

في 19–20 نوفمبر 2025 أصدرت OpenAI ترقيتين مترابطتين لكن متميزتين: GPT-5.1-Codex-Max، نموذج ترميز قائم على الوكيل جديد لـ Codex يركّز على البرمجة بعيدة الأفق، وكفاءة الرموز، و«الضغط» للحفاظ على الجلسات متعددة النوافذ؛ وGPT-5.1 Pro، نموذج ChatGPT من فئة Pro محدَّث تم ضبطه لإجابات أوضح وأكثر قدرة في الأعمال المهنية المعقدة.
ما هو GPT-5.1-Codex-Max وما المشكلة التي يحاول حلّها؟
GPT-5.1-Codex-Max هو نموذج Codex متخصص من OpenAI مضبوط لسير عمل البرمجة التي تتطلب استدلالًا وتنفيذًا مستدامين بعيدي الأفق. فحين قد تتعثر النماذج العادية أمام السياقات الطويلة للغاية — مثل عمليات إعادة الهيكلة عبر ملفات متعددة، أو حلقات الوكلاء المعقدة، أو مهام CI/CD المستمرة — صُمِّم Codex-Max ليقوم بـ ضغطٍ وإدارةٍ تلقائيين لحالة الجلسة عبر نوافذ سياق متعددة، مما يمكّنه من مواصلة العمل بشكل متماسك بينما يمتد المشروع الواحد عبر آلاف (أو أكثر) من الرموز. تضع OpenAI Codex-Max كخطوة تالية لجعل الوكلاء القادرين على البرمجة مفيدين حقًا لأعمال الهندسة الممتدة.
ما هو GPT-5.1-Codex-Max وما المشكلة التي يحاول حلّها؟
GPT-5.1-Codex-Max هو نموذج Codex متخصص من OpenAI مضبوط لسير عمل البرمجة التي تتطلب استدلالًا وتنفيذًا مستدامين بعيدي الأفق. فحين قد تتعثر النماذج العادية أمام السياقات الطويلة للغاية — مثل عمليات إعادة الهيكلة عبر ملفات متعددة، أو حلقات الوكلاء المعقدة، أو مهام CI/CD المستمرة — صُمِّم Codex-Max ليقوم بـ ضغطٍ وإدارةٍ تلقائيين لحالة الجلسة عبر نوافذ سياق متعددة، مما يمكّنه من مواصلة العمل بشكل متماسك بينما يمتد المشروع الواحد عبر آلاف (أو أكثر) من الرموز.
تصفه OpenAI بأنه «أسرع، وأذكى، وأكثر كفاءة في الرموز في كل مرحلة من دورة التطوير»، وهو مُعدّ صراحةً ليحل محل GPT-5.1-Codex بوصفه النموذج الافتراضي في واجهات Codex.
لمحة عن الميزات
- الضغط لاستمرارية متعددة النوافذ: يُشذِّب ويحفظ السياق الحرج للعمل بشكل متماسك عبر ملايين الرموز ولساعات. 0
- تحسين كفاءة الرموز مقارنةً بـ GPT-5.1-Codex: حتى نحو ~30% رموز تفكير أقل لنفس جهد الاستدلال على بعض معايير الشيفرة.
- متانة وكيلية بعيدة الأفق: لوحِظ داخليًا أنه يحافظ على حلقات وكيل لعدّة ساعات/أيام (وثّقت OpenAI تشغيلات داخلية لأكثر من 24 ساعة).
- تكاملات المنصّة: متاح اليوم داخل CLI الخاص بـ Codex، وملحقات IDE، والسحابة، وأدوات مراجعة الشيفرة؛ إتاحة واجهة API قادمة.
- دعم بيئة Windows: تشير OpenAI تحديدًا إلى أن Windows مدعوم لأول مرة في سير عمل Codex، ما يوسّع الوصول لمطوّرين في العالم الحقيقي.
