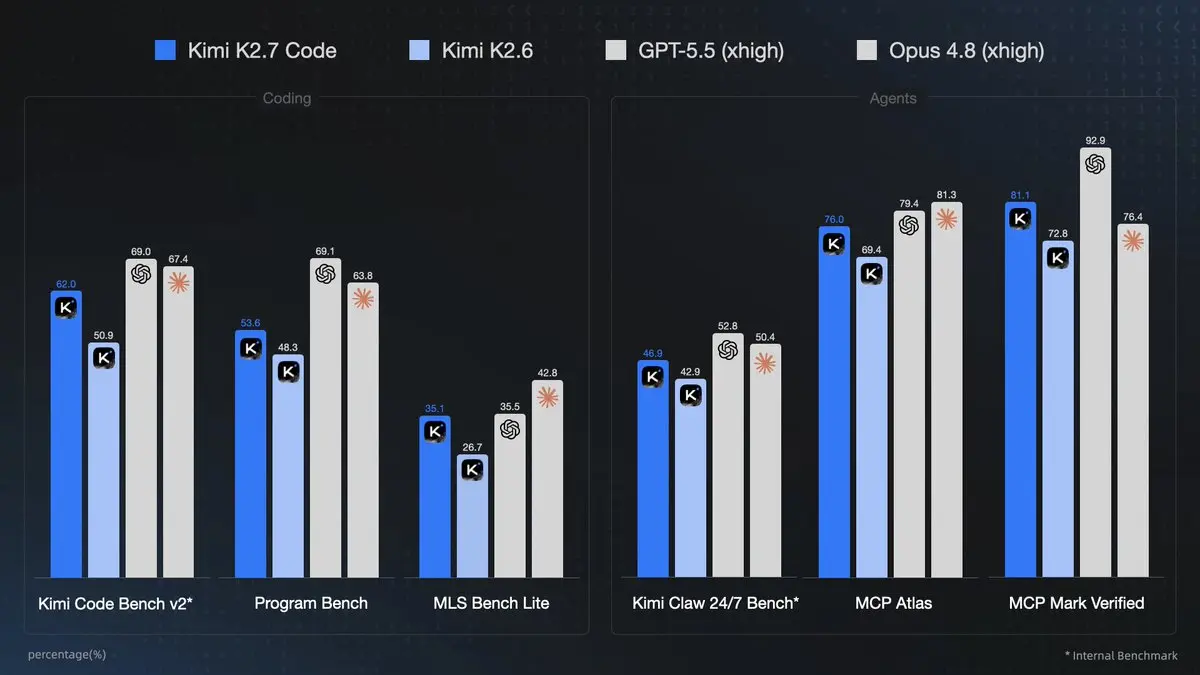
Wichtige Benchmark-Tabelle:
| Benchmark | Kimi K2.6 | Kimi K2.7 Code | GPT-5.5 | Claude Opus 4.8 | Zuwachs (K2.7 vs. K2.6) |
|---|---|---|---|---|---|
| Kimi Code Bench v2 | 50.9 | 62.0 | 69.0 | 67.4 | +21.8% |
| Program Bench | 48.3 | 53.6 | 69.1 | 63.8 | +11.0% |
| MLS Bench Lite | 26.7 | 35.1 | 35.5 | 42.8 | +31.5% |
| Kimi Claw 24/7 Bench | 42.9 | 46.9 | 52.8 | 50.4 | +9.3% |
| MCP Atlas | 69.4 | 76.0 | 79.4 | 81.3 | +9.5% |
| MCP Mark Verified | 72.8 | 81.1 | 92.9 | 76.4 | +11.4% |
Interpretation:
- K2.7 Code verringert die Lücke zu Frontier-Modellen bei Coding-/Agent-Aufgaben und übertrifft Opus 4.8 auf MCP Mark Verified.
- Stark in mehrsprachigem, realweltlichem Software-Engineering und Tool-Use-Szenarien.
- Effizienzvorteil (30 % weniger Tokens) macht es oft vorzuziehen für langlaufende Agenten, auch wenn es nicht immer die höchste Rohgenauigkeit erzielt – weniger Tokens pro Aufgabe bedeuten mehr Iterationen innerhalb von Budget-/Kontextgrenzen.
Einschränkungen: Viele Benchmarks sind in-house oder setupspezifisch. Unabhängige Tests (z. B. KernelBench) zeigen gemischte Ergebnisse bei manchen Low-Level-Aufgaben, aber das Gesamtfeedback aus der Praxis betont die praktische Nützlichkeit in langen Coding-Schleifen.
