

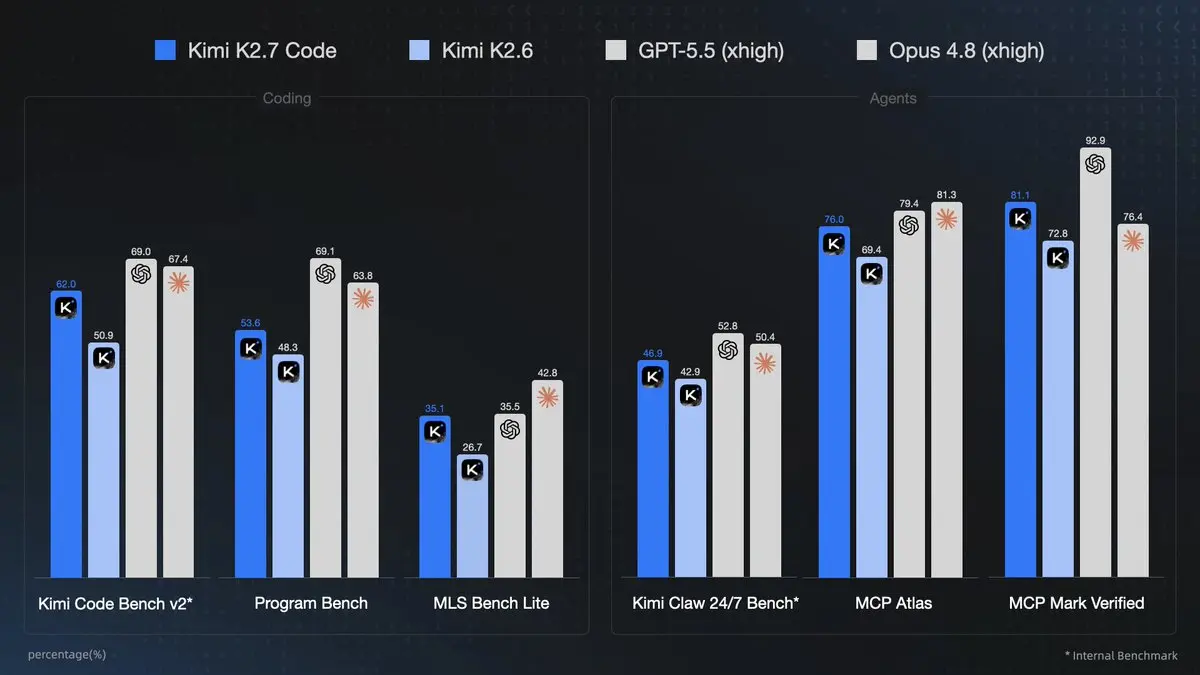
Kimi K2.7 Code, publié par Moonshot AI le 12 juin 2026, est à ce jour le modèle de codage le plus performant de l’entreprise. Ce modèle MoE (Mélange d’experts) à 1T de paramètres active environ 32B de paramètres par token, propose une fenêtre de contexte de 256K–262K tokens, une prise en charge multimodale native (texte + vision), un mode de réflexion forcé, et des capacités agentiques d’appel d’outils renforcées. Il apporte des gains significatifs par rapport à K2.6, dont +21,8 % sur Kimi Code Bench v2, un meilleur suivi des instructions sur de longs contextes, et une réduction d’environ ~30% de l’usage de tokens de raisonnement pour des workflows d’agents plus efficients.
Pour les développeurs et les équipes cherchant un accès performant et économique sans gérer plusieurs clés API, CometAPI offre une intégration sans couture. CometAPI propose des tarifs compétitifs (environ $0.76/1M tokens pour Kimi K2.7 Code) ainsi que 500+ autres modèles, ce qui en fait une solution idéale pour la mise à l’échelle en production, les tests et des workflows unifiés.
