

I den hastigt udviklende verden af AI‑kodeassistenter skiller Moonshot AIs lancering af Kimi K2.7 Code den 12. juni 2026 sig ud som et markant spring for udviklere, AI‑agenter og virksomheder, der søger kraftfulde, omkostningseffektive og open‑source løsninger.
Denne specialiserede kodemodel bygger på K2‑familien og fokuserer på lang‑horisont software‑engineering‑opgaver, pålidelig instruktionsefterlevelse i massive kontekster, fleromgangs kald af værktøjer, visuelle input og strukturerede output til agentorienterede arbejdsgange. Med 1 billion samlede parametre, men kun 32 milliarder aktiveret pr. token via et Mixture‑of‑Experts (MoE)‑design, leverer den kapabiliteter på frontier‑niveau til en brøkdel af omkostningen ved lukkede modeller som Claude Opus 4.8 eller GPT‑5.5.
CometAPI har nu integreret Kimi K2.7 Code, så den er problemfrit tilgængelig via et enkelt OpenAI‑kompatibelt endepunkt til lavere pris end den officielle pris. Denne integration gør det muligt for udviklere at skifte modeller uden besvær, optimere omkostninger og bygge robuste AI‑drevne applikationer uden at skulle håndtere flere udbydere.
Hvad er Kimi K2.7 Code?
Kimi K2.7 Code (også kaldet Kimi‑K2.7‑Code eller kimi‑k2.7‑code) er en kodefokuseret, agentisk Mixture‑of‑Experts (MoE)‑model udviklet af Moonshot AI. Den er eksplicit bygget til lang‑horisont software‑engineering‑opgaver—scenarier hvor en AI skal fastholde kontekst over tusindvis af skridt, navigere i repositories, kalde værktøjer, redigere kode på tværs af moduler, køre tests, debugge og iterere til færdiggørelse.
Nøglekarakteristika:
- Åbne vægte på Hugging Face (
moonshotai/Kimi-K2.7-Code). - Modificeret MIT‑licens – tilladende til kommerciel brug med krediteringskrav for højvolumen‑udrulninger.
- Indbygget multimodal understøttelse – tekst + billede + video via MoonViT‑encoder (~400M parametre).
- Altid‑aktiv tænketilstand – påkrævet for pålidelig agentorienteret ydeevne; kan ikke deaktiveres.
I modsætning til generelle chatmodeller er K2.7 Code tunet til pålidelighed i lange sessioner. Den reducerer “overthinking” (overskydende interne ræsonnementstokens) med cirka 30% sammenlignet med K2.6, hvilket giver lavere omkostninger, hurtigere iterationer og bedre end‑to‑end succesrater i komplekse arbejdsgange.
Dette gør den ideel til:
- Refaktoreringer i repo‑skala.
- Flersproget kodegenerering (Python, Rust, Go, etc.).
- Agentorienteret brug af værktøjer (MCP, CI/CD, filsystem‑operationer).
- Frontend, DevOps, performanceoptimering og ML‑engineering‑opgaver.
Hvad er nyt i Kimi K2.7 Code?
1) Stærkere lang‑horisont‑kodning
Den største opgradering er bedre ydeevne på lang‑horisont kodningsopgaver. Moonshot siger, at K2.7 Code forbedrer end‑to‑end succes på tværs af komplekse software‑engineering‑arbejdsgange, ikke kun one‑shot kodekompletion. Det er den slags opgradering, udviklere mærker, når en model kan holde tråden i et projekt levende over mange omgange i stedet for at drive efter de første par skridt.
