

In the rapidly evolving AI landscape, GLM-5.2 from Z.ai (Zhipu AI) stands out as a formidable open-weights model optimized for agentic coding, long-horizon tasks, and production reliability. With a usable 1M-token context window, dual reasoning modes (High and Max), and strong performance at a fraction of the cost of closed frontier models, it's quickly becoming a go-to for developers building autonomous agents, IDE integrations, and complex software engineering workflows.
Whether you're a solo developer prototyping agents, a CTO evaluating cost-effective scaling, or an AI product manager integrating multimodal-capable reasoning into SaaS, mastering the GLM-5.2 API unlocks significant advantages.
What is GLM-5.2?
GLM-5.2 is Z.ai’s (Zhipu AI) latest flagship open-weights Mixture-of-Experts (MoE) model, released in mid-June 2026. With approximately 753 billion total parameters (around 40B active per token), a stable 1 million-token context window, MIT licensing, and strong performance on long-horizon coding and agentic tasks, it positions itself as a competitive alternative to closed frontier models like GPT-5.5, Claude Opus 4.8, and Gemini variants—at a fraction of the cost for many workloads.
GLM-5.2 Architecture and Technical Specifications
GLM-5.2 builds on the GLM family with key upgrades for long-horizon work.
- Parameters: ~753B total in MoE design (active parameters ~40B per token). This delivers massive capacity with efficient inference.
- Context Window: 1,048,576 tokens (1M). Max output typically up to 128K–131K tokens.
- Precision: BF16 (with FP8 variants for lighter deployment).
- Key Innovation – IndexShare: Reuses a single indexer across groups of sparse attention layers, slashing per-token FLOPs by up to 2.9x at 1M context. This makes long-context inference viable without exploding costs or latency.
- Reasoning Modes: "High" (balanced) and "Max" (deepest, recommended for coding). Thinking can be disabled for simple tasks.
- Modalities: Primarily text/code (no native vision confirmed in base release).
- License: MIT – fully open for download, modification, and commercial use.
This openness and efficiency make GLM-5.2 ideal for teams prioritizing data privacy, customization, or cost control.
GLM-5.2 vs GLM-5.1
| Area | GLM-5.1 | GLM-5.2 | Practical difference |
|---|---|---|---|
| Context window | Around 200K on common hosted routes | 1M | GLM-5.2 is much better suited for whole-project context |
| Reasoning effort | Less flexible | High and Max | Better control over cost, latency and quality |
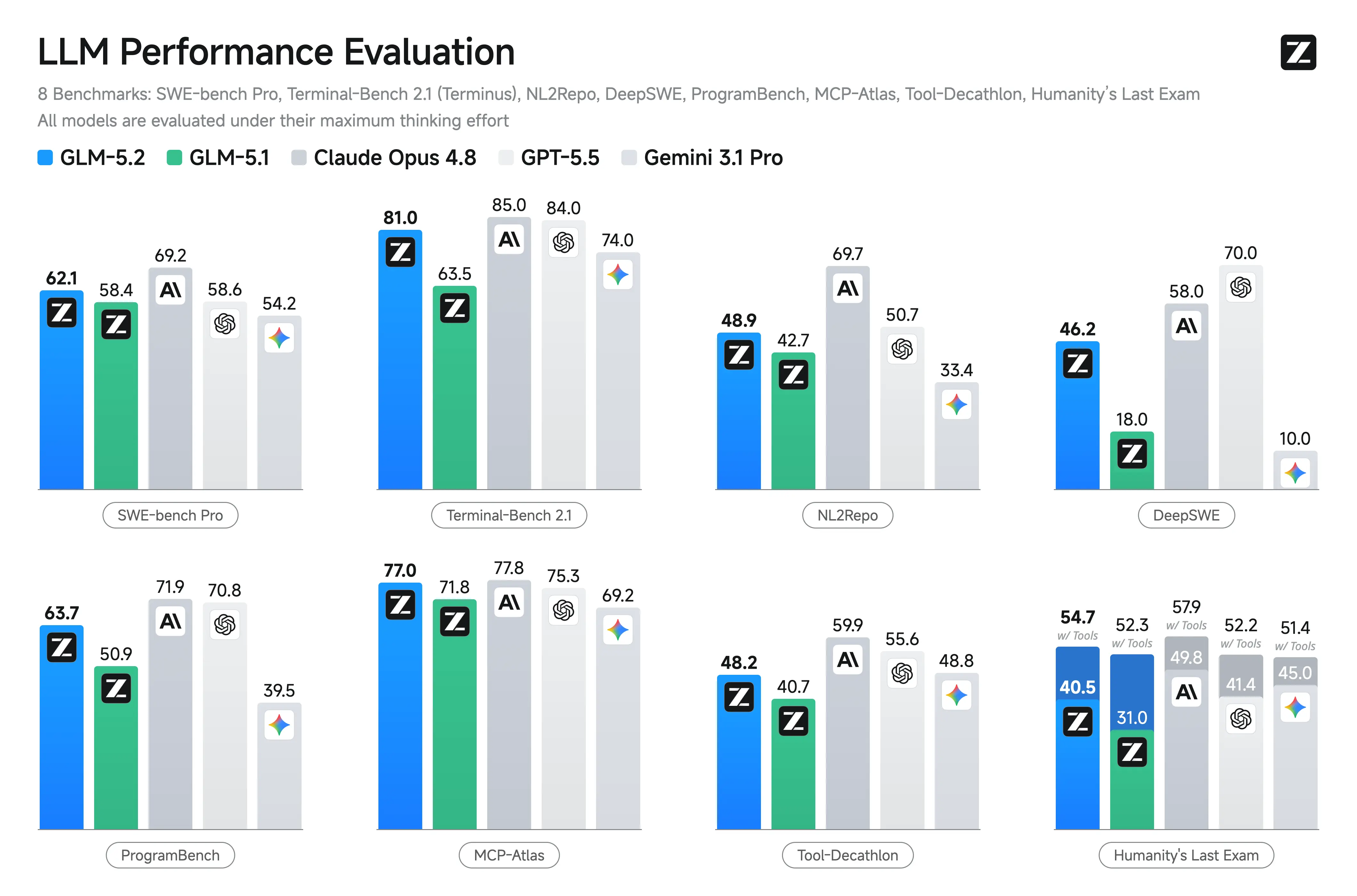
| Terminal Bench 2.1 | 63.5 in the published table | 81.0 | Major improvement in terminal-based agent tasks |
| SWE-bench Pro | 58.4 | 62.1 | Moderate but meaningful repo-level coding gain |
| FrontierSWE | 30.5 | 74.4 | Very large long-horizon engineering improvement |
| Open-weight posture | Open-weight GLM family | Open-weight MIT release | Similar openness, stronger long-context positioning |
