

In der sich rasant entwickelnden KI-Landschaft sticht GLM-5.2 von Z.ai (Zhipu AI) als ein beeindruckendes Open-Weights-Modell hervor, optimiert für agentenbasiertes Programmieren, Aufgaben mit langem Zeithorizont und Produktionszuverlässigkeit. Mit einem praktisch nutzbaren 1M-Token-Kontextfenster, zwei Reasoning-Modi (High und Max) und starker Leistung zu einem Bruchteil der Kosten geschlossener Spitzenmodelle wird es schnell zur ersten Wahl für Entwickler, die autonome Agenten, IDE-Integrationen und komplexe Software-Engineering-Workflows aufbauen.
Ob Sie als Solo-Entwickler Agenten prototypen, als CTO kosteneffiziente Skalierung evaluieren oder als AI Product Manager multimodales Reasoning in ein SaaS integrieren – die Beherrschung der GLM-5.2-API erschließt erhebliche Vorteile.
Was ist GLM-5.2?
GLM-5.2 ist das neueste Open-Weights-Flaggschiff-Mixture-of-Experts-(MoE)-Modell von Z.ai (Zhipu AI), veröffentlicht Mitte Juni 2026. Mit circa 753 Milliarden Gesamtparametern (rund 40B aktiv pro Token), einem stabilen 1‑Million‑Token‑Kontextfenster, MIT-Lizenzierung und starker Leistung bei Aufgaben mit langem Zeithorizont im Coding und agentischen Szenarien positioniert es sich als wettbewerbsfähige Alternative zu geschlossenen Spitzenmodellen wie GPT-5.5, Claude Opus 4.8 und Gemini-Varianten – bei einem Bruchteil der Kosten für viele Workloads.
GLM-5.2 Architektur und technische Spezifikationen
GLM-5.2 baut auf der GLM-Familie auf und bringt zentrale Upgrades für Langzeithorizont-Arbeit.
- Parameters: ~753B gesamt im MoE-Design (aktive Parameter ~40B pro Token). Liefert enorme Kapazität bei effizienter Inferenz.
- Kontextfenster: 1.048.576 Tokens (1M). Maximaler Output typischerweise bis zu 128K–131K Tokens.
- Präzision: BF16 (mit FP8-Varianten für leichtere Bereitstellung).
- Schlüsselinnovation – IndexShare: Wiederverwendung eines einzelnen Indexers über Gruppen von Sparse-Attention-Schichten, reduziert FLOPs pro Token bei 1M Kontext um bis zu 2.9x. Das macht Langkontext-Inferenz praktikabel, ohne Kosten oder Latenz explodieren zu lassen.
- Reasoning-Modi: „High“ (balanciert) und „Max“ (tiefgehend, empfohlen fürs Coding). Thinking kann für einfache Aufgaben deaktiviert werden.
- Modalitäten: Primär Text/Code (keine native Vision im Basis-Release bestätigt).
- Lizenz: MIT – vollständig offen für Download, Modifikation und kommerzielle Nutzung.
Diese Offenheit und Effizienz machen GLM-5.2 ideal für Teams, die Datensouveränität, Anpassbarkeit oder Kostentransparenz priorisieren.