Effizienzgewinne: Kosten- und Geschwindigkeitsvorteile
Eine 30%ige Reduktion der Reasoning-Tokens klingt abstrakt, bis man sie in Produktionsbegriffe übersetzt. Weniger Reasoning-Tokens bedeuten oft geringere Latenz, niedrigere Kosten und geringere Wahrscheinlichkeit, dass das Modell bei langen Aufgaben unnötige interne Schritte durchläuft. Moonshot sagt, dass K2.7 Code die Effizienz verbessert, während stärkere Aufgabenerfüllung erhalten bleibt, und Cloudflare stellt dies ausdrücklich als Kostenvorteil für reasoning-lastige Workloads dar.
Diese Kombination ist in Coding-Agenten wichtig, weil Software-Engineering-Aufgaben selten „one-and-done“ sind. Sie beinhalten das Lesen einer Codebasis, das Vornehmen einer Änderung, das Verifizieren, den Umgang mit Ausnahmen und das Iterieren. Ein Modell, das token-effizienter ist und besser bei langfristiger Aufgabenerfüllung, kann die Teamproduktivität materiell stärker verbessern als ein Modell, das lediglich bei kurzen Antworten stark ist. Das ist eine Folgerung auf Basis der Benchmark- und Workflow-Aussagen von Moonshot, ergibt sich aber direkt aus der Positionierung des Modells.
Wie viel kostet Kimi K2.7 Code?
Moonshots Kimi-Code-Mitgliedschaft enthält K2.7 Code und beginnt bei $19/Monat, laut offizieller Ressourcenseite. Das ist der Endkundenpfad. Für die API-Nutzung hängt die Preisgestaltung davon ab, wo Sie auf das Modell zugreifen. Im Vergleich zu Claude Opus (~$5–25/M) oder ähnlicher Frontier-Bepreisung bietet K2.7 Code bis zu 5–12x besseren Wert für Coding-Workloads. Self-Hosting senkt die Kosten für Hochvolumen zusätzlich.
Auf CometAPI ist Kimi K2.7 Code mit $0.76 pro Million Eingabe-Token und $3.19998 pro Million Ausgabe-Token gelistet, während der offizielle Preis mit $0.95 pro Million Eingabe-Token und $3.999975 pro Million Ausgabe-Token angegeben ist. CometAPI präsentiert dies als 20% Rabatt gegenüber dem offiziellen Preis.
Das macht CometAPI interessant für Teams, die mit Kimi K2.7 Code experimentieren möchten, ohne separate Anbieterintegrationen zu managen oder den höheren direkten Listenpreis zu zahlen.
Wo ist Kimi K2.7 Code verfügbar?
1) Kimi Code
Moonshot sagt, dass Kimi K2.7 Code nun das Standardmodell in Kimi Code ist, mit standardmäßig aktiviertem Thinking-Modus. Das ist der natívste Weg, das Modell in Moonshots eigener Coding-Umgebung auszuprobieren.
2) Kimi API / Kimi Platform
Moonshots offene Plattform dokumentiert Kimi K2.7 Code als über die Kimi API verfügbar und sagt, dass die Plattform das OpenAI-API-Format verwendet. Das erleichtert die Integration in bestehende Applikationsarchitekturen, die bereits OpenAI-kompatible API-Muster sprechen.
3) Hugging Face
Die offizielle Model Card auf Hugging Face bestätigt die Open-Weight-Veröffentlichung, zeigt die Modellzusammenfassung und Benchmark-Daten und gibt an, dass Code-Repository und Modellgewichte unter einer modifizierten MIT-Lizenz veröffentlicht sind. Das ist der Weg für Entwickler, die die Gewichte inspizieren, selbst deployen oder das Modell in offenen Tooling-Ökosystemen nutzen möchten.
4) CometAPI
CometAPI listet Kimi K2.7 Code jetzt als integriertes Modell und bietet tokenbasierte Preisgestaltung, eine Modellseite und API-Zugriff über sein einheitliches Gateway. Es hebt außerdem hervor, dass die Plattform OpenAI-kompatibel ist und darauf ausgelegt, Anbieterfragmentierung zu reduzieren, indem viele Modelle hinter einem Einstiegspunkt verfügbar sind. Unterstützt werden das 256K-Kontextfenster, Vision-Eingaben, mehrstufige Tool-Aufrufe und ein OpenAI-kompatibler Pfad über /v1/chat/completions. Für die Migration von K2.6 sind keine Parameteränderungen erforderlich.
