

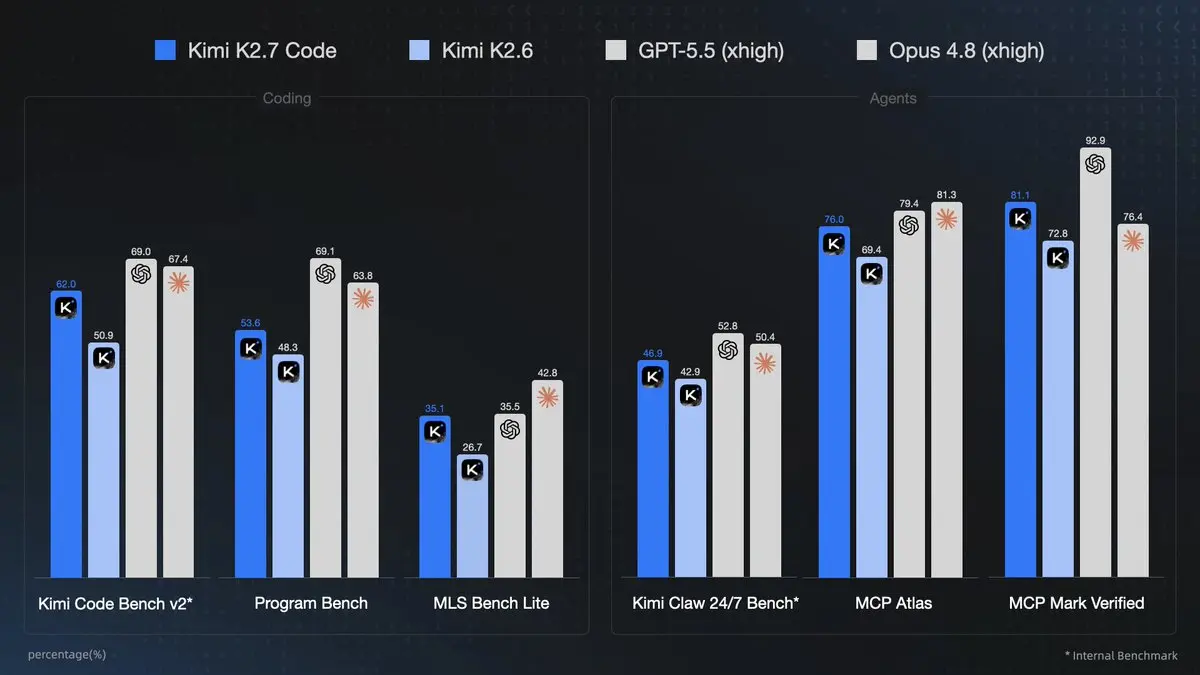
Kimi K2.7 Code, lançado pela Moonshot AI em 12 de junho de 2026, é o modelo com maior foco em programação da empresa até o momento. Este modelo MoE (Mistura de Especialistas) com 1T de parâmetros ativa aproximadamente 32B de parâmetros por token, oferece uma janela de contexto de 256K–262K tokens, suporte multimodal nativo (texto + visão), modo de raciocínio forçado e recursos aprimorados de chamadas de ferramentas agentic. Ele traz ganhos significativos em relação ao K2.6, incluindo +21,8% no Kimi Code Bench v2, melhor acompanhamento de instruções em contextos longos e ~30% menos uso de tokens de raciocínio para fluxos de trabalho de agentes mais eficientes.
Para desenvolvedores e equipes que buscam acesso econômico e de alto desempenho sem gerenciar várias chaves de API, a CometAPI oferece integração perfeita. A CometAPI apresenta preços competitivos (cerca de $0.76/1M tokens para o Kimi K2.7 Code) junto com 500+ outros modelos, tornando-a ideal para escala em produção, testes e fluxos de trabalho unificados.
O que é o Kimi K2.7 Code
Kimi K2.7 Code é um modelo agentic focado em programação, construído sobre a arquitetura do Kimi K2.6. É um modelo MoE com 1T de parâmetros, 32B ativos, janela de contexto de 256K e forte desempenho em programação de longo alcance e tarefas agentic. Na prática, isso significa que ele é projetado para entender uma grande base de código, planejar mudanças entre arquivos, chamar ferramentas, verificar saídas e continuar sem perder o fio da meada.
A distinção de produto mais importante é simples: o K2.7 Code não é um modelo “chat-first” com programação como complemento. É um modelo code-first, thinking-first, feito para fluxos de trabalho de engenharia de software em que raciocínio, uso de ferramentas e iteração fazem parte do trabalho. Por isso, ele é especialmente atraente para agentes de codificação, assistentes de IDE, revisores de repositórios e pipelines de testes automatizados.
