

Dans le monde en rapide évolution des assistants de codage IA, la sortie de Kimi K2.7 Code par Moonshot AI le 12 juin 2026 se distingue comme une avancée majeure pour les développeurs, les agents IA et les entreprises en quête de solutions puissantes, économiques et open source.
Ce modèle de codage spécialisé s’appuie sur la famille K2 et met l’accent sur les tâches d’ingénierie logicielle à long horizon, le suivi d’instructions fiable dans des contextes massifs, l’appel d’outils multi-tours, les entrées visuelles et des sorties structurées pour des flux de travail orientés agent. Avec 1 trillion de paramètres au total mais seulement 32 milliards activés par jeton grâce à une conception Mixture-of-Experts (MoE), il offre des capacités de niveau frontière à une fraction du coût des modèles fermés comme Claude Opus 4.8 ou GPT-5.5.
CometAPI a désormais intégré Kimi K2.7 Code, le rendant accessible de façon transparente via un point de terminaison compatible OpenAI unique à un prix inférieur au prix officiel. Cette intégration permet aux développeurs de changer de modèle sans effort, d’optimiser les coûts et de créer des applications IA robustes sans gérer plusieurs fournisseurs.
Qu’est-ce que Kimi K2.7 Code ?
Kimi K2.7 Code (également appelé Kimi-K2.7-Code ou kimi-k2.7-code) est un modèle MoE orienté codage et agent développé par Moonshot AI. Il est explicitement conçu pour les tâches d’ingénierie logicielle à long horizon — des scénarios où une IA doit maintenir le contexte sur des milliers d’étapes, naviguer dans des dépôts, invoquer des outils, modifier du code à travers des modules, exécuter des tests, déboguer et itérer jusqu’à la complétion.
Caractéristiques clés :
- Poids ouverts sur Hugging Face (
moonshotai/Kimi-K2.7-Code). - Licence MIT modifiée — permissive pour un usage commercial avec exigences d’attribution pour les déploiements à grand volume.
- Prise en charge multimodale native — texte + image + vidéo via l’encodeur MoonViT (~400M paramètres).
- Mode de réflexion toujours actif — obligatoire pour des performances agentiques fiables ; ne peut pas être désactivé.
Contrairement aux modèles de chat généraux, K2.7 Code est ajusté pour la fiabilité sur des sessions étendues. Il réduit la « sur-réflexion » (jetons de raisonnement internes excessifs) d’environ 30 % par rapport à K2.6, ce qui se traduit par des coûts moindres, des itérations plus rapides et de meilleurs taux de réussite de bout en bout dans des flux de travail complexes.
Cela en fait un choix idéal pour :
- Des refactorisations à l’échelle d’un dépôt.
- La génération de code multilingue (Python, Rust, Go, etc.).
- L’usage d’outils orienté agent (MCP, CI/CD, opérations système de fichiers).
- Des tâches frontend, DevOps, d’optimisation des performances et d’ingénierie ML.
Quoi de neuf dans Kimi K2.7 Code ?
1) Programmation à long horizon plus robuste
La plus grande amélioration concerne les performances sur les tâches de programmation à long horizon. Moonshot indique que K2.7 Code améliore la réussite de bout en bout sur des flux d’ingénierie logicielle complexes, pas seulement la complétion de code en un coup. C’est le type d’amélioration que les développeurs remarquent lorsqu’un modèle est capable de garder le fil d’un projet sur de nombreux tours au lieu de dériver après les premières étapes.