Ce qu’est Kimi K2.7 Code
Kimi K2.7 Code est un modèle agentique axé sur le codage, construit sur l’architecture Kimi K2.6. Il s’agit d’un modèle MoE à 1T de paramètres avec 32B de paramètres actifs, une fenêtre de contexte de 256K, et d’excellentes performances en codage long-terme et en agentique. Concrètement, il est conçu pour comprendre une grande base de code, planifier des modifications à travers plusieurs fichiers, appeler des outils, vérifier les sorties et continuer sans perdre le fil.
La distinction produit la plus importante est simple : K2.7 Code n’est pas un modèle « chat-first » auquel on a ajouté du codage. C’est un modèle « code-first » et « réflexion-first » pensé pour des workflows d’ingénierie logicielle où le raisonnement, l’usage d’outils et l’itération font partie du travail. C’est pourquoi il est particulièrement attractif pour les agents de codage, les assistants d’IDE, les relecteurs de dépôts et les pipelines de tests automatisés.
Pourquoi Kimi K2.7 Code se démarque en 2026
- Supériorité en codage : suivi d’instructions en long contexte et taux de réussite de tâches de bout en bout supérieurs. Idéal pour le développement full-stack, le débogage de grandes bases de code et l’affinage itératif.
- Prise en charge multimodale native : texte + images + vidéos pour des tâches vision-to-code (par ex., générer des composants React à partir d’une démo vidéo).
- Puissance agentique : appels d’outils multi-étapes fiables avec raisonnement préservé.
- Efficacité : ~30% de réduction de l’usage de tokens de raisonnement, ce qui se traduit par des gains de coûts et de vitesse.
Comment utiliser l’API Kimi K2.7 Code via CometAPI
CometAPI expose Kimi K2.7 Code via un endpoint compatible OpenAI, ce que la plupart des équipes souhaitent : un seul schéma d’intégration, de nombreuses options de modèles. La page modèle de CometAPI indique Kimi K2.7 Code à $0.76/M pour les jetons d’entrée et $3.19998/M pour les jetons de sortie(use kimi-k2.7-code).
Étape 1 : obtenez votre clé CometAPI
Créez un compte CometAPI et générez une clé API depuis la console CometAPI. Pour les systèmes de production, stockez la clé dans des variables d’environnement ou des gestionnaires de secrets plutôt que de l’intégrer en dur dans votre application. La documentation de CometAPI recommande d’utiliser des SDK compatibles OpenAI pour accélérer l’adoption.
Étape 2 : installez le SDK OpenAI
L’API Kimi est compatible OpenAI, et CometAPI suit le même schéma de base. En Python :
pip install --upgrade openai
Étape 3 : envoyez votre première requête texte
Voici un exemple Python minimaliste pour CometAPI :
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["COMETAPI_KEY"],
base_url="https://api.cometapi.com/v1",
)
response = client.chat.completions.create(
model="kimi-k2.7-code",
messages=[
{"role": "system", "content": "Vous êtes un·e ingénieur·e logiciel senior."},
{"role": "user", "content": "Refactorisez cette fonction Python pour en améliorer la lisibilité et ajoutez des annotations de type."}
],
max_completion_tokens=2048,
stream=False,
)
print(response.choices[0].message.content)
Cette forme de requête fonctionne parce que CometAPI et Kimi suivent tous deux la sémantique de chat completions de style OpenAI, et K2.7 Code prend en charge messages, tools, le streaming et les blocs de contenu multimodal dans la même famille d’endpoints.