GLM-5.2 vs GLM-5.1
| Bereich | GLM-5.1 | GLM-5.2 | Praktischer Unterschied |
|---|---|---|---|
| Kontextfenster | Rund 200K auf gängigen gehosteten Routen | 1M | GLM-5.2 eignet sich deutlich besser für Projektkontext |
| Reasoning-Aufwand | Weniger flexibel | High und Max | Bessere Kontrolle über Kosten, Latenz und Qualität |
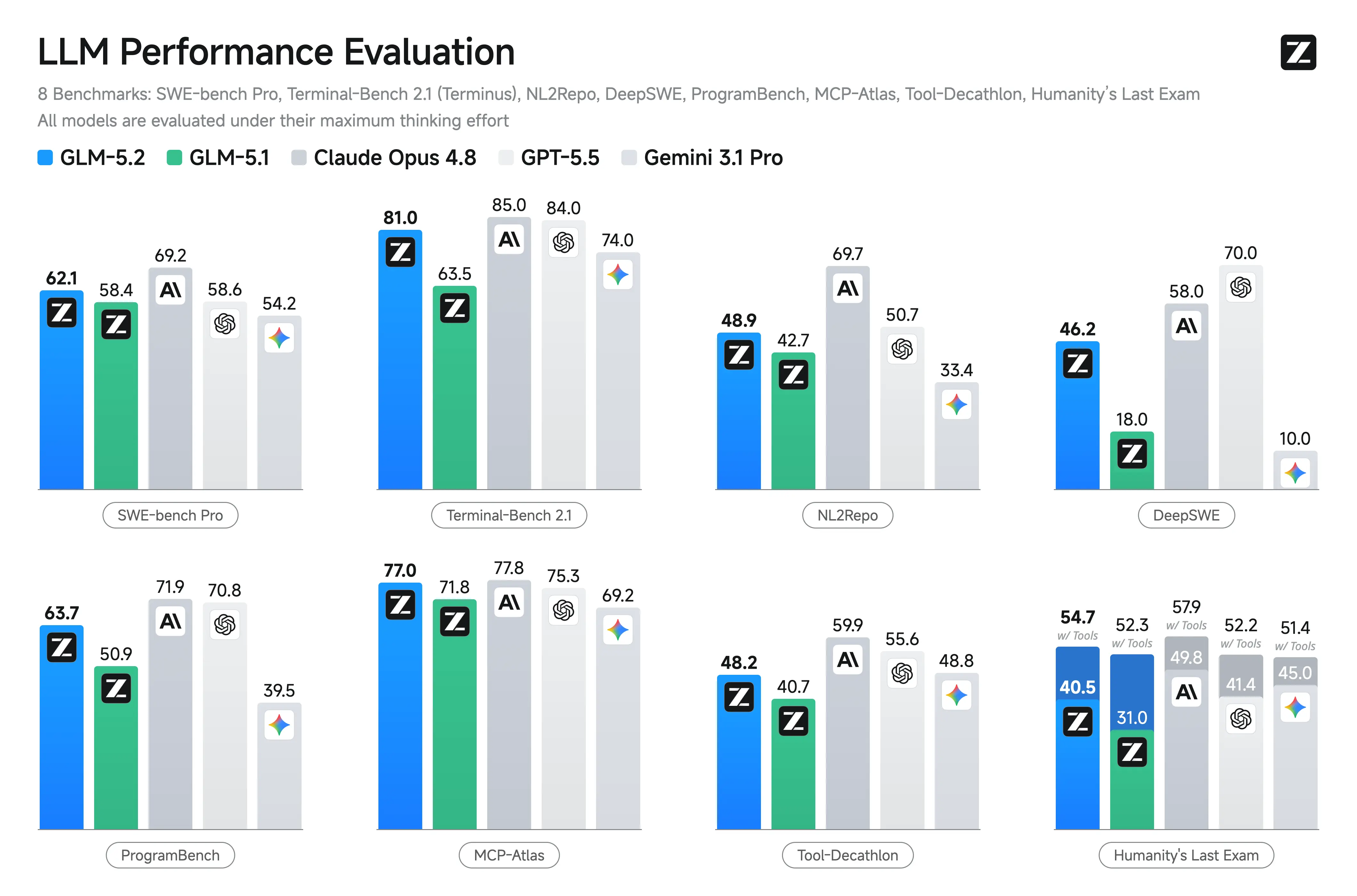
| Terminal Bench 2.1 | 63.5 in der publizierten Tabelle | 81.0 | Großer Sprung bei terminalbasierten Agentenaufgaben |
| SWE-bench Pro | 58.4 | 62.1 | Moderater, aber relevanter Repo‑Level‑Coding‑Gewinn |
| FrontierSWE | 30.5 | 74.4 | Sehr großer Fortschritt bei Langzeithorizont‑Engineering |
| Open-weight Haltung | Open-Weights‑GLM‑Familie | Open-Weights MIT Release | Ähnliche Offenheit, stärkere Langkontext‑Positionierung |
Wenn Ihr GLM‑5.1‑Workflow hauptsächlich aus kurzen Chats oder grundlegender Code-Generierung besteht, ändert das Upgrade nicht alles. Geht es jedoch um große Repositories, mehrschrittige Coding‑Agenten oder lange Task-Ausführung, ist GLM‑5.2 das deutlich relevantere Modell.