Gains substantiels sur K2.6 :
- +21.8% sur Kimi Code Bench v2 (62.0% vs. 50.9%)
- +11.0% sur Program Bench (53.6% vs. 48.3%)
- +31.5% sur MLS Bench Lite (35.1% vs. 26.7%)
- +9.3% sur Kimi Claw 24/7 Bench
- +9.5% sur MCP Atlas
- +11.4% sur MCP Mark Verified (81.1% vs. 72.8%)
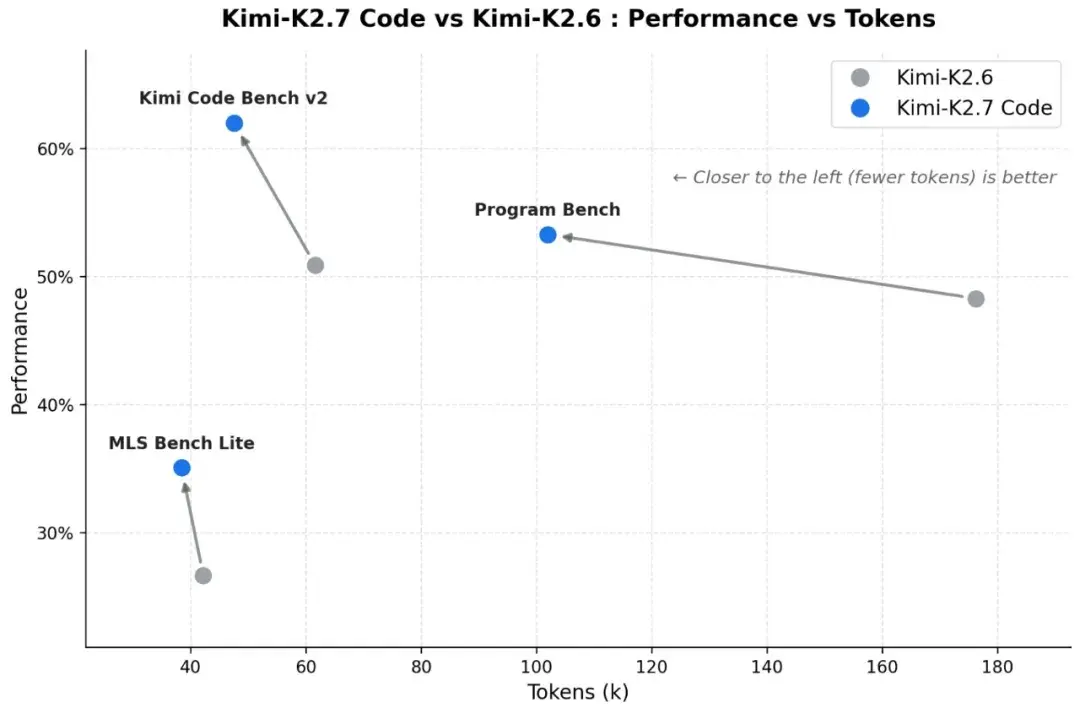
2) Meilleure efficacité de raisonnement
Moonshot rapporte que K2.7 Code utilise environ 30 % de jetons de raisonnement en moins que K2.6. Le changelog de Workers AI de Cloudflare reprend cette affirmation d’efficacité et ajoute qu’une utilisation moindre de jetons de raisonnement peut réduire le coût d’inférence sur les charges de travail lourdes en raisonnement. En clair : le modèle n’est pas seulement plus performant sur les tâches de codage, il est aussi plus économe lorsqu’il réfléchit.
3) Comportement de réflexion par défaut
Kimi K2.7 Code est un modèle « pensant » uniquement. Moonshot indique qu’il ne prend pas en charge le mode non-réfléchissant, et que dans Kimi Code, si la réflexion est désactivée, le système revient automatiquement à K2.6. C’est un détail utile pour les équipes construisant des outils de codage orientés agent, car cela signifie qu’il faut concevoir en partant du principe que le raisonnement est activé par défaut.
4) Capacités à long horizon renforcées :
Meilleure généralisation à travers les langages (Python, Rust, Go, etc.) et les scénarios (frontend, DevOps, sécurité, ML). Taux de réussite de tâches de bout en bout plus élevés.
5) Multimodal et utilisation d’outils améliorés
Encodeur de vision (400M de paramètres) pour les images/vidéos ; intégration fluide MCP/outils pour des environnements réels (GitHub, Postgres, navigateurs, etc.).