Étape 4 : utilisez le streaming pour une meilleure expérience produit
Pour les assistants de codage interactifs, le streaming devrait être votre défaut. CometAPI recommande explicitement le streaming pour l’UX en production, et l’endpoint chat de Kimi prend en charge stream: true. Le streaming est important car les tâches de génération de code sont souvent meilleures lorsque les utilisateurs peuvent voir le modèle réfléchir, esquisser un plan puis produire le code progressivement.
response = client.chat.completions.create(
model="kimi-k2.7-code",
messages=[
{"role": "system", "content": "Vous êtes un assistant de codage."},
{"role": "user", "content": "Écrivez une route API rapide dans FastAPI pour téléverser des fichiers CSV."}
],
stream=True,
max_completion_tokens=2048,
)
for event in response:
delta = event.choices[0].delta
if getattr(delta, "content", None):
print(delta.content, end="")
Capacité d’outillage multimodal : téléversements de fichiers, formats pris en charge, workflow
Kimi K2.7 Code prend en charge les entrées multimodales natives, permettant des workflows vision-to-code comme l’analyse de captures d’écran, de diagrammes, de vidéos ou de documents pour la génération/extraction de code.
Kimi K2.7 Code prend en charge des messages multimodaux avec des blocs text, image_url et video_url. La documentation officielle propose également des endpoints de gestion de fichiers pour l’extraction, la compréhension d’images et l’analyse vidéo. L’API d’upload autorise actuellement jusqu’à 1 000 fichiers par utilisateur, chaque fichier jusqu’à 100 MB, avec un plafond total de 10 GB, et le service d’analyse des fichiers est actuellement gratuit mais peut être limité en cas de pic de trafic.
Quand utiliser le téléversement de fichier plutôt que le base64
Utilisez le téléversement de fichier lorsque la ressource est volumineuse, réutilisée dans plusieurs prompts, ou susceptible d’atteindre les limites du corps de requête. Recommandez le téléversement pour les très grandes vidéos et pour les images ou vidéos référencées plusieurs fois. La taille du corps de requête est une contrainte pratique, et la documentation vision indique que les images fournies sous forme d’URL ne sont pas prises en charge là-bas, avec base64 requis pour le contenu d’image inline.
Restrictions de téléversement de fichiers :
- Des limites de taille de corps de requête s’appliquent (utilisez l’API d’upload pour les grandes vidéos plutôt que base64).
- Pour un usage répété ou des fichiers volumineux : téléversez via l’endpoint
/v1/fileset référencez par ID. - Pas d’images au format URL (base64 uniquement en inline). Quantité d’images flexible mais taille totale ≤~100MB par requête.
Formats pris en charge :
- Images : png, jpeg, webp, gif (≤4K recommandé).
- Vidéos : mp4, mpeg, mov, avi, x-flv, mpg, webm, wmv, 3gpp (≤2K recommandé).
- Documents : pour les téléversements de fichiers, Kimi accepte un large éventail de formats, notamment PDF, DOCX, XLSX, PPTX, Markdown, HTML, JSON, images (avec OCR), de nombreux fichiers de code, et les types d’images courants.
Workflow d’exemple : téléverser un PDF, extraire le contenu, puis l’analyser
import os
from pathlib import Path
from openai import OpenAI
client = OpenAI(
api_key=os.environ["COMETAPI_KEY"],
base_url="https://api.cometapi.com/v1",
)
# 1) Téléverser le fichier pour extraction
file_obj = client.files.create(
file=Path("system-design-spec.pdf"),
purpose="file-extract",
)
# 2) Récupérer le contenu extrait
extracted_text = client.files.content(file_id=file_obj.id).text
# 3) Envoyer le texte extrait à Kimi K2.7 Code
response = client.chat.completions.create(
model="kimi-k2.7-code",
messages=[
{"role": "system", "content": "Vous êtes un·e relecteur·rice technique."},
{
"role": "user",
"content": (
"Passez en revue le document de conception suivant et identifiez les cas limites d’API manquants :\n\n"
f"{extracted_text}"
),
},
],
max_completion_tokens=3000,
)
print(response.choices[0].message.content)
Workflow d’exemple : analyser une image en inline
import base64
from pathlib import Path
from openai import OpenAI
import os
client = OpenAI(
api_key=os.environ["COMETAPI_KEY"],
base_url="https://api.cometapi.com/v1",
)
img_path = Path("ui-mockup.png")
img_b64 = base64.b64encode(img_path.read_bytes()).decode("utf-8")
response = client.chat.completions.create(
model="kimi-k2.7-code",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Examinez cette maquette d’interface utilisateur pour en identifier les problèmes d’accessibilité."},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{img_b64}"}},
],
}
],
max_completion_tokens=1500,
)
print(response.choices[0].message.content)
Workflow d’exemple : analyse vidéo avec une boucle d’outils
Le quickstart officiel présente une boucle d’outils multimodale où le modèle demande d’inspecter un clip vidéo, votre code extrait ce clip, et vous renvoyez le résultat comme sortie d’outil. C’est le bon modèle mental pour K2.7 Code : le modèle planifie, l’outil exécute, et le modèle continue avec les nouvelles preuves.
