

Dans le paysage de l’IA en rapide évolution, GLM-5.2 de Z.ai (Zhipu AI) se distingue comme un modèle à poids ouverts redoutable, optimisé pour la programmation agentique, les tâches à long horizon et la fiabilité en production. Avec une fenêtre de contexte exploitable de 1M tokens, deux modes de raisonnement (High et Max) et de fortes performances pour une fraction du coût des modèles propriétaires de pointe, il devient rapidement un choix privilégié pour les développeurs qui construisent des agents autonomes, des intégrations IDE et des workflows d’ingénierie logicielle complexes.
Que vous soyez un développeur solo qui prototype des agents, un CTO évaluant une montée en charge rentable, ou un chef de produit IA intégrant un raisonnement compatible multimodal dans un SaaS, maîtriser l’API GLM-5.2 débloque des avantages significatifs.
Qu’est-ce que GLM-5.2 ?
GLM-5.2 est le dernier modèle phare à poids ouverts Mixture-of-Experts (MoE) de Z.ai (Zhipu AI), publié mi-juin 2026. Avec environ 753 milliards de paramètres totaux (environ 40B actifs par token), une fenêtre de contexte stable de 1 million de tokens, une licence MIT, et de fortes performances sur le codage à long horizon et les tâches agentiques, il se positionne comme une alternative compétitive aux modèles propriétaires de pointe tels que GPT-5.5, Claude Opus 4.8 et les variantes Gemini — pour une fraction du coût sur de nombreuses charges de travail.
Architecture et spécifications techniques de GLM-5.2
GLM-5.2 s’appuie sur la famille GLM avec des améliorations clés pour le travail à long horizon.
- Paramètres : ~753B au total dans une conception MoE (paramètres actifs ~40B par token). Cela offre une capacité massive avec une inférence efficiente.
- Fenêtre de contexte : 1 048 576 tokens (1M). Sortie maximale généralement jusqu’à 128K–131K tokens.
- Précision : BF16 (avec variantes FP8 pour un déploiement plus léger).
- Innovation clé – IndexShare : réutilise un unique indexeur à travers des groupes de couches d’attention clairsemée, réduisant les FLOPs par token jusqu’à 2,9x à 1M de contexte. Cela rend l’inférence long contexte viable sans explosion des coûts ni de la latence.
- Modes de raisonnement : « High » (équilibré) et « Max » (le plus poussé, recommandé pour le codage). La réflexion peut être désactivée pour les tâches simples.
- Modalités : principalement texte/code (pas de vision native confirmée dans la version de base).
- Licence : MIT – entièrement ouvert au téléchargement, à la modification et à l’usage commercial.