Architecture et paramètres de Kimi K2.7 Code
Kimi K2.7 Code utilise une architecture Mixture-of-Experts. Selon la fiche du modèle officielle sur Hugging Face, il comporte 1T de paramètres au total et 32B de paramètres activés. Il inclut 61 couches, 384 experts, 8 experts sélectionnés par jeton, 1 expert partagé, de l’attention MLA, une activation SwiGLU, un vocabulaire de 160K, et une longueur de contexte de 256K. L’encodeur de vision est MoonViT avec 400M de paramètres.
Cette architecture explique l’attrait du modèle. Un modèle MoE à un trillion de paramètres peut préserver un plafond de capacité très élevé tout en n’activant qu’un sous-ensemble de paramètres par jeton, ce qui est l’une des raisons pour lesquelles les systèmes MoE sont attrayants pour une inférence haute capacité. K2.7 Code adopte la même approche de quantification native INT4 que K2 Thinking, ce qui aide à l’efficacité du déploiement.
La fenêtre de contexte est un autre argument de vente majeur. La documentation officielle décrit une fenêtre de 256K, suffisamment grande pour des bases de code longues, de longues conversations, et des sessions d’agents multi-étapes où la rétention de contexte est cruciale.
K2.7 Code partage le même schéma de réflexion intercalée et d’appels d’outils multi-étapes que K2 Thinking, et recommande Kimi Code CLI comme cadre d’agent le plus adapté au modèle. C’est un signal fort que Moonshot voit K2.7 Code comme un cheval de bataille agentique, et pas simplement un modèle d’interface de chat.
Caractéristiques principales (d’après la fiche du modèle officielle) :
- Paramètres totaux : 1T (1 trillion)
- Paramètres activés par jeton : 32B (environ 3 % d’activation clairsemée pour l’efficacité)
- Experts : 384 au total (8 sélectionnés par jeton + 1 expert partagé)
- Couches : 61 (dont 1 couche dense)
- Attention : MLA (Multi-head Latent Attention)
- Activation feed-forward : SwiGLU
- Taille du vocabulaire : ~160K–166K
- Encodeur de vision : MoonViT (~400M paramètres) pour le multimodal natif (texte + image/vidéo)
- Longueur de contexte : 256K jetons (262,144)
- Quantification : Prise en charge native INT4 pour un déploiement efficace
- Entraînement : Optimiseur Muon, entraîné sur un mélange massif de jetons texte/visuels avec des améliorations de stabilité.
Pourquoi le MoE est important : Seuls ~3 % des paramètres s’activent par jeton, offrant des capacités proches de l’état de l’art à une fraction du coût de calcul des modèles denses de taille totale similaire. Cela permet un auto-hébergement ou un usage API abordable pour des tâches de codage à grand volume.
Le modèle est volumineux (~595 GB de poids), visant une inférence de classe serveur (vLLM, SGLang, KTransformers). Il réutilise les schémas de déploiement de K2.5/K2.6.
Référentiels de performance : quel est son niveau ?
Moonshot fournit des benchmarks détaillés de première main comparant K2.7 Code à K2.6, GPT-5.5 et Claude Opus 4.8. Tandis que la vérification indépendante est en cours (par ex., certains praticiens notent des résultats mitigés sur des kernels publics), les gains sont impressionnants pour un spécialiste du codage.