modèle mental pour K2.7 Code : le modèle planifie, l’outil exécute, et le modèle continue avec les nouvelles preuves.
import base64
from pathlib import Path
from openai import OpenAI
import os
client = OpenAI(
api_key=os.environ["COMETAPI_KEY"],
base_url="https://api.cometapi.com/v1",
)
img_path = Path("ui-mockup.png")
img_b64 = base64.b64encode(img_path.read_bytes()).decode("utf-8")
response = client.chat.completions.create(
model="kimi-k2.7-code",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Examinez cette maquette d’interface utilisateur pour en identifier les problèmes d’accessibilité."},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{img_b64}"}},
],
}
],
max_completion_tokens=1500,
)
print(response.choices[0].message.content)
Différences de paramètres dans le corps de requête vs K2.6
C’est la section que les équipes survolent trop vite, et c’est là que les ennuis commencent. K2.7 Code partage la même structure générale de chat-completions que K2.6, mais plusieurs comportements du corps de requête sont verrouillés. Ainsi, temperature est fixé à 1.0, top_p à 0.95, n à 1, et presence_penalty comme frequency_penalty à 0.0. Plus important encore, le modèle renverra une erreur si vous tentez de désactiver la réflexion.
La version pratique pour les ingénieurs : n’ajustez pas K2.7 Code comme un modèle créatif générique. Conservez les valeurs par défaut, rédigez de bons prompts, et concentrez vos efforts sur la formulation de tâche, la conception d’outils et la vérification. En d’autres termes, le modèle est moins une question de « contrôle de l’aléa » et davantage de « workflow control.
Kimi K2.7 Code vs K2.6 : les différences de corps de requête qui comptent
| Feature | Kimi K2.7 Code | Kimi K2.6 | Why it matters |
|---|---|---|---|
| Thinking mode | Toujours activé ; erreur si "disabled" | Peut être activé ou désactivé | K2.7 est plus simple pour les workflows d’agents car vous ne basculez pas la réflexion par requête. |
| Preserved Thinking | Toujours activé ; thinking.keep est traité comme "all" | Optionnel via thinking.keep | Les sessions de codage multi-tours doivent conserver le reasoning_content intact. |
| Temperature | Fixé à 1.0 | Configurable | Il ne faut pas régler K2.7 avec des valeurs d’échantillonnage arbitraires. |
| Top-p | Fixé à 0.95 | Configurable | Conservez les valeurs par défaut prises en charge par le modèle. |
| n | Fixé à 1 | Configurable | Un seul résultat par requête, ce qui convient bien aux boucles d’agent. |
| Penalties | Fixées à 0.0 | Configurables | Évitez de passer des réglages non pris en charge. |
| Context | 256K | 256K | Les deux gèrent de grands dépôts, mais K2.7 est plus spécialisé pour le codage. |
| Output speed | Variante haute vitesse ~180 tokens/s, jusqu’à 260 en contextes courts | Pas mis en avant de la même façon | Utile lorsque la latence compte plus que le contrôle absolu. |
À retenir : K2.7 Code est volontairement moins configurable que K2.6 en échange d’une expérience de codage plus opinionée. Vous devriez vous appuyer sur les valeurs par défaut plutôt que d’essayer de contourner le comportement fixé du modèle. C’est une fonctionnalité, pas un bug, pour les agents de codage.