Por que o Kimi K2.7 Code se destaca em 2026
- Supremacia em codificação: Acompanhamento superior de instruções em longos contextos e maiores taxas de sucesso ponta a ponta. Ideal para desenvolvimento full-stack, depuração de grandes bases de código e refinamento iterativo.
- Suporte multimodal nativo: Texto + imagens + vídeos para tarefas de visão-para-código (por exemplo, gerar componentes React a partir de uma demonstração em vídeo).
- Capacidade agentic: Chamadas de ferramentas confiáveis em múltiplas etapas com conteúdo de raciocínio preservado.
- Eficiência: 30% menos uso de tokens de raciocínio se traduzem em ganhos de custo e velocidade.
Como usar a API do Kimi K2.7 Code via CometAPI
A CometAPI expõe o Kimi K2.7 Code por meio de um endpoint compatível com OpenAI, exatamente o que a maioria das equipes deseja: um padrão de integração, muitas opções de modelos. A página do modelo na CometAPI lista o Kimi K2.7 Code a $0.76/M tokens de entrada e $3.19998/M tokens de saída (use kimi-k2.7-code).
Etapa 1: obtenha sua chave CometAPI
Crie uma conta na CometAPI e gere uma chave de API no console da CometAPI. Para sistemas de produção, armazene a chave em variáveis de ambiente ou gerenciadores de segredos em vez de codificá-la diretamente na sua aplicação. A própria documentação da CometAPI recomenda padrões de SDK compatíveis com OpenAI para acelerar a adoção.
Etapa 2: instale o SDK do OpenAI
A API do Kimi é compatível com OpenAI, e a CometAPI segue o mesmo padrão básico. Em Python:
pip install --upgrade openai
Etapa 3: envie sua primeira requisição de texto
Aqui está um exemplo simples em Python para a CometAPI:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["COMETAPI_KEY"],
base_url="https://api.cometapi.com/v1",
)
response = client.chat.completions.create(
model="kimi-k2.7-code",
messages=[
{"role": "system", "content": "You are a senior software engineer."},
{"role": "user", "content": "Refactor this Python function for readability and add type hints."}
],
max_completion_tokens=2048,
stream=False,
)
print(response.choices[0].message.content)
Esse formato de requisição funciona porque a CometAPI e o Kimi seguem semânticas de chat completion no estilo OpenAI, e o K2.7 Code suporta messages, tools, streaming e blocos de conteúdo multimodal na mesma família de endpoints.
Etapa 4: use streaming para uma melhor experiência de produto
Para assistentes de programação interativos, o streaming deve ser o padrão. A CometAPI recomenda explicitamente streaming para UX em produção, e o endpoint de chat do Kimi suporta stream: true. O streaming é importante porque tarefas de geração de código muitas vezes são melhores quando os usuários podem ver o modelo pensar, esboçar um plano e então produzir o código progressivamente.
response = client.chat.completions.create(
model="kimi-k2.7-code",
messages=[
{"role": "system", "content": "You are a coding assistant."},
{"role": "user", "content": "Write a fast API route in FastAPI for uploading CSV files."}
],
stream=True,
max_completion_tokens=2048,
)
for event in response:
delta = event.choices[0].delta
if getattr(delta, "content", None):
print(delta.content, end="")
Capacidade multimodal de ferramentas: upload de arquivos, formatos suportados, fluxo de trabalho
O Kimi K2.7 Code suporta entradas multimodais, possibilitando fluxos de trabalho de visão-para-código como analisar capturas de tela, diagramas, vídeos ou documentos para geração/extração de código.
O Kimi K2.7 Code suporta mensagens multimodais com blocos text, image_url e video_url. A documentação oficial também fornece endpoints de gerenciamento de arquivos para extração, compreensão de imagens e análise de vídeos. A API de upload atualmente permite até 1.000 arquivos por usuário, cada arquivo com até 100 MB, com um limite total de 10 GB em uploads, e o serviço de parsing de arquivos atualmente é gratuito, mas pode ser limitado por taxa durante picos de tráfego.
Quando usar upload de arquivo em vez de base64
Use upload de arquivo quando o ativo for grande, reutilizado em múltiplos prompts ou provável de atingir limites do corpo da requisição. Recomenda-se upload para vídeos muito grandes e para imagens ou vídeos referenciados várias vezes. O tamanho do corpo da requisição é uma restrição prática, e a documentação de visão afirma que imagens em formato de URL não são suportadas lá, sendo necessário base64 para conteúdo de imagem direto.
Restrições de upload de arquivo:
- Limites de tamanho do corpo da requisição se aplicam (use a API de upload para vídeos grandes em vez de base64).