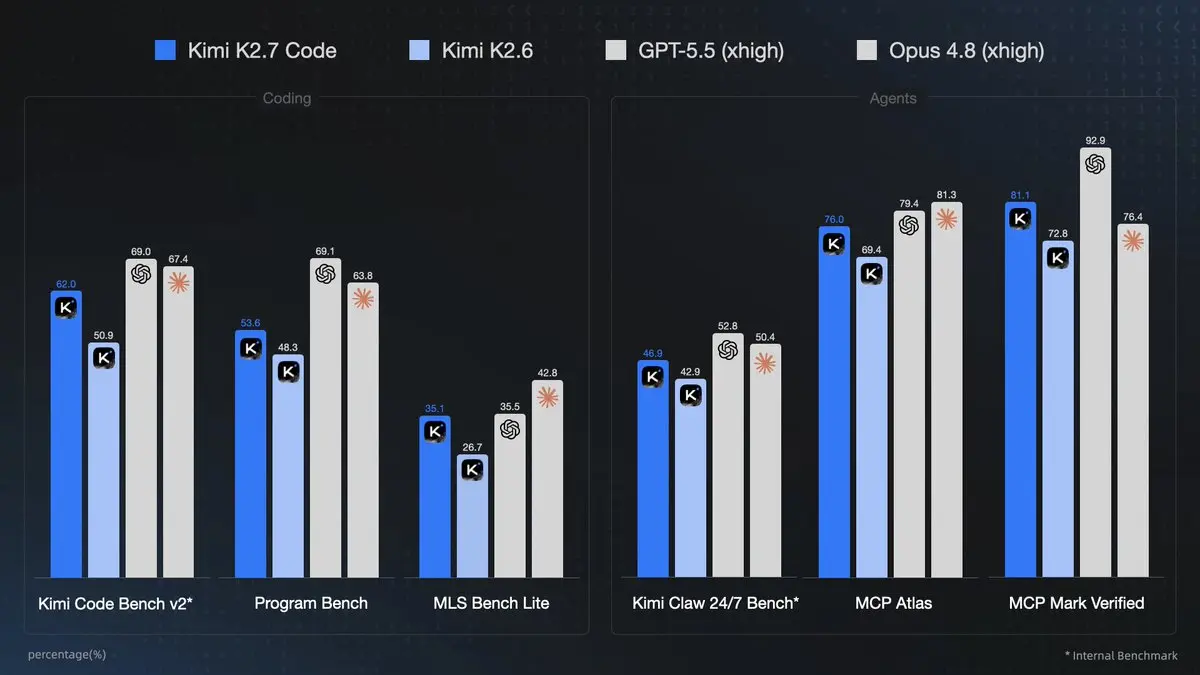
Tableau de benchmark clé :
| Benchmark | Kimi K2.6 | Kimi K2.7 Code | GPT-5.5 | Claude Opus 4.8 | Gain (K2.7 vs K2.6) |
|---|---|---|---|---|---|
| Kimi Code Bench v2 | 50.9 | 62.0 | 69.0 | 67.4 | +21.8% |
| Program Bench | 48.3 | 53.6 | 69.1 | 63.8 | +11.0% |
| MLS Bench Lite | 26.7 | 35.1 | 35.5 | 42.8 | +31.5% |
| Kimi Claw 24/7 Bench | 42.9 | 46.9 | 52.8 | 50.4 | +9.3% |
| MCP Atlas | 69.4 | 76.0 | 79.4 | 81.3 | +9.5% |
| MCP Mark Verified | 72.8 | 81.1 | 92.9 | 76.4 | +11.4% |
Interprétation :
- K2.7 Code réduit l’écart avec les modèles de pointe sur les tâches de codage/agent et dépasse Opus 4.8 sur MCP Mark Verified.
- Solide en multilingue, en ingénierie logicielle réelle et en scénarios d’usage d’outils.
- L’avantage d’efficacité (30 % de jetons en moins) le rend souvent préférable pour des agents longue durée, même s’il ne domine pas toujours en précision brute : moins de jetons par tâche signifie davantage d’itérations dans les limites de budget/contexte.
Mises en garde : Beaucoup proviennent d’environnements internes ou de configurations spécifiques. Des tests indépendants (par ex., KernelBench) montrent des résultats mitigés sur certaines tâches de bas niveau, mais les retours des praticiens soulignent une utilité pratique dans les boucles de codage longues.