If your current GLM-5.1 workflow is mostly short chat or basic code generation, the upgrade may not change everything. If your workflow involves large repositories, multi-step coding agents or long task execution, GLM-5.2 is a much more relevant model.
GLM-5.2 vs Claude Opus, GPT-5.5, Gemini and DeepSeek
The cleanest way to compare GLM-5.2 is by task type:
| Task type | GLM-5.2 position |
|---|---|
| Long-horizon coding | One of the strongest open-weight options; near frontier closed models on selected benchmarks |
| General reasoning | Strong, but not always ahead of top closed models |
| Tool use | Strong MCP-Atlas and HLE-with-tools performance |
| Math competitions | Very strong AIME 2026 score in published results |
| Vision | Not the right model; use a vision model |
| Low-cost high-volume classification | Usually overpowered; use a smaller model |
| Self-hosting and customization | Stronger option than closed API-only models |
For teams, the best answer is usually not "replace every model with GLM-5.2." The better answer is "route GLM-5.2 to the tasks where it has an advantage." That is one reason a unified API provider such as CometAPI can be practical. It lets you compare and route models by workload without rebuilding every integration.
Pricing: Affordable Power for Scale
GLM-5.2 offers compelling economics, especially for token-heavy long-context work.
- API Pricing (via Z.ai/OpenRouter/etc.): $1.40 / 1M input tokens, $4.40 / 1M output tokens. Cache read as low as $0.26/1M in some routes.
- GLM Coding Plan Subscriptions (includes full access, no extra for 5.2):
- Lite: ~$10-12.60/month (light iteration).
- Pro: ~$30/month.
- Max/Team: Higher quotas for heavy use.
Cost Savings Example: For a long agentic session with 500K context + outputs, GLM-5.2 can be 4-5x cheaper than Claude equivalents while handling larger contexts natively.
CometAPI Recommendation: Access GLM-5.2 (and 500+ other models) through CometAPI’s unified OpenAI-compatible endpoint at competitive rates. One key, no vendor lock-in, test credits on signup. Ideal for comparing GLM-5.2 side-by-side with Claude/GPT in production. Visit cometapi for seamless integration.
1M Context Window: The Standout Feature
The 1M context is "solid" and lossless in practice for project-scale work—far beyond marketing hype. It enables keeping entire mid-to-large repositories in-context, reducing summarization overhead and error accumulation in agents.
Tips for Effective Use:
- Use glm-5.2[1m] identifier.
- Set max tokens appropriately; monitor for production.
- Combine with tools/MCP for dynamic data fetching.
Early tests confirm stability past 200K, a common failure point for other "long-context" models.
Baseline Performance and Benchmarks
Z.ai and independent reports highlight GLM-5.2's strengths in coding and agentic scenarios. It shows substantial gains over GLM-5.1 and competitive results against closed models on long-horizon tasks.
Key reported benchmarks (Z.ai and third-party aggregates):
- Terminal-Bench 2.1: 81.0 (up from GLM-5.1's 62.0) – Excellent for terminal/agent operations.
- SWE-bench Pro: 62.1 (edges GPT-5.5 at 58.6).
- MCP-Atlas: 77.0 (near Claude Opus 4.8).
- Humanity’s Last Exam (with tools): 54.7.