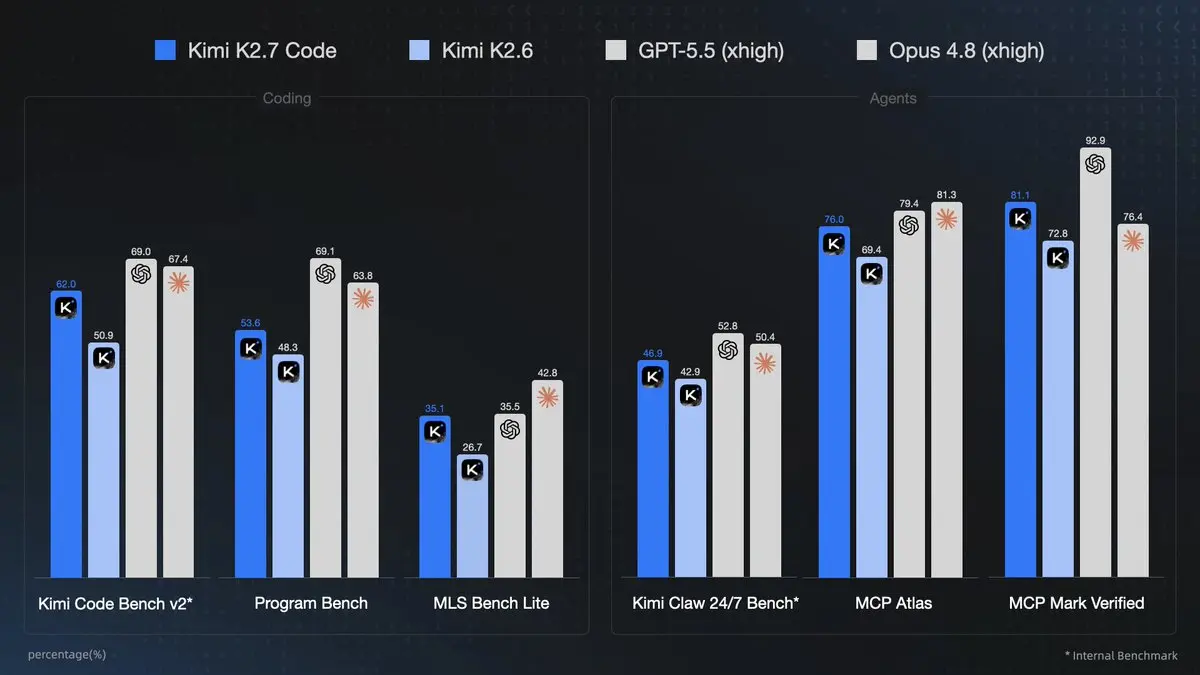
Betydelige benchmark‑gevinster over K2.6:
- +21.8% på Kimi Code Bench v2 (62.0% vs. 50.9%)
- +11.0% på Program Bench (53.6% vs. 48.3%)
- +31.5% på MLS Bench Lite (35.1% vs. 26.7%)
- +9.3% på Kimi Claw 24/7 Bench
- +9.5% på MCP Atlas
- +11.4% på MCP Mark Verified (81.1% vs. 72.8%)
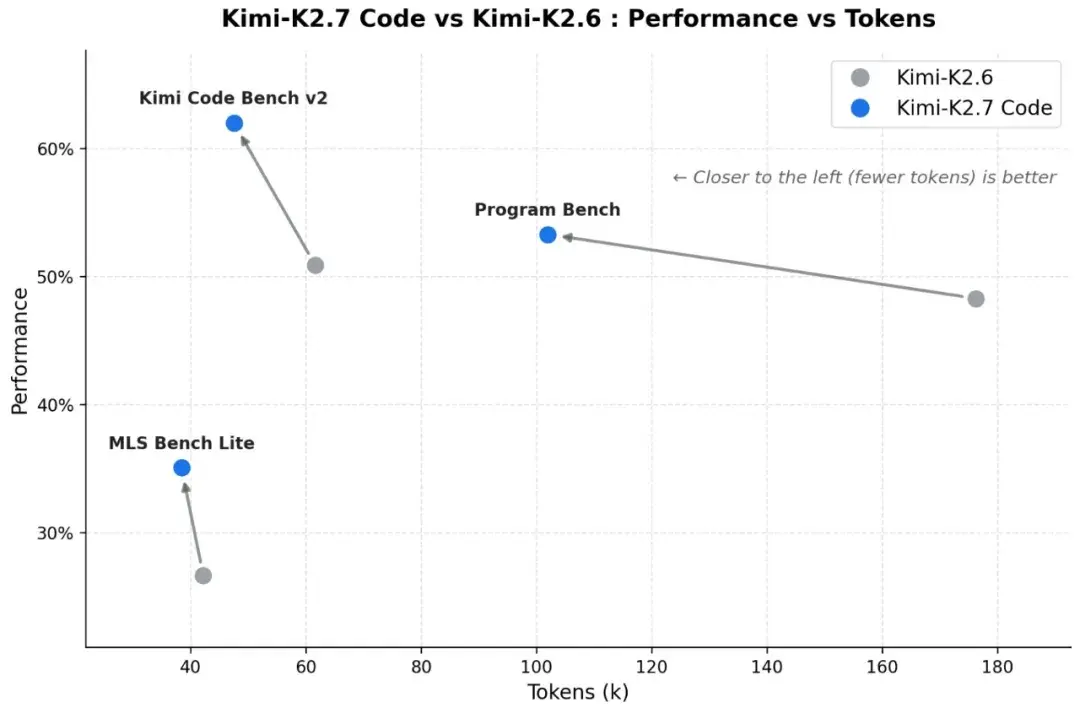
2) Bedre ræsonnementseffektivitet
Moonshot rapporterer, at K2.7 Code bruger ca. 30% færre tænketokens end K2.6. Cloudflares Workers AI‑changelog gentager denne effektivitetsclaim og tilføjer, at lavere brug af ræsonnementstokens kan reducere inferensomkostninger på ræsonnerings‑tunge workloads. Kort sagt: modellen er ikke bare klogere på kodningsopgaver, den er også mere økonomisk, når den tænker.
3) Standard‑tænkeadfærd
Kimi K2.7 Code er kun en tænkemodel. Moonshot siger, at den ikke understøtter ikke‑tænketilstand, og i Kimi Code falder systemet automatisk tilbage til K2.6, hvis tænketilstand deaktiveres. Det er en nyttig detalje for teams, der bygger agentiske kodeværktøjer, for det betyder, at I bør designe med ræsonnering aktiveret som standard.
4) Forbedrede lang‑horisont‑kapabiliteter:
