GLM-5.2 کی تکنیکی خصوصیات
| آئٹم | GLM-5.2 |
|---|---|
| فراہم کنندہ | Zhipu AI |
| ریلیز کی تاریخ | 13 جون، 2026 |
| ماڈل کی قسم | اوپن-ویٹ Mixture-of-Experts (MoE) LLM |
| کل پیرامیٹرز | ~744B |
| فعال پیرامیٹرز | ہر ٹوکن پر ~40B |
| کانٹیکسٹ وِنڈو | 1,000,000 ٹوکنز |
| زیادہ سے زیادہ آؤٹ پٹ | 131,072 ٹوکنز |
| استدلالی موڈز | High, Max |
| لائسنس | MIT |
| بنیادی فوکس | ایجنٹک کوڈنگ، سافٹ ویئر انجینیئرنگ، طویل المدتی استدلال |
| API دستیابی | Z.ai پلیٹ فارم اور مطابقت رکھنے والے فراہم کنندگان |
| اوپن ویٹس | ہاں |
GLM-5.2، Zhipu AI کے GLM خاندان کا تازہ ترین فلیگ شپ ماڈل ہے۔ عمومی مقصد کے فرنٹیئر ماڈلز کے برعکس، GLM-5.2 بنیادی طور پر کوڈنگ-فرسٹ اور ایجنٹ پر مبنی ماڈل کے طور پر پوزیشن کیا گیا ہے، جو ریپوزٹری پیمانے کی سافٹ ویئر انجینیئرنگ، خودمختار ورک فلو اور انتہائی طویل کانٹیکسٹ استدلال کے لیے تیار کیا گیا ہے۔ اس کی نمایاں صلاحیت 1 ملین ٹوکن کا نیٹو کانٹیکسٹ وِنڈو ہے، جو اوپن-ویٹ ماڈلز میں عوامی طور پر دستیاب سب سے بڑے کانٹیکسٹ وِنڈوز میں سے ایک ہے۔
GLM-5.2 کی اہم خصوصیات
- پورے ریپوزٹریز، طویل دستاویزی سیٹوں اور ملٹی سیشن ایجنٹ ورک فلو کے لیے 1M-ٹوکن کانٹیکسٹ وِنڈو۔
- ری فیکٹرنگ، ڈیبگنگ، کوڈ جنریشن اور سافٹ ویئر انجینیئرنگ کاموں پر مرکوز کوڈنگ-فرسٹ آپٹمائزیشن۔
- Claude Code، Cline، Roo Code، OpenCode اور اسی طرز کے کوڈنگ ایجنٹس جیسے ٹولز کے لیے ایجنٹک ورک فلو سپورٹ۔
- MIT لائسنس کے تحت اوپن-ویٹ ریلیز، جو سیلف ہوسٹنگ اور فائن ٹیوننگ کو ممکن بناتی ہے۔
- دو استدلالی موڈز (High اور Max)، جو لیٹنسی اور استدلال کی گہرائی کے درمیان توازن کی اجازت دیتے ہیں۔
- بڑا MoE آرکیٹیکچر، تقریباً 744B کل پیرامیٹرز کے ساتھ، جبکہ کارکردگی کے لیے فی ٹوکن صرف ~40B فعال ہوتے ہیں۔
GLM-5.2 کی بینچ مارک کارکردگی