Other Leads: Tops or near-top among open models on FrontierSWE, PostTrainBench, SWE-Marathon. Strong on AIME 2026 (~99.2) and GPQA-Diamond (91.2).
GLM-5.2 API Access Options
There are two common ways to access GLM-5.2 from an application.
Option 1: Use Z.ai Directly
The direct route is to use the official Z.ai API. This can be the right choice when your team wants a direct relationship with the model provider, uses only Z.ai models, or needs provider-specific controls as soon as they are released.
The tradeoff is operational. If your product uses multiple model families, you may need to maintain separate SDK configurations, billing flows, failover logic, pricing normalization, and observability conventions. For a research project, that may be acceptable. For a production SaaS platform, the integration surface can grow quickly.
Option 2: Use GLM-5.2 Through CometAPI
CometAPI provides access to GLM-5.2 through a unified API gateway. The practical benefit is that developers can call different AI models through one OpenAI-compatible interface instead of building one integration per provider. You keep your code closer to the OpenAI SDK pattern, set the model name to glm-5.2, and route requests through CometAPI.
This is useful for startups and product teams that want to:
- Test GLM-5.2 against other models without rebuilding their backend
- Keep one API key and one billing layer for multiple models
- Move faster from benchmark to prototype to production
- Implement model fallback or routing strategies
- Compare cost and quality across providers
- Use familiar OpenAI-style request patterns
Sign up at CometAPI.com for instant test credits and OpenAI-compatible endpoints that abstract away provider quirks.
- Obtain your API key.
- Set environment variables (security best practice):
export GLM_API_KEY="your_key_here"
export BASE_URL="https://api.cometapi.com/v1" # or direct Z.ai endpoint
Making Your First GLM-5.2 API Call
cURL Example (quick test):
bash
curl https://api.z.ai/api/paas/v4/chat/completions \
-H "Authorization: Bearer $GLM_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5.2",
"messages": [
{"role": "system", "content": "You are an expert full-stack engineer."},
{"role": "user", "content": "Write a FastAPI endpoint for user authentication with JWT."}
],
"temperature": 0.7,
"max_tokens": 2048
}'
Common GLM-5.2 Use Cases
GLM-5.2 is a strong candidate for workflows where long context, reasoning, and tool use combine.
| Use case | Example implementation | Why GLM-5.2 may fit |
|---|---|---|
| Developer assistant | Analyze bug reports, code snippets, logs, and tests | Requires reasoning across technical context |
| Document intelligence | Review contracts, policies, claims, or reports | Long inputs and structured extraction |
| Research agent | Read sources, compare claims, produce summaries | Benefits from long context and citation discipline |
| Customer support copilot | Combine ticket history, docs, account data, and policy | Needs retrieval plus tool calling |
| AI product manager assistant | Synthesize feedback, specs, usage data, and roadmap notes | Long context and business reasoning |
| Security analysis | Review incident reports, alerts, and remediation plans | Needs careful multi-step reasoning |
| Sales engineering | Generate technical answers from docs and customer requirements | Useful for complex B2B sales cycles |
The common pattern is not "chatbot." The common pattern is workflow compression. GLM-5.2 can reduce the time between raw information and a useful decision.
Who Should Use GLM-5.2?
GLM-5.2 is a strong fit for:
- Developers building AI coding tools.
- SaaS companies adding repository-aware assistants.
- CTOs evaluating open-weight alternatives to closed coding models.
- AI product managers testing long-context workflows.
- Enterprises with future self-hosting or data-control needs.
- Developer platforms that need model optionality.
- Teams working with large technical documents, SDKs or codebases.
It is especially attractive when the task is expensive to fail. If a model's mistake causes broken builds, bad migrations or wasted engineering time, the cost of using a stronger model can be justified quickly.
When Not to Use GLM-5.2
Do not default to GLM-5.2 for:
- Short and repetitive classification tasks.
- Simple text rewriting.
- Image or screenshot understanding.
- Low-latency autocomplete where milliseconds matter.
- Workflows where a smaller model already performs well.
- Products that cannot tolerate long-running generation.
The goal is not to worship the largest context window. The goal is to solve the task with the right quality, cost and latency profile.
Final Verdict
GLM-5.2 is one of the most important open-weight AI model releases for software engineering teams in 2026. The combination of 1M context, strong coding benchmarks, High and Max reasoning modes, function-calling support and MIT licensing makes it a serious option for coding agents and long-horizon AI workflows.
For teams that want to try it quickly, CometAPI is a pragmatic access layer. You can call GLM-5.2 through an OpenAI-compatible endpoint, compare it with other leading models, monitor usage and build a routing strategy without rebuilding your stack around one provider. Start with a small private evaluation, measure cost per solved task and move GLM-5.2 into production only where its long-context strengths clearly pay for themselves.
Ready to test GLM-5.2 in your own app? Explore GLM-5.2 on CometAPI, create an API key and run your first OpenAI-compatible request in minutes. Use it for a real repository task, not a toy prompt, and compare the result against your current model stack.