Bedre generalisering på tværs af sprog (Python, Rust, Go osv.) og scenarier (frontend, DevOps, sikkerhed, ML). Højere end‑to‑end opgavesuccesrater.
5) Forbedret multimodalitet og værktøjsbrug
Vision‑encoder (400M parametre) til billeder/videoer; problemfri MCP/ værktøjsintegration til rigtige miljøer (GitHub, Postgres, browsere osv.).
Arkitektur og parametre for Kimi K2.7 Code
Kimi K2.7 Code bruger en Mixture‑of‑Experts‑arkitektur. Ifølge den officielle modelkort på Hugging Face har den 1T samlede parametre og 32B aktiverede parametre. Den omfatter 61 lag, 384 eksperter, 8 valgte eksperter pr. token, 1 delt ekspert, MLA‑attention, SwiGLU‑aktivering, et 160K vokabular og en kontekstlængde på 256K. Vision‑encoderen er MoonViT med 400M parametre.
Den arkitektur forklarer modellens tiltrækningskraft. En trillion‑parameters MoE‑model kan bevare et enormt kapacitetsloft, mens kun en delmængde af parametrene aktiveres pr. token, hvilket er en af grundene til, at MoE‑systemer er attraktive til højkapabilitets‑inferens. K2.7 Code anvender samme native INT4‑kvantisering som K2 Thinking, hvilket hjælper udrulningseffektiviteten.