كيف يقارن بالمنتجات المنافسة (مثل GitHub Copilot وغيرها من مساعدي البرمجة بالذكاء الاصطناعي)؟
يُقدَّم GPT-5.1-Codex-Max بوصفه متعاونًا أكثر استقلالية وبعيد الأفق مقارنة بأدوات الإكمال لكل طلب. فبينما يبرع Copilot ومساعدون مماثلون في الإكمالات قصيرة الأجل داخل المحرّر، تكمن قوة Codex-Max في تنسيق المهام متعددة الخطوات، والحفاظ على حالة متماسكة عبر الجلسات، والتعامل مع سير العمل التي تتطلب تخطيطًا واختبارًا وتكرارًا. ومع ذلك، فإن النهج الأمثل لدى معظم الفرق سيكون هجينًا: استخدم Codex-Max للأتمتة المعقدة والمهام الوكيلية المستمرة، واستخدم مساعدين أخف لعمليات الإكمال على مستوى السطر.
كيف يعمل GPT-5.1-Codex-Max؟
ما هو «الضغط» وكيف يمكّن من العمل طويل الأمد؟
التقدم التقني المركزي هو الضغط — آلية داخلية تُقلّم تاريخ الجلسة مع الحفاظ على الأجزاء البارزة من السياق بحيث يمكن للنموذج مواصلة العمل المتماسك عبر عدّة نوافذ سياق. عمليًا، يعني ذلك أن جلسات Codex عند اقترابها من حد السياق سيتم ضغطها (تلخيص/حفظ الرموز الأقدم أو الأقل قيمة) بحيث يحصل الوكيل على نافذة جديدة ويمكنه متابعة التكرار مرارًا حتى تكتمل المهمة. تشير تقارير OpenAI إلى تشغيلات داخلية عمل فيها النموذج على مهام بشكل متواصل لأكثر من 24 ساعة.
الاستدلال التكيفي وكفاءة الرموز
يطبّق GPT-5.1-Codex-Max استراتيجيات استدلال محسّنة تجعله أكثر كفاءة في الرموز: ففي معايير OpenAI الداخلية المبلَّغ عنها، يحقق نموذج Max أداءً مماثلًا أو أفضل من GPT-5.1-Codex مع استخدام عدد أقل بكثير من «رموز التفكير» — وتذكر OpenAI حوالي 30% أقل من رموز التفكير على SWE-bench Verified عند تشغيل جهد استدلال متساوٍ. كما يقدّم النموذج وضع جهد الاستدلال «Extra High (xhigh)» للمهام غير الحساسة لزمن الاستجابة، ما يسمح له بإنفاق استدلال داخلي أكبر للحصول على مخرجات أعلى جودة.
التكاملات النظامية وأدوات الوكلاء
يتم توزيع Codex-Max ضمن سير عمل Codex (CLI، وملحقات IDE، والسحابة، وأسطح مراجعة الشيفرة) بحيث يمكنه التفاعل مع سلاسل أدوات المطوّرين الفعلية. تشمل التكاملات المبكّرة CLI الخاص بـ Codex وعملاء IDE (VS Code، JetBrains، إلخ)، مع التخطيط لإتاحة واجهة API لاحقًا. الهدف التصميمي ليس مجرد توليد شيفرة أذكى، بل ذكاء اصطناعي قادر على تشغيل سير عمل متعددة الخطوات: فتح الملفات، تشغيل الاختبارات، إصلاح الإخفاقات، إعادة الهيكلة، وإعادة التشغيل.
كيف يؤدّي GPT-5.1-Codex-Max على المعايير والعمل الحقيقي؟
الاستدلال المستدام والمهام بعيدة الأفق
تشير التقييمات إلى تحسّن ملموس في الاستدلال المستدام والمهام بعيدة الأفق:
- تقييمات OpenAI الداخلية: يستطيع Codex-Max العمل على مهام «لأكثر من 24 ساعة» في تجارب داخلية وأن تكامل Codex مع أدوات المطوّرين زاد مقاييس الإنتاجية الهندسية الداخلية (مثل الاستخدام ومعدلات دمج طلبات السحب). هذه ادّعاءات داخلية من OpenAI وتدل على تحسينات على مستوى المهام في الإنتاجية الواقعية.
- تقييمات مستقلة (METR): قاس تقرير METR المستقل أفق الوقت الملحوظ بنسبة 50% (إحصائية تمثّل الزمن الوسيط الذي يمكن للنموذج خلاله الحفاظ على مهمة طويلة بشكل متماسك) لـ GPT-5.1-Codex-Max بحوالي 2 ساعة و40 دقيقة (مع مجال ثقة واسع)، ارتفاعًا من 2 ساعة و17 دقيقة لـ GPT-5 في قياسات مماثلة — وهو تحسّن ذو دلالة في التماسك بعيد الأفق. تؤكد منهجية METR والتكامل المستمر وجود تباين، لكن النتيجة تدعم السرد القائل إن Codex-Max يحسّن الأداء العملي بعيد الأمد.