Gains d’efficacité : avantages en coût et en vitesse
Une réduction de 30 % des jetons de raisonnement peut paraître abstraite jusqu’à sa mise en production. Moins de jetons de raisonnement signifie souvent une latence plus faible, un coût inférieur et moins de risques que le modèle s’égare dans des étapes internes inutiles sur de longues tâches. Moonshot indique que K2.7 Code améliore l’efficacité tout en préservant une meilleure complétion de tâches, et Cloudflare présente explicitement cela comme un avantage de coût pour les charges lourdes en raisonnement.
Cette combinaison compte pour les agents de codage car les tâches d’ingénierie logicielle sont rarement « one-shot ». Elles impliquent de lire une base de code, d’apporter un changement, de vérifier, de gérer les exceptions et d’itérer. Un modèle plus efficient en jetons et meilleur en accomplissement de tâches à long horizon peut réellement améliorer la productivité d’équipe par rapport à un modèle simplement fort sur des réponses courtes. C’est une inférence basée sur les benchmarks et revendications de flux de travail de Moonshot, mais elle découle directement du positionnement du modèle.
Combien coûte Kimi K2.7 Code ?
L’abonnement Kimi Code de Moonshot inclut K2.7 Code et commence à $19/mois, selon la page officielle. C’est la voie produit grand public. Pour l’usage API, le prix dépend de l’endroit où vous accédez au modèle. Comparé à Claude Opus (~$5–25 / M) ou à des tarifs de modèles de pointe similaires, K2.7 Code offre jusqu’à 5–12x de meilleure valeur pour les charges de codage. L’auto-hébergement réduit davantage les coûts pour un usage à grand volume.
Sur CometAPI, Kimi K2.7 Code est affiché à $0.76 par million de jetons d’entrée et $3.19998 par million de jetons de sortie, tandis que le prix officiel est $0.95 par million de jetons d’entrée et $3.999975 par million de jetons de sortie, ce que CometAPI présente comme une remise de 20 % par rapport au prix officiel.
Cela rend CometAPI intéressant pour les équipes qui veulent expérimenter Kimi K2.7 Code sans gérer des intégrations fournisseurs séparées ni payer le prix catalogue direct plus élevé.
Où accéder à Kimi K2.7 Code
1) Kimi Code
Moonshot indique que Kimi K2.7 Code est désormais le modèle par défaut dans Kimi Code, avec le mode de réflexion activé par défaut. C’est la manière la plus native d’essayer le modèle si vous voulez l’environnement de codage de Moonshot.
2) Kimi API / Kimi Platform
La plateforme ouverte de Moonshot documente Kimi K2.7 Code comme disponible via l’API Kimi, et indique que la plateforme utilise le format d’API OpenAI. Cela facilite l’intégration dans des architectures d’applications existantes qui parlent déjà les schémas d’API compatibles OpenAI.
3) Hugging Face
La fiche du modèle officielle sur Hugging Face confirme la publication à poids ouverts, montre le résumé du modèle et les données de benchmark, et précise que le dépôt de code et les poids du modèle sont publiés sous une licence MIT modifiée. C’est la voie pour les développeurs qui veulent inspecter les poids, déployer eux-mêmes ou utiliser le modèle dans des écosystèmes d’outils ouverts.
4) CometAPI
CometAPI répertorie désormais Kimi K2.7 Code comme modèle intégré et propose une tarification basée sur les jetons, une page modèle et un accès API via sa passerelle unifiée. La plateforme met également en avant sa compatibilité OpenAI et sa conception visant à réduire la fragmentation fournisseur en plaçant de nombreux modèles derrière un seul point d’entrée. Elle prend en charge la fenêtre de contexte 256K, les entrées vision, l’appel d’outils multi-tours, et un chemin compatible OpenAI via /v1/chat/completions. Aucun changement de paramètre n’est requis si vous migrez depuis K2.6.