Kontekstvinduet er et andet stort salgsargument. De officielle docs beskriver et 256K vindue, som er stort nok til lange codebases, lange samtaler og flertrins agentsessioner, hvor kontekstretention er mission‑kritisk.
K2.7 Code deler samme sammenflettede tænkning og flertrins værktøjskald‑design som K2 Thinking og anbefaler Kimi Code CLI som det agentframework, der passer bedst til modellen. Det er et stærkt signal om, at Moonshot ser K2.7 Code som en agentisk arbejdshest, ikke blot en chatgrænseflademodel.
Kerne‑specs (fra det officielle modelkort):
- Samlede parametre: 1T (1 billion)
- Aktiverede parametre pr. token: 32B (omtrent 3% sparsom aktivering for effektivitet)
- Eksperter: 384 i alt (8 valgt pr. token + 1 delt ekspert)
- Lag: 61 (inklusive 1 tæt lag)
- Attention: MLA (Multi‑head Latent Attention)
- Feed‑forward‑aktivering: SwiGLU
- Vokabularstørrelse: ~160K–166K
- Vision‑encoder: MoonViT (~400M parametre) til indbygget multimodalitet (tekst + billede/video)
- Kontekstlængde: 256K tokens (262,144)
- Kvantisering: Indbygget INT4‑understøttelse til effektiv udrulning
- Træning: Muon‑optimering, trænet på massive blandede tekst/visuelle tokens med stabilitetsforbedringer.
Hvorfor MoE betyder noget: Kun ~3% af parametrene aktiveres pr. token og leverer næsten‑frontier kapabilitet til en brøkdel af beregningsomkostningen for tætte modeller af tilsvarende samlet størrelse. Dette muliggør overkommelig selvhosting eller API‑brug til højvolumen kodningsopgaver.
Modellen er stor (~595 GB vægte) og målretter inferens på serverklassen (vLLM, SGLang, KTransformers). Den genbruger udrulningsmønstre fra K2.5/K2.6.
Performance‑benchmarks: Hvor god er den?
Moonshot giver detaljerede førsteparts‑benchmarks, der sammenligner K2.7 Code med K2.6, GPT‑5.5 og Claude Opus 4.8. Mens uafhængig verifikation er i gang (fx noterer nogle praktikere blandede resultater på offentlige kernels), er gevinsterne imponerende for en kodningsspecialist.
Nøgletabel over benchmarks:
| Benchmark | Kimi K2.6 | Kimi K2.7 Code | GPT-5.5 | Claude Opus 4.8 | Gevinst (K2.7 vs K2.6) |
|---|---|---|---|---|---|
| Kimi Code Bench v2 | 50.9 | 62.0 | 69.0 | 67.4 | +21.8% |
| Program Bench | 48.3 | 53.6 | 69.1 | 63.8 | +11.0% |
| MLS Bench Lite | 26.7 | 35.1 | 35.5 | 42.8 | +31.5% |
| Kimi Claw 24/7 Bench | 42.9 | 46.9 | 52.8 | 50.4 | +9.3% |
| MCP Atlas | 69.4 | 76.0 | 79.4 | 81.3 | +9.5% |
| MCP Mark Verified | 72.8 | 81.1 | 92.9 | 76.4 | +11.4% |
Fortolkning:
- K2.7 Code indsnævrer afstanden til frontier‑modeller på kodnings/agentiske opgaver og overgår Opus 4.8 på MCP Mark Verified.
- Stærk i flersproget, virkelighedsnær software‑engineering og værktøjsbrugsscenarier.
- Effektivitetsfordel (30% færre tokens) gør den ofte at foretrække til langkørende agenter, selv om den ikke altid topper rå nøjagtighed. Færre tokens pr. opgave betyder flere iterationer inden for budget/kontekstgrænser.
Forbehold: Mange er in‑house eller specifikke setups. Uafhængige tests (fx KernelBench) viser blandede resultater på visse lavniveauopgaver, men samlet set fremhæver praktikerfeedback praktisk nytte i lange kodningssløjfer.