معايير الشيفرة
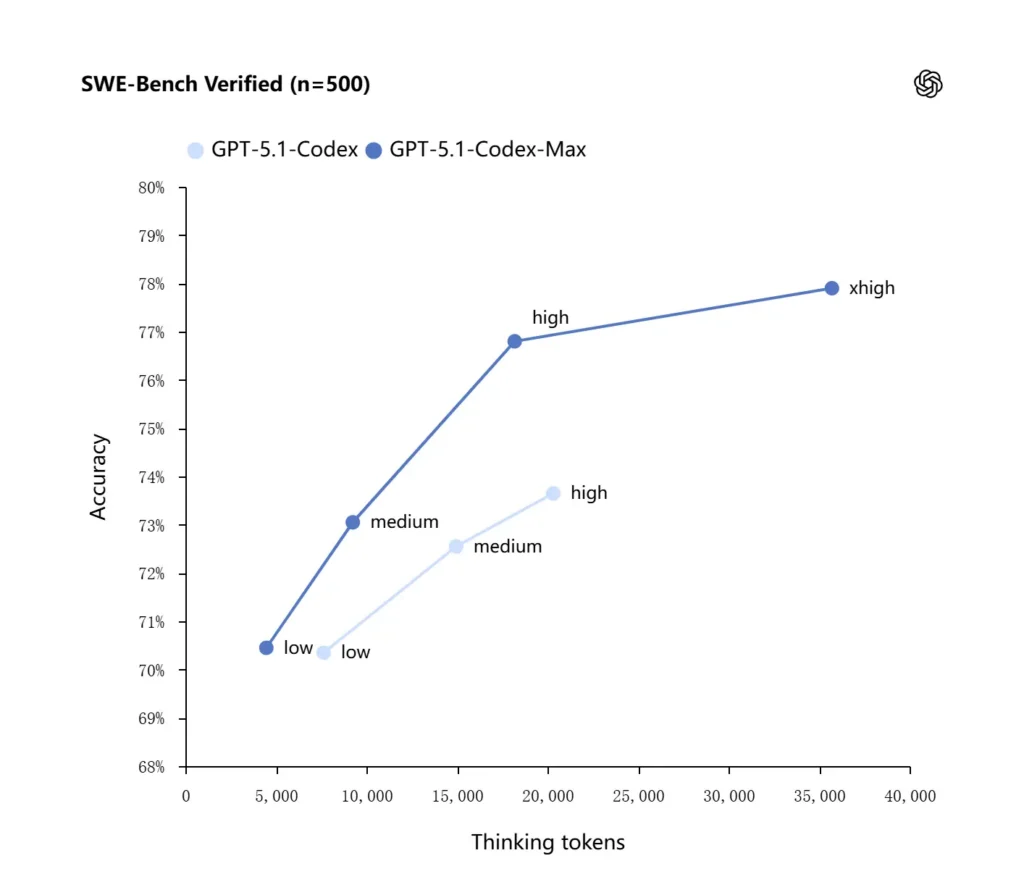
تذكر OpenAI نتائج محسّنة على تقييمات البرمجة المتقدّمة، ولا سيما SWE-bench Verified حيث يتفوّق GPT-5.1-Codex-Max على GPT-5.1-Codex مع كفاءة أفضل في الرموز. وتبرز الشركة أنه لنفس «جهد الاستدلال المتوسط» ينتج نموذج Max نتائج أفضل مع استخدام نحو 30% أقل من رموز التفكير؛ وللمستخدمين الذين يسمحون باستدلال داخلي أطول، يمكن لوضع xhigh رفع جودة الإجابات على حساب الكمون.
| GPT‑5.1-Codex (high) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench Verified (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
كيف يقارن GPT-5.1-Codex-Max مع GPT-5.1-Codex؟
فروقات الأداء والغرض
- النطاق: كان GPT-5.1-Codex نسخة ترميز عالية الأداء من عائلة GPT-5.1؛ أما Codex-Max فهو خليفة وكيلّي بعيد الأفق مقصود به أن يكون الافتراضي الموصى به لبيئات Codex وما شابهها.
