

Google a lancé Gemini 3.5 Flash le 19 mai 2026, lors d'I/O, le positionnant comme un modèle à haute intelligence optimisé pour la vitesse, visant des performances de pointe soutenues dans les workflows agentiques, le codage et les tâches multimodales. Il s’appuie sur la base de Gemini 3 Flash avec des « niveaux de réflexion » améliorés pour équilibrer qualité, coût et latence.
Ce guide complet couvre tout : ce qu’est Gemini 3.5 Flash, ses fonctionnalités clés, des performances de benchmarks détaillées, la tarification, des comparaisons avec GPT-5.5, Claude 4.7/4.6, et plus encore. En tant qu’agrégateur d’API d’IA de premier plan, CometAPI aide les développeurs à accéder à Gemini 3.5 Flash (et à ses concurrents) avec une tarification unifiée, une intégration simplifiée et des outils d’optimisation des coûts.
Qu’est-ce que Gemini 3.5 Flash ?
Gemini 3.5 Flash s’appuie sur la fondation de raisonnement de Gemini 3 Flash avec des « niveaux de réflexion » améliorés (minimal, low, medium/default, high) pour affiner le compromis qualité-latence-coût. C’est un modèle nativement multimodal prenant en charge le texte, les images, la vidéo, l’audio et les documents (y compris les PDF), avec une fenêtre de contexte de 1M de jetons et jusqu’à 65K jetons de sortie. La date limite des connaissances est janvier 2025.
Différenciateurs clés par rapport aux modèles Flash précédents :
- Performances de pointe soutenues sur les tâches agentiques, le codage et les tâches à long terme.
- Préservation de la réflexion : conserve automatiquement le raisonnement intermédiaire sur des conversations multi-tours sans modification supplémentaire de l’API.
- Optimisé pour l’échelle : conçu pour l’exécution agentique parallèle, le codage itératif et les workflows d’entreprise multi-étapes.
- Pas encore d’« utilisation de l’ordinateur », mais fortes améliorations de l’utilisation d’outils et des appels de fonctions.
Google le présente comme le « modèle Flash le plus intelligent » pour la production, surpassant l’ancien Gemini 3.1 Pro sur de nombreux benchmarks agentiques et de codage tout en offrant une vitesse de niveau Flash (souvent >280 jetons de sortie/seconde lors des tests).
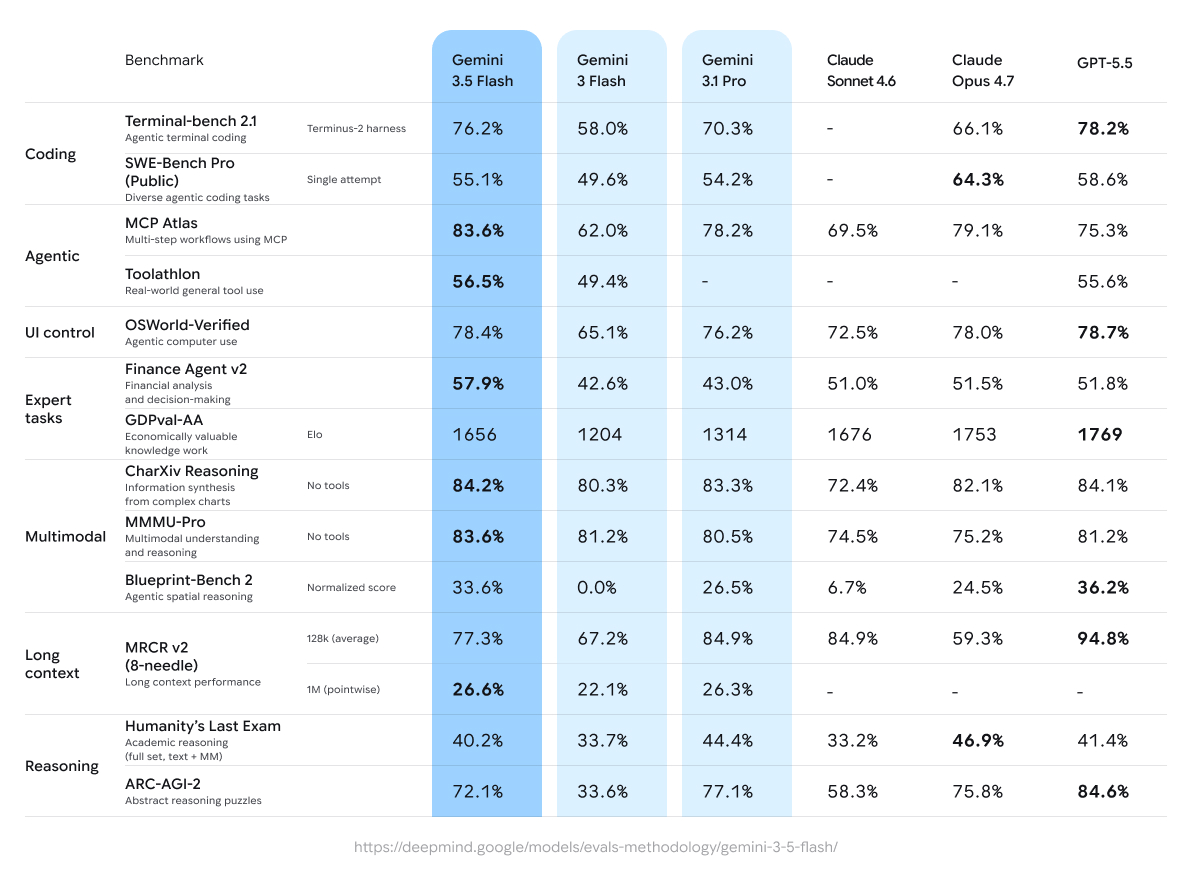
Gemini 3.5 Flash excelle dans les workflows agentiques et le codage avec une intelligence proche de Pro à une latence et un coût optimisés, atteignant des scores comme 76.2% sur Terminal-bench 2.1 et 83.6% sur les tâches multi-étapes MCP Atlas.