GLM-5.2 vs Claude Opus, GPT-5.5, Gemini und DeepSeek
Der klarste Vergleich für GLM‑5.2 erfolgt nach Aufgabentyp:
| Aufgabentyp | Position von GLM-5.2 |
|---|---|
| Long‑horizon Coding | Eines der stärksten Open‑Weights‑Optionen; nahe an geschlossenen Spitzenmodellen auf ausgewählten Benchmarks |
| Allgemeines Reasoning | Stark, aber nicht immer vor den besten geschlossenen Modellen |
| Tool‑Nutzung | Starke MCP‑Atlas‑ und HLE-with-tools‑Leistung |
| Mathematik‑Wettbewerbe | Sehr starke AIME‑2026‑Werte in veröffentlichten Ergebnissen |
| Vision | Nicht das richtige Modell; Vision‑Modell verwenden |
| Günstige, hochvolumige Klassifikation | Meist überdimensioniert; kleineres Modell verwenden |
| Self‑Hosting und Anpassung | Stärkere Option als rein API‑basierte geschlossene Modelle |
Für Teams ist die beste Antwort meist nicht „GLM‑5.2 ersetzt jedes Modell“. Die bessere Antwort lautet: „GLM‑5.2 auf die Aufgaben routen, bei denen es im Vorteil ist.“ Das ist ein Grund, warum ein einheitlicher API‑Anbieter wie CometAPI praktisch sein kann. Er ermöglicht es, Modelle arbeitslastbasiert zu vergleichen und zu routen, ohne jede Integration neu aufzubauen.
Preise: Leistungsstark und skalierbar bezahlbar
GLM‑5.2 bietet überzeugende Ökonomie, insbesondere für tokenintensive Langkontext‑Arbeit.
- API‑Preise (über Z.ai/OpenRouter/etc.): $1.40 / 1M Input‑Tokens, $4.40 / 1M Output‑Tokens. Cache‑Read ab $0.26/1M in einigen Routen.
- GLM Coding Plan‑Abonnements (inkl. Vollzugriff, kein Aufpreis für 5.2):
- Lite: ~$10–12.60/Monat (leichte Iteration).
- Pro: ~$30/Monat.
- Max/Team: Höhere Kontingente für starke Nutzung.
Kosteneinsparungsbeispiel: Für eine lange agentische Session mit 500K Kontext + Outputs kann GLM‑5.2 4–5x günstiger sein als Claude‑Äquivalente – und größere Kontexte nativ verarbeiten.
CometAPI‑Empfehlung: Greifen Sie über CometAPIs einheitlichen OpenAI‑kompatiblen Endpunkt zu wettbewerbsfähigen Konditionen auf GLM‑5.2 (und 500+ weitere Modelle) zu. Ein Schlüssel, kein Vendor‑Lock‑in, Testguthaben bei Registrierung. Ideal, um GLM‑5.2 produktiv Seite an Seite mit Claude/GPT zu vergleichen.
1M-Kontextfenster: Das herausragende Merkmal
Der 1M‑Kontext ist in der Praxis „solide“ und verlustfrei für Arbeit im Projektmaßstab – weit über Marketing hinaus. Er ermöglicht, ganze mittelgroße bis große Repositories im Kontext zu halten, was Summarisierungs‑Overhead und Fehlerakkumulation bei Agenten reduziert.
Tipps für den effektiven Einsatz:
- Verwenden Sie den Bezeichner glm-5.2[1m].
- Setzen Sie die maximale Tokenzahl passend; Produktionsbetrieb überwachen.
- Mit Tools/MCP kombinieren, um Daten dynamisch zu holen.
Frühe Tests bestätigen Stabilität jenseits von 200K, einem häufigen Ausfallpunkt anderer „Langkontext“-Modelle.
Basisleistung und Benchmarks
Z.ai und unabhängige Berichte heben die Stärken von GLM‑5.2 in Coding‑ und agentischen Szenarien hervor. Es zeigt deutliche Zuwächse gegenüber GLM‑5.1 und wettbewerbsfähige Ergebnisse gegenüber geschlossenen Modellen bei Aufgaben mit langem Zeithorizont.