- Para uso repetido ou arquivos grandes: faça upload via endpoint
/v1/filese referencie pelo ID. - Sem imagens em formato de URL (somente base64 para inline). Quantidade de imagens é flexível, mas o tamanho total ≤~100MB por requisição.
Formatos suportados:
- Imagens: png, jpeg, webp, gif (recomendado ≤4K de resolução).
- Vídeos: mp4, mpeg, mov, avi, x-flv, mpg, webm, wmv, 3gpp (recomendado ≤2K de resolução).
- Documentos: Para uploads de arquivo, o Kimi aceita uma ampla gama de formatos, incluindo PDFs, DOCX, XLSX, PPTX, Markdown, HTML, JSON, imagens (com OCR), muitos arquivos de código e tipos comuns de imagem.
Fluxo de trabalho de exemplo: faça upload de um PDF, extraia o conteúdo e analise-o
import os
from pathlib import Path
from openai import OpenAI
client = OpenAI(
api_key=os.environ["COMETAPI_KEY"],
base_url="https://api.cometapi.com/v1",
)
# 1) Upload the file for extraction
file_obj = client.files.create(
file=Path("system-design-spec.pdf"),
purpose="file-extract",
)
# 2) Fetch extracted content
extracted_text = client.files.content(file_id=file_obj.id).text
# 3) Send the extracted text to Kimi K2.7 Code
response = client.chat.completions.create(
model="kimi-k2.7-code",
messages=[
{"role": "system", "content": "You are a technical reviewer."},
{
"role": "user",
"content": (
"Review the following design document and identify missing API edge cases:\n\n"
f"{extracted_text}"
),
},
],
max_completion_tokens=3000,
)
print(response.choices[0].message.content)
Fluxo de trabalho de exemplo: analisar uma imagem inline
import base64
from pathlib import Path
from openai import OpenAI
import os
client = OpenAI(
api_key=os.environ["COMETAPI_KEY"],
base_url="https://api.cometapi.com/v1",
)
img_path = Path("ui-mockup.png")
img_b64 = base64.b64encode(img_path.read_bytes()).decode("utf-8")
response = client.chat.completions.create(
model="kimi-k2.7-code",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Review this UI mockup for accessibility issues."},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{img_b64}"}},
],
}
],
max_completion_tokens=1500,
)
print(response.choices[0].message.content)
Fluxo de trabalho de exemplo: análise de vídeo com um loop de ferramenta
O guia rápido oficial demonstra um loop multimodal de ferramenta em que o modelo pede para inspecionar um clipe de vídeo, seu código extrai esse clipe e você fornece o resultado de volta como saída da ferramenta. Esse é o modelo mental correto para o K2.7 Code: o modelo planeja, a ferramenta executa, e o modelo continua com as novas evidências.
modelo mental para o K2.7 Code: o modelo planeja, a ferramenta executa, e o modelo continua com as novas evidências.
import base64
from pathlib import Path
from openai import OpenAI
import os
client = OpenAI(
api_key=os.environ["COMETAPI_KEY"],
base_url="https://api.cometapi.com/v1",
)
img_path = Path("ui-mockup.png")
img_b64 = base64.b64encode(img_path.read_bytes()).decode("utf-8")
response = client.chat.completions.create(
model="kimi-k2.7-code",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Review this UI mockup for accessibility issues."},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{img_b64}"}},
],
}
],
max_completion_tokens=1500,
)
print(response.choices[0].message.content)
Diferenças de parâmetros no corpo da requisição vs K2.6
Esta é a seção que as equipes geralmente passam rápido demais, e é aí que começa a dor. O K2.7 Code compartilha o mesmo formato geral de chat-completions do K2.6, mas vários comportamentos no corpo da requisição são rigidamente definidos. O temperature é fixo em 1.0, top_p em 0.95, n em 1, e ambos presence_penalty e frequency_penalty em 0.0. Mais importante, o modelo retornará erro se você tentar desativar o raciocínio.
Aqui está a versão prática para engenheiros: não ajuste o K2.7 Code como um modelo criativo de uso geral. Mantenha os padrões, foque em bons prompts e concentre seus esforços na definição da tarefa, no design de ferramentas e na verificação. Em outras palavras, o modelo é menos sobre “controle de aleatoriedade” e mais sobre “controle de fluxo de trabalho”.