- كفاءة الرموز: يُظهر Codex-Max مكاسب مادية في كفاءة الرموز (ادّعاء OpenAI بنحو ~30% أقل من رموز التفكير) على SWE-bench وفي الاستخدام الداخلي.
- إدارة السياق: يقدّم Codex-Max الضغط والمعالجة الأصلية متعددة النوافذ للحفاظ على المهام التي تتجاوز نافذة سياق واحدة؛ لم يوفّر Codex هذه الإمكانية أصلاً على نفس النطاق.
- جاهزية الأدوات: يُشحن Codex-Max كنموذج Codex الافتراضي عبر CLI وIDE وأساليب مراجعة الشيفرة، ما يشير إلى انتقال في سير العمل الإنتاجية للمطوّرين.
متى تستخدم أي نموذج؟
- استخدم GPT-5.1-Codex للمساعدة التفاعلية في البرمجة، والتعديلات السريعة، وإعادة الهيكلة الصغيرة، وحالات الكمون المنخفض حيث يلائم السياق ذي الصلة نافذة واحدة بسهولة.
- استخدم GPT-5.1-Codex-Max لإعادة الهيكلة عبر ملفات متعددة، والمهام الوكيلية المؤتمتة التي تتطلب دورات تكرار عديدة، وسير العمل الشبيهة بـ CI/CD، أو عندما تحتاج أن يحتفظ النموذج بمنظور على مستوى المشروع عبر تفاعلات كثيرة.
أنماط التوجيه العملية وأمثلة لأفضل النتائج؟
أنماط التوجيه التي تعمل جيدًا
- كن صريحًا بشأن الأهداف والقيود: «أعد هيكلة X، حافظ على الواجهة البرمجية العامة، أبقِ أسماء الدوال، وتأكد من اجتياز الاختبارات A وB وC.»
- قدّم سياقًا قابلًا لإعادة الإنتاج بأقل قدر: اربط بالاختبار الفاشل، وأدرج تتبعات المكدس ومقتطفات الملفات ذات الصلة بدلًا من تفريغ المستودعات كاملة. سيقوم Codex-Max بضغط التاريخ عند الحاجة.
- استخدم تعليمات متدرجة للمهام المعقدة: جزّئ المهام الكبيرة إلى تسلسل من المهام الفرعية، ودع Codex-Max يكرّر عبرها (مثل «1) شغّل الاختبارات 2) أصلح أعلى 3 اختبارات فاشلة 3) شغّل أداة التحقق من الأسلوب 4) لخّص التغييرات»).
- اطلب الشروح والاختلافات (diffs): اطلب التصحيح مع مبرّر موجز حتى يتمكّن المراجعون البشر من تقييم الأمان والنية بسرعة.
قوالب أمثلة للتوجيه
مهمة إعادة هيكلة
«أعد هيكلة وحدة
payment/لاستخراج معالجة الدفع إلىpayment/processor.py. أبقِ تواقيع الدوال العامة مستقرة للمستدعين الحاليين. أنشئ اختبارات وحدات لـprocess_payment()تغطي النجاح، وفشل الشبكة، وبطاقة غير صالحة. شغّل مجموعة الاختبارات وأعد الاختبارات الفاشلة وتصحيحًا بصيغة diff موحّدة.»
إصلاح عطل + اختبار
«الاختبار
tests/test_user_auth.py::test_token_refreshيفشل مع تتبّع. حقّق في السبب الجذري، واقترح إصلاحًا بأقل تغييرات، وأضف اختبار وحدة لمنع التراجع. طبّق التصحيح وشغّل الاختبارات.»
توليد PR تكراري
«نفّذ الميزة X: أضف نقطة النهاية
POST /api/exportالتي تبث نتائج التصدير وتكون موثّقة. أنشئ نقطة النهاية، أضف توثيقًا، أنشئ اختبارات، وافتح طلب سحب مع ملخص وقائمة تحقق بالعناصر اليدوية.»