Zhipu نے لانچ کے وقت جامع سرکاری بینچ مارک نتائج شائع نہیں کیے، جس سے براہِ راست موازنہ GPT-5 یا Claude جیسے ماڈلز کے مقابلے میں زیادہ غیر یقینی ہو جاتا ہے۔ متعدد صنعتی رپورٹس آزادانہ طور پر توثیق شدہ بینچ مارک ریلیزز کی عدم موجودگی کی نشاندہی کرتی ہیں۔
| بینچ مارک | رپورٹ کردہ اسکور |
|---|---|
| Terminal-Bench 2.1 | 81.0 |
| SWE-Bench Pro | 62.1 |
| NL2Repo | 48.9 |
| AIME 2026 | 99.2 |
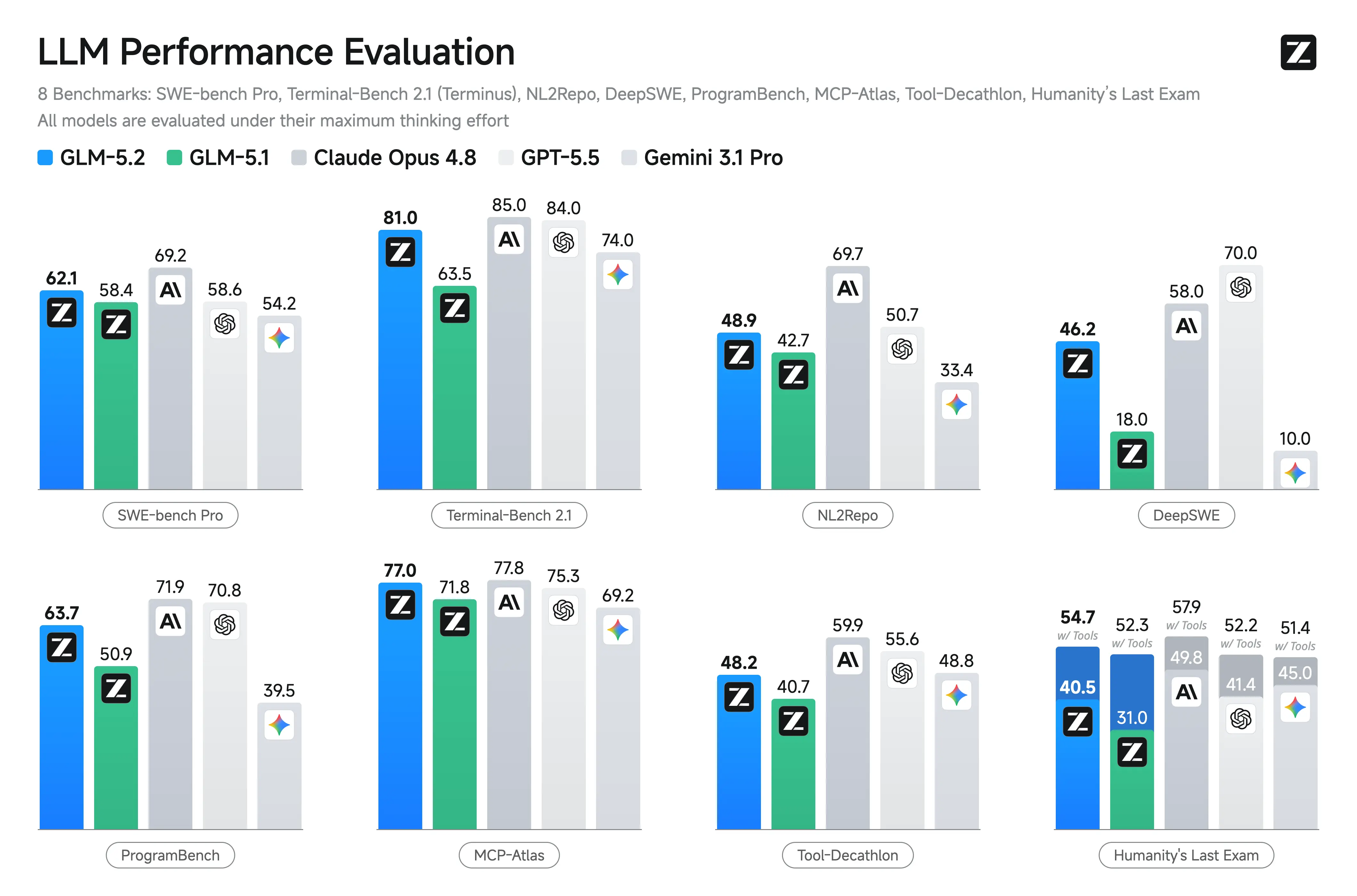
GLM-5.2 بمقابلہ GLM-5.1 بمقابلہ Claude Opus 4.8
| تفصیل | GLM-5.2 | GLM-5.1 | Claude Opus 4.8 |
|---|---|---|---|
| ریلیز کی تاریخ | 2026-06-13 | 2026 | 2026 |
| کانٹیکسٹ وِنڈو | 1,000,000 | ~200,000 | 1,000,000 |
| اوپن ویٹس | ہاں (MIT) | ہاں | نہیں |
| استدلالی موڈز | High, Max | Standard | Extended Thinking |
| کل پیرامیٹرز | 744B | 744B | ظاہر نہیں کیا گیا |
| فعال پیرامیٹرز | 40B | 40B | ظاہر نہیں کیا گیا |
| سرکاری بینچ مارک ڈیٹا | شائع نہیں | لانچ کے وقت شائع | شائع شدہ |
GLM-5.2 کی GLM-5.1 پر بنیادی دستاویزی اپ گریڈ اس کے 1M-ٹوکن کانٹیکسٹ وِنڈو تک توسیع اور منتخب کیے جانے والے High اور Max استدلالی موڈز کا تعارف ہے۔ لانچ کے وقت، Z.ai نے سرکاری SWE-Bench، LiveCodeBench، HumanEval یا اسی نوعیت کے بینچ مارک نتائج شائع نہیں کیے، لہٰذا Claude Opus 4.8، GPT-5، DeepSeek یا Qwen ماڈلز کے مقابلے میں کارکردگی کے موازنے غیر مصدقہ رہتے ہیں۔
دیگر اوپن ماڈلز کے مقابلے میں، GLM-5.2 کا بنیادی امتیاز اس کا بہت بڑا کانٹیکسٹ وِنڈو، کوڈنگ میں مہارت، اور MIT لائسنسنگ کا امتزاج ہے۔ اس کی سب سے مضبوط کشش عمومی چیٹ ایپلی کیشنز کے بجائے ریپوزٹری پیمانے کی سافٹ ویئر انجینیئرنگ ہے۔
CometAPI کے ذریعے GLM-5.2 کیوں استعمال کریں؟
CometAPI ڈویلپرز کو GLM-5.2 کو اسی انٹرفیس کے ذریعے ضم کرنے کی اجازت دیتا ہے جو درجنوں سرکردہ AI ماڈلز کے لیے استعمال ہوتا ہے۔
فوائد میں شامل ہیں:
- متعدد فراہم کنندگان پر یکساں تصدیق