Kimi K2.7 Code vs K2.6: as diferenças no corpo da requisição que importam
| Recurso | Kimi K2.7 Code | Kimi K2.6 | Por que isso importa |
|---|---|---|---|
| Modo de raciocínio | Sempre ativado; "disabled" gera erros | Pode ser ativado ou desativado | O K2.7 é mais simples para fluxos de trabalho de agentes, pois não há alternância por requisição. |
| Raciocínio preservado | Sempre ativado; thinking.keep é tratado como "all" | Opcional via thinking.keep | Sessões de codificação multi-turn devem manter reasoning_content intacto. |
| Temperature | Fixa em 1.0 | Configurável | Você não deve ajustar o K2.7 com valores de amostragem arbitrários. |
| Top-p | Fixa em 0.95 | Configurável | Mantenha o modelo nos padrões suportados. |
| n | Fixa em 1 | Configurável | Você recebe um resultado por requisição, o que se encaixa bem em loops de agentes. |
| Penalidades | Fixas em 0.0 | Configuráveis | Evite passar ajustes não suportados. |
| Contexto | 256K | 256K | Ambos lidam com grandes repositórios, mas o K2.7 é mais especializado em codificação. |
| Velocidade de saída | Variante de alta velocidade ~180 tokens/s, até 260 em contextos curtos | Não destacado da mesma forma | Útil quando a latência importa mais do que o controle absoluto. |
A principal conclusão é que o K2.7 Code é intencionalmente menos configurável que o K2.6 em troca de uma experiência de codificação mais opinativa. Você deve confiar nos valores padrão em vez de lutar contra o comportamento fixo do modelo. Isso é um recurso, não um bug, para agentes de codificação.
Fonte: Documentação oficial da Moonshot. O K2.7 Code força o modo de raciocínio e preserva o reasoning para etapas múltiplas confiáveis de codificação. Use extra_body para parâmetros de raciocínio se surgirem limitações do SDK.
Essas restrições reduzem a variabilidade nos loops de agentes, melhorando as taxas de sucesso, mas exigindo ajustes de fluxo de trabalho em relação ao uso geral do K2.6.
Compatibilidade de uso de ferramentas e precauções
O Kimi K2.7 Code oferece chamadas de ferramentas multi-turn robustas, compatíveis com formatos OpenAI/Anthropic. Ele suporta ferramentas oficiais (pesquisa na web, executor de código, Excel, memória, etc.) e funções personalizadas.
Destaques de compatibilidade:
- Chamadas completas de função/ferramenta com suporte paralelo e sequencial.
- Raciocínio intercalado + chamadas de ferramentas preservadas entre turnos.
- Funciona bem com frameworks de agentes como Kimi Code CLI, Hermes Agent, extensões do VS Code, Cline/RooCode.
Precauções (críticas para estabilidade):
- tool_choice: Estritamente "auto" ou "none". Outros valores causam erros.
- Multi-step: Sempre retenha a mensagem completa do assistente (incluindo reasoning_content) no array de mensagens subsequentes. Removê-la dispara erros.
- Gerenciamento de contexto: Com 256K de contexto, resuma ou faça pruning de forma criteriosa; visão adiciona overhead de tokens.
- Limites de taxa/orçamentos: Defina limites de gastos diários nos projetos Moonshot/CometAPI. Monitore possíveis atrasos de parsing de arquivos em horários de pico.
- Visão + ferramentas: Arquivos grandes devem usar o endpoint de upload; teste limites de resolução.
- Tratamento de erros: Implemente tentativas (retries) para loops de chamadas de ferramentas; o modelo pode precisar de orientação explícita em prompts de sistema para agentes complexos.
Por que o CometAPI é uma forma inteligente de colocar este modelo em produção
O maior diferencial da CometAPI não é apenas o acesso; é a redução do atrito de integração. A plataforma apresenta o Kimi K2.7 Code por meio de um único endpoint compatível com OpenAI, o que significa que você pode reutilizar os mesmos SDKs, middlewares, retries, código de streaming e padrões de observabilidade que já utiliza para outros provedores. A página do modelo da CometAPI também posiciona o serviço como uma rota de menor custo em comparação ao preço oficial, com um desconto publicado de 20% na página de preços do K2.7 Code.
Conclusão: comece a construir com o CometAPI hoje
Se o seu produto envolve codificação em escala de repositório, depuração em múltiplas etapas, orquestração de ferramentas ou análise multimodal, o Kimi K2.7 Code merece uma análise séria. Os sinais mais fortes do modelo não são o polimento de chat genérico; são a confiabilidade em longos contextos, raciocínio preservado, comportamento de requisição fixo porém previsível e melhores resultados de benchmarks de codificação reportados pelo fornecedor em relação ao K2.6. Ao adicionar a CometAPI, você obtém um caminho muito prático para produção: uma integração compatível com OpenAI, uma troca de modelo e uma forma mais limpa de disponibilizar agentes de codificação em escala.
Cadastre-se na CometAPI, obtenha sua chave e teste o Kimi K2.7 Code em minutos. Para integrações personalizadas ou suporte corporativo, explore a documentação da CometAPI.