Wesentliche gemeldete Benchmarks (Z.ai und Third‑Party‑Aggregationen):
- Terminal‑Bench 2.1: 81.0 (gegenüber 62.0 bei GLM‑5.1) – Exzellent für Terminal-/Agenten‑Operationen.
- SWE‑bench Pro: 62.1 (leicht vor GPT‑5.5 mit 58.6).
- MCP‑Atlas: 77.0 (nahe Claude Opus 4.8).
- Humanity’s Last Exam (mit Tools): 54.7.
Weitere Spitzen: Top oder nahe Top unter Open‑Modellen auf FrontierSWE, PostTrainBench, SWE‑Marathon. Stark auf AIME 2026 (~99.2) und GPQA‑Diamond (91.2).
GLM-5.2 API-Zugriffsoptionen
Es gibt zwei gängige Wege, GLM‑5.2 aus einer Anwendung heraus zu nutzen.
Option 1: Z.ai direkt verwenden
Der direkte Weg ist die offizielle Z.ai‑API. Das kann passend sein, wenn Ihr Team eine direkte Beziehung zum Modellanbieter wünscht, ausschließlich Z.ai‑Modelle nutzt oder anbieter‑spezifische Steuerungen sofort beim Erscheinen benötigt.
Der Trade‑off ist operativ. Wenn Ihr Produkt mehrere Modellfamilien nutzt, müssen Sie ggf. separate SDK‑Konfigurationen, Abrechnungsflüsse, Failover‑Logik, Preisnormalisierung und Observability‑Konventionen pflegen. Für ein Forschungsprojekt mag das akzeptabel sein. Für eine produktive SaaS‑Plattform kann die Integrationsfläche schnell wachsen.
Option 2: GLM-5.2 über CometAPI verwenden
CometAPI bietet Zugriff auf GLM‑5.2 über ein einheitliches API‑Gateway. Der praktische Vorteil: Entwickler können verschiedene KI‑Modelle über eine OpenAI‑kompatible Schnittstelle aufrufen, statt pro Anbieter eine eigene Integration zu bauen. Sie halten Ihren Code näher am OpenAI‑SDK‑Muster, setzen den Modellnamen auf glm-5.2 und routen Anfragen über CometAPI.
Das ist nützlich für Startups und Produktteams, die:
- GLM‑5.2 gegen andere Modelle testen wollen, ohne ihr Backend neu zu bauen
- Einen einzigen API‑Schlüssel und eine Abrechnung für mehrere Modelle behalten möchten
- Schneller von Benchmark zu Prototyp und Produktion gehen wollen
- Modell‑Fallback oder Routingstrategien implementieren
- Kosten und Qualität anbieterübergreifend vergleichen
- Vertraute OpenAI‑Request‑Muster nutzen möchten
Melden Sie sich auf CometAPI.com an für sofortige Testguthaben und OpenAI‑kompatible Endpunkte, die Anbieter‑Eigenheiten abstrahieren.
- API‑Schlüssel erhalten.
- Umgebungsvariablen setzen (Security Best Practice):
export GLM_API_KEY="your_key_here"
export BASE_URL="https://api.cometapi.com/v1" # or direct Z.ai endpoint
Ihren ersten GLM-5.2 API-Call ausführen
cURL-Beispiel (Schnelltest):
bash
curl https://api.z.ai/api/paas/v4/chat/completions \
-H "Authorization: Bearer $GLM_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5.2",
"messages": [
{"role": "system", "content": "You are an expert full-stack engineer."},
{"role": "user", "content": "Write a FastAPI endpoint for user authentication with JWT."}
],
"temperature": 0.7,
"max_tokens": 2048
}'
Häufige GLM-5.2-Anwendungsfälle
GLM‑5.2 ist eine starke Option für Workflows, in denen langer Kontext, Reasoning und Tool‑Nutzung zusammenkommen.