CometAPI-Empfehlung: Für die meisten Nutzer hier starten. Ein Key, Pay-as-you-go für 500+ Modelle, automatische Fallbacks und niedrigere Effektivraten. Perfekt, um K2.7 Code neben Claude, GPT oder Open-Models zu testen – ohne Vendor Lock-in. Registrieren Sie sich auf Cometapi.com und tauschen Sie die Base-URL/den Modellnamen in Ihrem OpenAI-Client aus.
Self-Hosting-Tipp: Nutzen Sie INT4-Quantisierung und Expert-Parallelisierung für optimale VRAM/Performance auf Enterprise-GPUs.
Kimi K2.7 Code vs. K2.6 vs. andere Modelle
Wenn Ihr aktueller Stack bereits K2.6 verwendet, ist K2.7 Code das naheliegende Upgrade, wenn Coding-Qualität und Reasoning-Effizienz wichtiger sind, als einfach nur die gleiche Basis zu behalten. Moonshot sagt, dass die Architektur der von K2.5/K2.6 entspricht, die Bereitstellung wiederverwendet werden kann und die Benchmark-Leistung materiell verbessert ist. Cloudflare sagt ebenfalls, dass die API-Nutzung identisch ist, was die Migrationshürden senkt.
Im Vergleich zu breiteren Frontier-Modellen wie GPT-5.5 und Claude Opus 4.8 ist K2.7 Code stärker spezialisiert. Die Benchmark-Tabelle zeigt, dass es bei Coding- und Agent-Aufgaben wettbewerbsfähig bleibt, sein echter Differenzierer aber die Kombination aus Open-Source-Zugang, langem Kontext und coding-zentrischem Design ist. Das macht es besonders attraktiv für Teams, die Wert auf Bereitstellungsflexibilität und Kostenkontrolle legen.
Fazit: Warum Kimi K2.7 Code heute über CometAPI integrieren
Kimi K2.7 Code steht für ein reifer werdendes Open-Source-Ökosystem für KI-Coding – leistungsstark, effizient, zugänglich und agentenbereit. Architektur, Benchmark-Gewinne und Token-Effizienz machen es 2026 zu einem Must-try für Entwickler.
CometAPI senkt die Hürden zusätzlich mit nahtloser Integration, wettbewerbsfähigen Preisen und einheitlichem Zugriff. Ob Self-Hosting, offizielle API oder die Plattform von CometAPI – K2.7 Code ermöglicht schnellere, verlässlichere Coding-Workflows.
Bereit, es auszuprobieren? Besuchen Sie CometAPI, holen Sie sich Ihren API-Schlüssel und beginnen Sie noch heute mit Kimi K2.7 Code. Experimentieren Sie, benchmarken Sie gegen Ihre Use Cases und skalieren Sie mit Vertrauen.
FAQs
Ist Kimi K2.7 Code Open Source?
Ja. Moonshot sagt, dass sowohl das Code-Repository als auch die Modellgewichte unter einer modifizierten MIT-Lizenz veröffentlicht sind, und das Modell auf Hugging Face verfügbar ist.
Wie groß ist das Kontextfenster?
Moonshots Docs nennen ein 256K-Kontextfenster, und die Model Card sowie Cloudflare beschreiben es als 262,144 bzw. 262.1K Tokens. Das ist praktisch dieselbe Größenordnung.
Unterstützt Kimi K2.7 Code einen Nicht-Thinking-Modus?
Nein. Moonshot sagt, dass K2.7 Code nur mit aktiviertem Thinking läuft. In Kimi Code führt das Deaktivieren des Thinkings zu einem Fallback auf K2.6.
Was ist die größte Verbesserung gegenüber K2.6?
Die größte gemeldete Verbesserung ist die bessere Leistung bei langfristigen Coding-Aufgaben plus etwa 30 % weniger Thinking-/Reasoning-Tokens. Moonshot meldet außerdem Benchmark-Gewinne von +21.8% auf Kimi Code Bench v2, +11.0% auf Program Bench und +31.5% auf MLS Bench Lite.
Kann ich es über CometAPI nutzen?
Ja. CometAPI listet Kimi K2.7 Code als integriertes Modell und zeigt per-Token-Preise, was es zu einem bequemen Zugangsweg für Entwickler macht, die eine einheitliche API-Schicht wünschen.
Ist es gut für KI-Coding-Agenten?
Ja. Moonshots Dokumentation betont mehrstufige Tool-Aufrufe, verschachteltes Thinking und agentenorientierte Workflows, während Cloudflare Multi-Turn-Tool-Calling und strukturierte Ausgaben hervorhebt.