Recommandation CometAPI : Pour la plupart des utilisateurs, commencez ici. Une seule clé, paiement à l’usage sur plus de 500 modèles, basculements automatiques et tarifs effectifs plus bas. Parfait pour tester K2.7 Code aux côtés de Claude, GPT ou de modèles ouverts sans verrou fournisseur. Inscrivez-vous sur Cometapi.com et remplacez l’URL de base/nom du modèle dans votre client OpenAI.
Conseil pour l’auto-hébergement : Utilisez la quantification INT4 et le parallélisme d’experts pour une VRAM/des performances optimales sur des GPU d’entreprise.
Kimi K2.7 Code vs K2.6 vs autres modèles
Si votre pile actuelle utilise déjà K2.6, K2.7 Code est la mise à niveau évidente lorsque la qualité de codage et l’efficacité de raisonnement comptent davantage que le maintien du même socle. Moonshot indique que l’architecture est la même que K2.5/K2.6, que le déploiement peut être réutilisé, et que les performances de benchmark s’améliorent sensiblement. Cloudflare précise également que l’usage API est identique, ce qui réduit les frictions de migration.
Comparé à des modèles de pointe plus généraux comme GPT-5.5 et Claude Opus 4.8, K2.7 Code est plus spécialisé. Le tableau de benchmark montre qu’il reste compétitif en codage et en tâches d’agent, mais son véritable différenciateur est la combinaison d’un accès open source, d’un long contexte et d’une conception centrée sur le codage. Cela le rend particulièrement attractif pour les équipes qui valorisent la flexibilité de déploiement et la maîtrise des coûts.
Conclusion : pourquoi intégrer Kimi K2.7 Code via CometAPI dès aujourd’hui
Kimi K2.7 Code incarne la maturité d’un écosystème open source d’assistants de codage IA — puissant, efficace, accessible et prêt pour les agents. Son architecture, ses gains de benchmark et son efficacité en jetons en font un incontournable pour les développeurs en 2026.
CometAPI abaisse encore la barrière avec une intégration fluide, des prix compétitifs et un accès unifié. Que ce soit en auto-hébergement, via l’API officielle, ou en tirant parti de la plateforme CometAPI, K2.7 Code permet des flux de travail de codage plus rapides et plus fiables.
Prêt à essayer ? Visitez CometAPI, récupérez votre clé API et commencez à construire avec Kimi K2.7 Code dès aujourd’hui. Expérimentez, comparez à vos cas d’usage et montez en charge en toute confiance.
FAQ
Kimi K2.7 Code est-il open source ?
Oui. Moonshot indique que le dépôt de code et les poids du modèle sont publiés sous une licence MIT modifiée, et que le modèle est disponible sur Hugging Face.
Quelle est la fenêtre de contexte ?
La documentation de Moonshot mentionne une fenêtre de contexte de 256K, et la fiche du modèle ainsi que Cloudflare la décrivent comme 262,144 ou 262.1K jetons. C’est effectivement la même échelle.
Kimi K2.7 Code prend-il en charge le mode non-réfléchissant ?
Non. Moonshot indique que K2.7 Code ne fonctionne qu’avec la réflexion activée. Dans Kimi Code, désactiver la réflexion fait revenir à K2.6.
Quelle est la plus grande amélioration par rapport à K2.6 ?
La plus grande amélioration rapportée est une meilleure performance en programmation à long horizon, plus environ 30 % de jetons de raisonnement en moins. Moonshot rapporte également des gains de +21.8% sur Kimi Code Bench v2, +11.0% sur Program Bench, et +31.5% sur MLS Bench Lite.
Puis-je l’utiliser via CometAPI ?
Oui. CometAPI répertorie désormais Kimi K2.7 Code comme modèle intégré et affiche une tarification par jeton, ce qui en fait une voie d’accès pratique pour les développeurs souhaitant une couche API unifiée.
Est-il adapté aux agents de codage IA ?
Oui. La documentation de Moonshot met l’accent sur les appels d’outils multi-étapes, la réflexion intercalée et les flux de travail orientés agent, tandis que Cloudflare souligne l’appel d’outils multi-tours et les sorties structurées.