- OpenAI مطابقت رکھنے والا API انضمام
- بلنگ اور استعمال کے انتظام میں سادگی
- متبادل ماڈلز کے ساتھ تیز رفتار تجربہ
- کوڈنگ، استدلال، امیج، آڈیو اور ویڈیو ماڈلز کے درمیان آسان سوئچنگ
- پروڈکشن سسٹمز کے لیے وینڈر لاک اِن میں کمی
چاہے آپ AI IDE، اندرونی انجینیئرنگ اسسٹنٹ، یا انٹرپرائز آٹومیشن پلیٹ فارم بنا رہے ہوں، CometAPI کم سے کم انضمامی محنت کے ساتھ لچک برقرار رکھتا ہے۔
CometAPI پر GLM-5.2 API تک کیسے رسائی حاصل کریں
صرف چند سادہ مراحل میں ہمارے پروڈکٹ کے ساتھ آغاز کریں...
مرحلہ 1: اپنی GLM-5.2 API کلید کے لیے سائن اپ کریں
Kie.ai پر اکاؤنٹ بنائیں اور API ڈیش بورڈ پر جائیں تاکہ اپنی GLM-5.2 API کلید جنریٹ کریں۔ یہ کلید آپ کی تمام درخواستوں کو مستند کرتی ہے اور آپ کو GLM-5.2 API کی مکمل صلاحیتوں تک فوری رسائی دیتی ہے، جن میں 1M ٹوکن کانٹیکسٹ وِنڈو اور 128k آؤٹ پٹ ٹوکنز شامل ہیں۔
مرحلہ 2: GLM-5.2 API کو درخواستیں بھیجیں
اپنی GLM-5.2 API کلید استعمال کرتے ہوئے Kie.ai اینڈ پوائنٹ پر POST درخواستیں بھیجیں۔ اپنا پرامپٹ پاس کریں، ماڈل کے پیرامیٹرز جیسے کوشش کی سطح اور زیادہ سے زیادہ ٹوکنز سیٹ کریں، اور GLM-5.2 API آپ کی درخواست پروسیس کرے گا — کوڈ جنریشن سے لے کر دستاویزاتی تجزیہ اور ایجنٹک ٹول کے استعمال تک ہر چیز کو ہینڈل کرتے ہوئے۔
مرحلہ 3: نتائج حاصل کریں اور GLM-5.2 API کو ضم کریں
GLM-5.2 API ساختہ جوابات فراہم کرتا ہے، جن میں کمپلیشن ٹیکسٹ، ٹول کالنگ ہدایات، اور ٹوکن استعمال کی میٹا ڈیٹا شامل ہوتی ہے۔ یہ معیاری ہم وقتی جوابات اور جب stream: true کنفیگر ہو تو Server-Sent Events (SSE) کے ذریعے ریئل ٹائم اسٹریمنگ دونوں کو سپورٹ کرتا ہے۔ اینڈ پوائنٹ کو آپ کے موجودہ ورک فلو میں آسانی سے ضم کیا جا سکتا ہے، معیاری HTTP کلائنٹس یا OpenAI مطابقت رکھنے والے SDKs کے ذریعے درخواستوں کو آپ کے Bearer Token کے ساتھ url(//api.cometapi.com/v1) سے روٹ کر کے۔