Cette ouverture et cette efficacité font de GLM-5.2 un choix idéal pour les équipes qui privilégient la confidentialité des données, la personnalisation ou le contrôle des coûts.
GLM-5.2 vs GLM-5.1
| Domaine | GLM-5.1 | GLM-5.2 | Différence pratique |
|---|---|---|---|
| Fenêtre de contexte | Environ 200K sur les routes courantes | 1M | GLM-5.2 convient bien mieux au contexte de projet complet |
| Effort de raisonnement | Moins flexible | High et Max | Meilleur contrôle des coûts, de la latence et de la qualité |
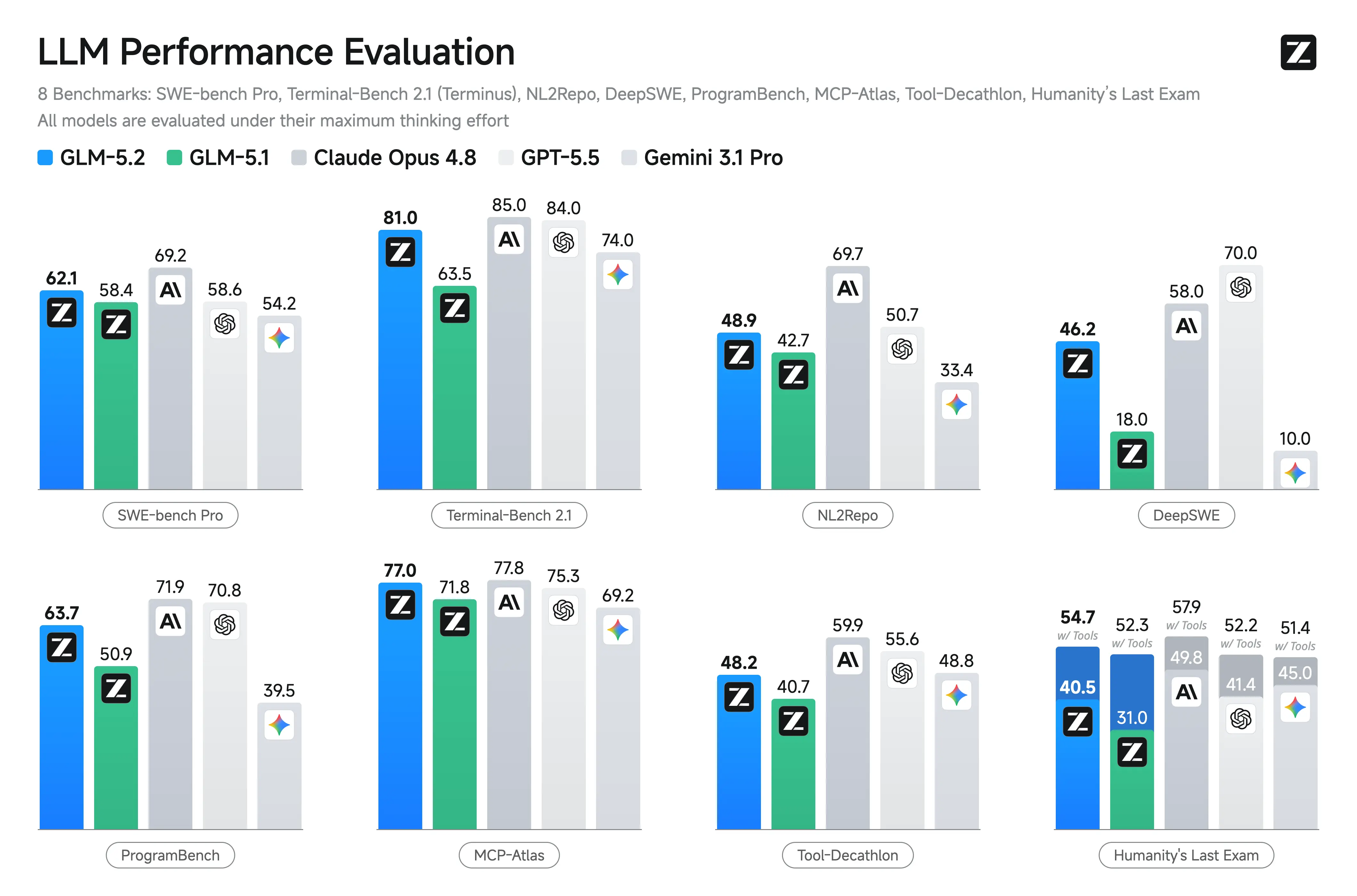
| Terminal Bench 2.1 | 63.5 dans le tableau publié | 81.0 | Amélioration majeure pour les tâches d’agent basées sur le terminal |
| SWE-bench Pro | 58.4 | 62.1 | Gain de codage modéré mais significatif au niveau dépôt |
| FrontierSWE | 30.5 | 74.4 | Très forte amélioration pour l’ingénierie à long horizon |
| Posture à poids ouverts | Famille GLM à poids ouverts | Publication à poids ouverts sous licence MIT | Ouverture similaire, positionnement long contexte renforcé |
Si votre workflow GLM-5.1 actuel se limite surtout au chat court ou à la génération de code basique, la mise à niveau ne changera pas tout. Si votre workflow implique de grands dépôts, des agents de codage multi-étapes ou une exécution de tâches longues, GLM-5.2 est un modèle bien plus pertinent.
GLM-5.2 vs Claude Opus, GPT-5.5, Gemini et DeepSeek
La manière la plus claire de comparer GLM-5.2 est par type de tâche :
| Type de tâche | Position de GLM-5.2 |
|---|---|
| Codage à long horizon | L’une des meilleures options à poids ouverts ; proche des modèles propriétaires de pointe sur certains benchmarks |
| Raisonnement général | Solide, mais pas toujours devant les meilleurs modèles fermés |
| Utilisation d’outils | Solide performance sur MCP-Atlas et HLE-with-tools |
| Compétitions de maths | Très forte note AIME 2026 dans les résultats publiés |
| Vision | Pas le bon modèle ; utilisez un modèle de vision |
| Classification bas coût/haut volume | Généralement surdimensionné ; utilisez un modèle plus petit |
| Auto‑hébergement et personnalisation | Option plus solide que les modèles fermés uniquement via API |
Pour les équipes, la meilleure réponse n’est généralement pas « remplacer tous les modèles par GLM-5.2 ». La meilleure réponse est « router GLM-5.2 vers les tâches où il a un avantage ». C’est l’une des raisons pour lesquelles un fournisseur d’API unifiée tel que CometAPI peut être pratique. Il vous permet de comparer et router les modèles par charge de travail sans reconstruire chaque intégration.
Tarification : puissance abordable à l’échelle
GLM-5.2 offre une économie convaincante, surtout pour le travail long contexte gourmand en tokens.