Source : documentation officielle Moonshot. K2.7 Code impose le mode réflexion et la conservation du raisonnement pour des étapes de codage multi-tours fiables. Utilisez extra_body pour les paramètres de réflexion si des limitations du SDK surviennent.
Ces contraintes réduisent la variabilité dans les boucles d’agents, améliorant les taux de réussite mais nécessitant des ajustements de workflow par rapport à l’usage général de K2.6.
Compatibilité d’usage d’outils et précautions
Kimi K2.7 Code offre un appel d’outils multi-tours robuste, compatible avec les formats OpenAI/Anthropic. Il prend en charge les outils officiels (recherche web, exécution de code, Excel, mémoire, etc.) et des fonctions personnalisées.
Points de compatibilité :
- Appels de fonctions/outils complets avec prise en charge parallèle et séquentielle.
- Raisonnement intercalé + appels d’outils conservés à travers les tours.
- Fonctionne bien avec des frameworks d’agents comme Kimi Code CLI, Hermes Agent, les extensions VS Code, Cline/RooCode.
Précautions (critiques pour la stabilité) :
- tool_choice : strictement "auto" ou "none". D’autres valeurs provoquent des erreurs.
- Multi-étapes : conservez toujours le message complet de l’assistant (y compris reasoning_content) dans le tableau des messages suivant. Le supprimer déclenche des erreurs.
- Gestion du contexte : avec 256K de contexte, résumez ou émondez avec discernement ; la vision ajoute un surcoût en tokens.
- Limites de taux/budgets : définissez des plafonds de dépenses quotidiens sur vos projets Moonshot/CometAPI. Surveillez les retards d’analyse de fichiers lors des pics.
- Vision + outils : les gros fichiers doivent passer par l’endpoint d’upload ; testez les limites de résolution.
- Gestion des erreurs : implémentez des retries pour les boucles d’appels d’outils ; le modèle peut nécessiter des directives explicites dans le prompt système pour des agents complexes.
Pourquoi CometAPI est une façon intelligente de livrer ce modèle
Le principal avantage de CometAPI n’est pas seulement l’accès ; c’est la réduction des frictions d’intégration. La plateforme présente Kimi K2.7 Code via un unique endpoint compatible OpenAI, ce qui signifie que vous pouvez réutiliser les mêmes SDK, middleware, mécanismes de retry, code de streaming et schémas d’observabilité déjà utilisés avec d’autres fournisseurs. La page modèle de CometAPI positionne aussi le service comme une voie moins coûteuse par rapport au prix officiel, avec un rabais publié de 20 % sur la page tarifaire de K2.7 Code.
Conclusion : commencez à construire avec CometAPI dès aujourd’hui
Si votre produit implique du codage à l’échelle d’un dépôt, du débogage multi-étapes, de l’orchestration d’outils ou de l’analyse multimodale, Kimi K2.7 Code mérite votre attention. Les signaux les plus forts du modèle ne sont pas le vernis de chat générique ; ce sont la fiabilité en long contexte, le raisonnement préservé, un comportement de requête fixe mais prévisible, et de meilleurs résultats de benchmarks de codage rapportés par le fournisseur que K2.6. Ajoutez CometAPI par-dessus, et vous obtenez une voie très pratique vers la production : une intégration compatible OpenAI unique, un simple changement de modèle et une manière plus propre de déployer des agents de codage à l’échelle.
Inscrivez-vous sur CometAPI, récupérez votre clé et testez Kimi K2.7 Code en quelques minutes. Pour des intégrations personnalisées ou un support entreprise, consultez la documentation CometAPI.