لأغلب هذه الحالات، ابدأ بـ medium؛ وانتقل إلى xhigh عندما تحتاج أن يقوم النموذج باستدلال عميق عبر ملفات كثيرة وعدّة دورات اختبارات.
كيف تصل إلى GPT-5.1-Codex-Max
أين يتوفر اليوم
لقد دمجت OpenAI GPT-5.1-Codex-Max في أدوات Codex اليوم: يستخدم CLI الخاص بـ Codex وملحقات IDE والسحابة وتدفّقات مراجعة الشيفرة Codex-Max بشكل افتراضي (يمكنك اختيار Codex-Mini). تتهيأ إتاحة واجهة API؛ لدى GitHub Copilot معاينات عامة تتضمن نماذج GPT-5.1 وسلسلة Codex.
يمكن للمطورين الوصول إلى GPT-5.1-Codex-Max وGPT-5.1-Codex API عبر CometAPI. للبدء، استكشف قدرات النماذج في CometAPI ضمن Playground واطّلع على دليل واجهة API للحصول على إرشادات مفصّلة. قبل الوصول، يُرجى التأكد من تسجيل الدخول إلى CometAPI والحصول على مفتاح API. تقدّم CometAPI سعرًا أقل بكثير من السعر الرسمي لمساعدتك على الدمج.
هل أنت جاهز للانطلاق؟ → سجّل في CometAPI اليوم!
إذا أردت المزيد من النصائح والإرشادات والأخبار حول الذكاء الاصطناعي فاتبعنا على VK، وX، وDiscord!
البدء السريع (خطوات عملية متتابعة)
- تأكد من أن لديك صلاحية الوصول: أكّد أن خطة منتج ChatGPT/Codex لديك (Plus أو Pro أو Business أو Edu أو Enterprise) أو خطة واجهة المطوّرين تدعم نماذج عائلة GPT-5.1/Codex.
- ثبّت CLI الخاص بـ Codex أو ملحق IDE: إذا أردت تشغيل مهام الشيفرة محليًا، ثبّت CLI الخاص بـ Codex أو ملحق IDE لـ VS Code / JetBrains / Xcode حسب الاقتضاء. ستعتمد الأدوات GPT-5.1-Codex-Max افتراضيًا في الإعدادات المدعومة.
- اختر جهد الاستدلال: ابدأ بجهد medium لمعظم المهام. لأغراض التصحيح العميق وإعادة الهيكلة المعقدة، أو عندما تريد أن يفكّر النموذج أكثر ولا تهمّك كمونات الاستجابة، انتقل إلى high أو xhigh. للإصلاحات الصغيرة السريعة، يُعد low معقولًا.
- وفّر سياق المستودع: امنح النموذج نقطة انطلاق واضحة — عنوان مستودع أو مجموعة ملفات وتعليمات قصيرة (مثل «أعد هيكلة وحدة الدفع لاستخدام I/O غير متزامن وأضف اختبارات وحدات، أبقِ العقود على مستوى الدوال»). سيضغط Codex-Max التاريخ أثناء اقترابه من حدود السياق ويتابع المهمة.
- كرّر مع الاختبارات: بعد أن ينتج النموذج التصحيحات، شغّل مجموعات الاختبارات وامدده بالإخفاقات كجزء من الجلسة الجارية. يتيح الضغط والاستمرارية متعددة النوافذ لـ Codex-Max الاحتفاظ بسياق الاختبارات الفاشلة الهامة والتكرار.
الخلاصة:
يمثل GPT-5.1-Codex-Max خطوة كبيرة نحو مساعدي برمجة وكيلية يمكنها الحفاظ على مهام هندسية معقدة وطويلة التشغيل بكفاءة واستدلال محسّنين. تجعل التطورات التقنية (الضغط، أوضاع جهد الاستدلال، تدريب بيئة Windows) منه مناسبًا للغاية للمؤسسات الهندسية الحديثة — بشرط أن تقرن الفرق النموذج بضوابط تشغيلية محافظة، وسياسات واضحة لإشراك البشر في الدورة، ورقابة قوية. بالنسبة للفرق التي تتبناه بعناية، يمتلك Codex-Max القدرة على تغيير كيفية تصميم البرمجيات واختبارها وصيانتها — محوّلًا الأعمال الهندسية الرتيبة إلى تعاون أعلى قيمة بين البشر والنماذج.