- Tarification API (via Z.ai/OpenRouter/etc.) : 1,40 $ / 1M tokens d’entrée, 4,40 $ / 1M tokens de sortie. Lecture du cache à partir de 0,26 $/1M sur certaines routes.
- Abonnements GLM Coding Plan (incluent l’accès complet, sans surcoût pour 5.2) :
- Lite : ~10–12,60 $/mois (itération légère).
- Pro : ~30 $/mois.
- Max/Team : quotas plus élevés pour un usage intensif.
Exemple d’économies : pour une longue session agentique avec 500K de contexte + sorties, GLM-5.2 peut être 4–5x moins cher que les équivalents Claude tout en gérant nativement de plus grands contextes.
Recommandation CometAPI : accédez à GLM-5.2 (et 500+ autres modèles) via l’endpoint unifié compatible OpenAI de CometAPI à des tarifs compétitifs. Une seule clé, pas de verrouillage fournisseur, crédits de test à l’inscription. Idéal pour comparer GLM-5.2 avec Claude/GPT en production. Visitez cometapi pour une intégration fluide.
Fenêtre de contexte 1M : la fonctionnalité phare
Le contexte 1M est « solide » et sans perte en pratique pour un travail à l’échelle d’un projet — bien au-delà du battage marketing. Il permet de conserver des dépôts de taille moyenne à grande en contexte, réduisant les coûts de synthèse et l’accumulation d’erreurs dans les agents.
Conseils d’utilisation efficace :
- Utilisez l’identifiant glm-5.2[1m].
- Définissez correctement le nombre maximal de tokens ; surveillez en production.
- Combinez avec des outils/MCP pour la récupération dynamique de données.
Les premiers tests confirment une stabilité au-delà de 200K, un point d’échec fréquent pour d’autres modèles « long contexte ».
Performances de base et benchmarks
Z.ai et des rapports indépendants mettent en avant les forces de GLM-5.2 dans les scénarios de codage et agentiques. Il montre des gains substantiels par rapport à GLM-5.1 et des résultats compétitifs face aux modèles fermés sur les tâches à long horizon.
Principaux benchmarks rapportés (Z.ai et agrégats tiers) :
- Terminal-Bench 2.1 : 81.0 (contre 62.0 pour GLM-5.1) – Excellent pour les opérations terminal/agent.
- SWE-bench Pro : 62.1 (devance GPT-5.5 à 58.6).
- MCP-Atlas : 77.0 (proche de Claude Opus 4.8).
- Humanity’s Last Exam (avec outils) : 54.7.
Autres points forts : en tête ou proche du sommet parmi les modèles ouverts sur FrontierSWE, PostTrainBench, SWE-Marathon. Fort sur AIME 2026 (~99.2) et GPQA-Diamond (91.2).
Options d’accès API à GLM-5.2
Il existe deux façons courantes d’accéder à GLM-5.2 depuis une application.
Option 1 : utiliser Z.ai directement
La voie directe consiste à utiliser l’API officielle de Z.ai. C’est le bon choix lorsque votre équipe souhaite une relation directe avec le fournisseur du modèle, n’utilise que les modèles Z.ai, ou a besoin de contrôles spécifiques au fournisseur dès leur sortie.
Le compromis est opérationnel. Si votre produit utilise plusieurs familles de modèles, vous devrez peut-être maintenir des configurations SDK séparées, des flux de facturation, une logique de bascule, une normalisation des prix et des conventions d’observabilité. Pour un projet de recherche, cela peut être acceptable. Pour une plateforme SaaS en production, la surface d’intégration peut croître rapidement.
Option 2 : utiliser GLM-5.2 via CometAPI
CometAPI donne accès à GLM-5.2 via une passerelle d’API unifiée. L’avantage pratique est que les développeurs peuvent appeler différents modèles d’IA via une seule interface compatible OpenAI au lieu de construire une intégration par fournisseur. Vous gardez votre code proche du pattern SDK OpenAI, définissez le nom du modèle sur glm-5.2, et routez les requêtes via CometAPI.
C’est utile pour les startups et équipes produit qui veulent :
- Tester GLM-5.2 face à d’autres modèles sans reconstruire leur backend
- Conserver une seule clé API et une seule couche de facturation pour plusieurs modèles
- Accélérer le passage du benchmark au prototype puis à la production
- Mettre en place des stratégies de repli ou de routage de modèles
- Comparer coût et qualité entre fournisseurs
- Utiliser des patterns de requêtes familiers à la OpenAI
Inscrivez-vous sur CometAPI.com pour des crédits de test instantanés et des endpoints compatibles OpenAI qui masquent les spécificités des fournisseurs.
- Obtenez votre clé API.