| Anwendungsfall | Beispielimplementierung | Warum GLM-5.2 passen kann |
|---|---|---|
| Developer‑Assistant | Bugreports, Code‑Snippets, Logs und Tests analysieren | Erfordert Reasoning über technischen Kontext |
| Dokumentenintelligenz | Verträge, Richtlinien, Schadensfälle oder Reports prüfen | Lange Eingaben und strukturierte Extraktion |
| Research‑Agent | Quellen lesen, Aussagen vergleichen, Zusammenfassungen erstellen | Profitiert von langem Kontext und Zitierdisziplin |
| Customer‑Support‑Copilot | Ticket‑Historie, Doku, Kontodaten und Policy kombinieren | Benötigt Retrieval plus Tool‑Aufrufe |
| AI Product Manager‑Assistent | Feedback, Spezifikationen, Nutzungsdaten und Roadmap‑Notizen synthetisieren | Langer Kontext und Business‑Reasoning |
| Sicherheitsanalyse | Incident‑Berichte, Alarme und Remediation‑Pläne prüfen | Benötigt sorgfältiges mehrstufiges Reasoning |
| Sales Engineering | Technische Antworten aus Doku und Kundenanforderungen generieren | Nützlich für komplexe B2B‑Sales‑Zyklen |
Das gemeinsame Muster ist nicht „Chatbot“. Das gemeinsame Muster ist die Workflow‑Kompression. GLM‑5.2 kann die Zeitspanne zwischen Rohinformationen und einer nutzbaren Entscheidung verkürzen.
Wer sollte GLM-5.2 nutzen?
GLM‑5.2 passt besonders für:
- Entwickler, die AI‑Coding‑Tools bauen.
- SaaS‑Unternehmen mit repository‑bewussten Assistenten.
- CTOs, die Open‑Weights‑Alternativen zu geschlossenen Coding‑Modellen evaluieren.
- AI Product Manager, die Langkontext‑Workflows testen.
- Unternehmen mit künftigen Self‑Hosting‑ oder Datenkontroll‑Bedarfen.
- Entwicklerplattformen, die Modell‑Optionalität benötigen.
- Teams, die mit großen technischen Dokumenten, SDKs oder Codebasen arbeiten.
Besonders attraktiv ist es, wenn ein Fehlschlag teuer ist. Wenn ein Modellfehler zu kaputten Builds, fehlerhaften Migrationen oder vergeudeter Engineering‑Zeit führt, rechnet sich der Einsatz eines stärkeren Modells schnell.
Wann GLM-5.2 nicht verwenden
Setzen Sie GLM‑5.2 nicht standardmäßig ein für:
- Kurze und repetitive Klassifikationsaufgaben.
- Einfache Text‑Umschreibungen.
- Bild‑ oder Screenshot‑Verstehen.
- Low‑Latency‑Autocomplete, bei dem Millisekunden zählen.
- Workflows, in denen ein kleineres Modell bereits gut funktioniert.
- Produkte, die langlaufende Generierung nicht tolerieren.
Ziel ist nicht, das größte Kontextfenster zu verehren. Ziel ist es, die Aufgabe mit dem richtigen Profil aus Qualität, Kosten und Latenz zu lösen.
Fazit
GLM‑5.2 ist eine der wichtigsten Open‑Weights‑KI‑Veröffentlichungen für Software‑Engineering‑Teams im Jahr 2026. Die Kombination aus 1M‑Kontext, starken Coding‑Benchmarks, High‑ und Max‑Reasoning‑Modi, Function‑Calling‑Support und MIT‑Lizenz macht es zu einer ernstzunehmenden Option für Coding‑Agenten und Langhorizont‑KI‑Workflows.
Für Teams, die schnell starten möchten, ist CometAPI eine pragmatische Zugriffsschicht. Sie können GLM‑5.2 über einen OpenAI‑kompatiblen Endpunkt aufrufen, es mit anderen führenden Modellen vergleichen, Nutzung monitoren und eine Routing‑Strategie aufbauen, ohne Ihren Stack auf einen Anbieter zuzuschneiden. Beginnen Sie mit einer kleinen, privaten Evaluation, messen Sie die Kosten pro gelöster Aufgabe und bringen Sie GLM‑5.2 nur dort in Produktion, wo seine Langkontext‑Stärken sich klar auszahlen.
Bereit, GLM‑5.2 in Ihrer eigenen App zu testen? Erkunden Sie GLM-5.2 auf CometAPI, erstellen Sie einen API‑Schlüssel und führen Sie in Minuten Ihre erste OpenAI‑kompatible Anfrage aus. Setzen Sie es für eine echte Repository‑Aufgabe ein, nicht für einen Spielzeug‑Prompt, und vergleichen Sie das Ergebnis mit Ihrem aktuellen Modell‑Stack.