Effektivitetsgevinster: Omkostnings‑ og hastighedsfordele
En 30% reduktion i tænketokens lyder abstrakt, indtil du sætter det i produktionstermer. Færre ræsonnementstokens betyder ofte lavere latenstid, lavere omkostninger og mindre risiko for, at modellen vandrer gennem unødvendige interne skridt på lange opgaver. Moonshot siger, at K2.7 Code forbedrer effektiviteten, samtidig med at stærkere opgavefærdiggørelse bevares, og Cloudflare fremhæver specifikt, at det er en omkostningsfordel for ræsonnerings‑tunge workloads.
Den kombination er vigtig i kodeagenter, fordi software‑engineering‑opgaver sjældent er “one‑and‑done”. De indebærer at læse en codebase, foretage en ændring, verificere den, håndtere undtagelser og iterere. En model, der er mere token‑effektiv og bedre til lang‑horisont opgavefærdiggørelse, kan være væsentligt bedre for teamproduktivitet end en model, der blot er stærk til korte svar. Det er en slutning baseret på Moonshots benchmark‑ og workflow‑påstande, men den følger direkte af, hvordan modellen positioneres.
Hvad koster Kimi K2.7 Code?
Moonshots Kimi Code‑medlemskab inkluderer K2.7 Code og starter ved $19/month, ifølge den officielle resource‑side. Det er den forbrugerrettede produktvej. For API‑brug afhænger prissætningen af, hvor du tilgår modellen. Sammenlignet med Claude Opus (~$5–25 / M) eller lignende frontier‑priser tilbyder K2.7 Code op til 5–12x bedre værdi for kodningsworkloads. Selvhosting reducerer yderligere omkostningerne ved højvolumenbrug.
På CometAPI er Kimi K2.7 Code opført til $0.76 per million input tokens og $3.19998 per million output tokens, mens den officielle pris vises som $0.95 per million input tokens og $3.999975 per million output tokens, hvilket CometAPI præsenterer som 20% rabat i forhold til officiel prissætning.
Det gør CometAPI interessant for teams, der vil eksperimentere med Kimi K2.7 Code uden at håndtere separate leverandørintegrationer eller betale den højere direkte listepris.
Hvor kan man få adgang til Kimi K2.7 Code
1) Kimi Code
Moonshot siger, at Kimi K2.7 Code nu er standardmodellen i Kimi Code, med tænketilstand aktiveret som standard. Det er den mest native måde at prøve modellen på, hvis du ønsker Moonshots egen kodningsplatform.
2) Kimi API / Kimi Platform
Moonshots åbne platform dokumenterer Kimi K2.7 Code som tilgængelig via Kimi API, og den siger, at platformen bruger OpenAI API‑format. Det gør det lettere at indpasse i eksisterende applikationsarkitekturer, der allerede taler OpenAI‑kompatible API‑mønstre.
3) Hugging Face
Det officielle modelkort på Hugging Face bekræfter open‑weight‑udgivelsen, viser modelsammendrag og benchmarkdata og angiver, at koderepositoriet og modelvægtene er udgivet under en modificeret MIT‑licens. Dette er vejen for udviklere, der vil inspicere vægtene, udrulle selv eller bruge modellen i åbne værktøjsøkosystemer.
4) CometAPI
CometAPI lister nu Kimi K2.7 Code som en integreret model og giver token‑baseret prissætning, en modelside og API‑adgang gennem sin samlede gateway. Den fremhæver også, at platformen er OpenAI‑kompatibel og designet til at reducere leverandørfragmentering ved at placere mange modeller bag ét indgangspunkt. Den understøtter 256K kontekstvinduet, visuelle input, fleromgangs værktøjskald og en OpenAI‑kompatibel sti via /v1/chat/completions. Ingen parameterændringer er påkrævet, hvis du migrerer fra K2.6.