- Définissez des variables d’environnement (bonne pratique de sécurité) :
export GLM_API_KEY="your_key_here"
export BASE_URL="https://api.cometapi.com/v1" # or direct Z.ai endpoint
Réaliser votre premier appel API GLM-5.2
Exemple cURL (test rapide) :
bash
curl https://api.z.ai/api/paas/v4/chat/completions \
-H "Authorization: Bearer $GLM_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5.2",
"messages": [
{"role": "system", "content": "You are an expert full-stack engineer."},
{"role": "user", "content": "Write a FastAPI endpoint for user authentication with JWT."}
],
"temperature": 0.7,
"max_tokens": 2048
}'
Cas d’usage courants de GLM-5.2
GLM-5.2 est un solide candidat pour les workflows où long contexte, raisonnement et utilisation d’outils se combinent.
| Cas d’usage | Exemple d’implémentation | Pourquoi GLM-5.2 peut convenir |
|---|---|---|
| Assistant développeur | Analyser des rapports de bugs, extraits de code, logs et tests | Nécessite un raisonnement sur un contexte technique |
| Intelligence documentaire | Examiner des contrats, politiques, déclarations ou rapports | Entrées longues et extraction structurée |
| Agent de recherche | Lire des sources, comparer des affirmations, produire des synthèses | Bénéficie d’un long contexte et d’une discipline de citation |
| Copilote support client | Combiner historique de tickets, docs, données de compte et politiques | Besoin de récupération + appel d’outils |
| Assistant chef de produit IA | Synthétiser retours, specs, données d’usage et notes de roadmap | Long contexte et raisonnement métier |
| Analyse de sécurité | Passer en revue rapports d’incidents, alertes et plans de remédiation | Nécessite un raisonnement multi‑étapes rigoureux |
| Ingénierie commerciale | Générer des réponses techniques à partir de docs et besoins clients | Utile pour des cycles de vente B2B complexes |
Le schéma commun n’est pas « chatbot ». Le schéma commun est la compression des workflows. GLM-5.2 peut réduire le temps entre l’information brute et une décision utile.
Qui devrait utiliser GLM-5.2 ?
GLM-5.2 convient particulièrement à :
- Développeurs construisant des outils de codage IA.
- Entreprises SaaS ajoutant des assistants conscients des dépôts.
- CTOs évaluant des alternatives à poids ouverts aux modèles de codage fermés.
- Chefs de produit IA testant des workflows long contexte.
- Entreprises prévoyant l’auto‑hébergement ou un contrôle accru des données.
- Plateformes développeurs ayant besoin d’optionnalité de modèles.
- Équipes travaillant avec de grands documents techniques, SDKs ou bases de code.
Il est particulièrement attrayant lorsque l’échec de la tâche coûte cher. Si une erreur de modèle provoque des builds cassés, de mauvaises migrations ou du temps d’ingénierie gaspillé, le coût d’un modèle plus performant se justifie rapidement.
Quand ne pas utiliser GLM-5.2
N’utilisez pas GLM-5.2 par défaut pour :
- Des tâches de classification courtes et répétitives.
- De simples réécritures de texte.
- La compréhension d’images ou de captures d’écran.
- L’autocomplétion à très faible latence où la milliseconde compte.
- Des workflows où un plus petit modèle fonctionne déjà bien.
- Des produits qui ne peuvent tolérer des générations longues.
L’objectif n’est pas de vénérer la plus grande fenêtre de contexte. L’objectif est de résoudre la tâche avec le bon profil qualité, coût et latence.
Verdict final
GLM-5.2 est l’une des sorties de modèles à poids ouverts les plus importantes pour les équipes d’ingénierie logicielle en 2026. La combinaison d’un contexte 1M, de solides benchmarks en codage, des modes de raisonnement High et Max, du support d’appel de fonctions et de la licence MIT en fait une option sérieuse pour les agents de codage et les workflows IA à long horizon.
Pour les équipes qui veulent l’essayer rapidement, CometAPI est une couche d’accès pragmatique. Vous pouvez appeler GLM-5.2 via un endpoint compatible OpenAI, le comparer à d’autres modèles de pointe, suivre l’usage et bâtir une stratégie de routage sans reconstruire votre pile autour d’un seul fournisseur. Commencez par une petite évaluation privée, mesurez le coût par tâche résolue et déployez GLM-5.2 en production uniquement là où ses forces long contexte se rentabilisent clairement.
Prêt à tester GLM-5.2 dans votre propre application ? Découvrez GLM-5.2 sur CometAPI, créez une clé API et exécutez votre première requête compatible OpenAI en quelques minutes. Utilisez‑le pour une tâche réelle sur un dépôt, pas une invite jouet, et comparez le résultat à votre pile de modèles actuelle.