CometAPI‑anbefaling: For de fleste brugere, start her. Én nøgle, pay‑as‑you‑go på tværs af 500+ modeller, automatiske faldback, og lavere effektive priser. Perfekt til at teste K2.7 Code side om side med Claude, GPT eller åbne modeller uden leverandørlåsning. Tilmeld dig på Cometapi.com og byt base‑URL/modelnavn i din OpenAI‑klient.
Tip til selvhosting: Brug INT4‑kvantisering og ekspert‑parallellisme for optimal VRAM/ performance på enterprise‑GPU’er.
Kimi K2.7 Code vs K2.6 vs andre modeller
Hvis din nuværende stack allerede bruger K2.6, er K2.7 Code den oplagte opgradering, når kodekvalitet og ræsonnementseffektivitet betyder mere end blot at bevare samme baseline. Moonshot siger, at arkitekturen er den samme som K2.5/K2.6, udrulning kan genbruges, og benchmark‑performance forbedres mærkbart. Cloudflare siger også, at API‑brugen er identisk, hvilket sænker migrationsfriktionen.
Sammenlignet med bredere frontier‑modeller som GPT‑5.5 og Claude Opus 4.8 er K2.7 Code mere specialiseret. Benchmark‑tabellen viser, at den forbliver konkurrencedygtig i kodnings‑ og agentopgaver, men dens reelle differentiering er kombinationen af open‑source adgang, lang kontekst og kodecentrisk design. Det gør den særligt attraktiv for teams, der værdsætter udrulningsfleksibilitet og omkostningskontrol.
Konklusion: Hvorfor integrere Kimi K2.7 Code via CometAPI i dag
Kimi K2.7 Code repræsenterer et modnende open‑source AI‑kodeøkosystem—kraftfuldt, effektivt, tilgængeligt og agent‑klart. Dens arkitektur, benchmark‑gevinster og tokeneffektivitet gør den til et must‑try for udviklere i 2026.
CometAPI sænker barren yderligere med problemfri integration, konkurrencedygtig prissætning og samlet adgang. Uanset om du selvhoster, bruger den officielle API eller udnytter CometAPIs platform, giver K2.7 Code hurtigere, mere pålidelige kodearbejdsgange.
Klar til at prøve det? Besøg CometAPI, hent din API‑nøgle, og begynd at bygge med Kimi K2.7 Code i dag. Eksperimentér, benchmark mod dine use cases, og skaler med ro i sindet.
Ofte stillede spørgsmål
Er Kimi K2.7 Code open source?
Ja. Moonshot siger, at både koderepositoriet og modelvægtene er udgivet under en modificeret MIT‑licens, og modellen er tilgængelig på Hugging Face.
Hvad er kontekstvinduet?
Moonshots docs angiver et 256K kontekstvindue, og modelkortet og Cloudflare beskriver det som 262,144 eller 262.1K tokens. Det er i praksis samme størrelsesorden.
Understøtter Kimi K2.7 Code ikke‑tænketilstand?
Nej. Moonshot siger, at K2.7 Code kun kører med tænkning aktiveret. I Kimi Code falder deaktivering af tænkning tilbage til K2.6.
Hvad er den største forbedring i forhold til K2.6?
Den største rapporterede forbedring er bedre lang‑horisont kodningsperformance plus omkring 30% færre tænketokens. Moonshot rapporterer også benchmark‑gevinster på +21.8% på Kimi Code Bench v2, +11.0% på Program Bench og +31.5% på MLS Bench Lite.
Kan jeg bruge den via CometAPI?
Ja. CometAPI lister nu Kimi K2.7 Code som en integreret model og viser prissætning pr. token, hvilket gør den til en bekvem adgangsvej for udviklere, der ønsker et samlet API‑lag.
Er den god til AI‑kodeagenter?
Ja. Moonshots dokumentation fremhæver flertrins værktøjskald, sammenflettet tænkning og agentorienterede arbejdsgange, mens Cloudflare fremhæver fleromgangs værktøjskald og strukturerede output.