Percée en performances de benchmark
Des tests indépendants confirment qu’il délivre des performances de niveau Pro, voire meilleures, sur les tâches de codage/agentiques à une vitesse plus élevée, bien que le coût total d’exécution des benchmarks augmente en raison d’un plus grand nombre de jetons utilisés dans des boucles agentiques complexes et de l’augmentation de prix 3x par rapport aux anciens modèles Flash.
Gemini 3.5 Flash montre de solides gains par rapport à ses prédécesseurs, en particulier dans les domaines agentiques et de codage. Voici des résultats clés issus de la fiche du modèle Google DeepMind et d’évaluations indépendantes (à mai 2026) :
Benchmarks sélectionnés (Gemini 3.5 Flash vs comparateurs) :
Codage :
- Terminal-bench 2.1 (codage agentique en terminal) : 76.2% (vs Gemini 3 Flash 58.0%, Gemini 3.1 Pro 70.3%, GPT-5.5 78.2%)
- SWE-Bench Pro (codage agentique public et diversifié) : 55.1% (vs 49.6% pour 3 Flash, 54.2% pour 3.1 Pro)
Utilisation d’outils agentiques :
- MCP Atlas (workflows multi-étapes) : 83.6% (avance marquée)
- Toolathlon (utilisation d’outils en conditions réelles) : 56.5%
- Finance Agent v2 : 57.9% (+15.3% vs 3 Flash)
Multimodal :
- CharXiv (raisonnement sur graphiques) : 84.2%
- MMMU-Pro : 83.6% (devance de nombreux concurrents)
Raisonnement et long contexte :
- Humanity’s Last Exam : 40.2%
- ARC-AGI-2 : 72.1%
- MRCR v2 (128k) : 77.3% ; contexte 1M solide à 26.6% ponctuel.
Artificial Analysis Intelligence Index : Gemini 3.5 Flash obtient 55 (pensée élevée), +9 points par rapport à Gemini 3 Flash. Il mène la frontière de Pareto Intelligence vs Speed, avec des gains sur les tâches agentiques et des hallucinations réduites (jusqu’à 61% de taux d’hallucinations). Il dépasse 280 jetons de sortie/seconde mais entraîne une utilisation plus élevée de jetons dans les boucles agentiques.
Il brille dans le long contexte (fort sur MRCR v2 et en point à 1M), un leadership multimodal (graphiques, documents) et des performances agentiques soutenues avec moins de gaspillage de jetons dans certains workflows (par ex., 42% mieux sur un benchmark cyber avec 72% de jetons en moins).
Équilibre entre vitesse et capacités agentiques
Gemini 3.5 Flash se démarque par le compromis vitesse-intelligence. Il atteint un débit élevé (>280 jetons/s) tout en prenant en charge des comportements agentiques sophistiqués comme le déploiement de sous-agents, l’exécution en parallèle et l’itération rapide.
L’effort de réflexion par défaut est désormais medium, au lieu de high dans Gemini 3 Flash Preview.
Les niveaux de réflexion permettent un contrôle précis :
- Medium (default) : Meilleur équilibre pour la plupart des tâches de code et agentiques complexes.
- High : Maximise le raisonnement approfondi pour les problèmes les plus difficiles.
- Low/Minimal : Ultra-faible latence pour les requêtes plus simples.
Google rapporte des gains significatifs d’efficacité en jetons dans des scénarios agentiques réels (par ex., réduction de 72% sur certains benchmarks cyber par rapport aux versions précédentes), ce qui le rend viable pour des workflows soutenus et de longue durée.
Compromis : Un prix plus élevé que les modèles Flash précédents entraîne une augmentation des coûts globaux dans les scénarios agentiques gourmands en jetons (coût de l’Intelligence Index 5.5x vs Gemini 3 Flash, en raison de la tarification + de l’usage).
Capacités améliorées des agents intelligents
Gemini 3.5 Flash fait progresser « l’ère Gemini agentique ». Améliorations clés :
- Boucles d’exécution agentiques parallèles : déploiement de multiples sous-agents pour la résolution de problèmes complexes.
- Codage et prototypage itératifs : exploration rapide de pistes de solution avec une utilisation dynamique des outils.
- Workflows multi-étapes à long horizon : gère des processus d’entreprise étendus avec préservation de la réflexion.
- Améliorations de l’utilisation d’outils : correspondance stricte des réponses de fonction, réponses de fonction multimodales, et moins d’appels inutiles grâce à un meilleur prompting et à des niveaux de réflexion plus bas. Solide sur OSWorld et les tâches UI.
Il alimente les nouveaux agents d’information de Google, la recherche autonome et les pipelines de codage. Dans les tests internes, il excelle à construire des systèmes complexes et à gérer des projets de recherche.
Pour les développeurs, la nouvelle Interactions API (beta) simplifie la gestion de l’historique côté serveur, semblable à des schémas avancés dans d’autres écosystèmes.
Recommandation CometAPI : Utilisez notre API unifiée pour chaîner Gemini 3.5 Flash avec des modèles spécialisés (par ex., Claude pour la relecture de code approfondie ou GPT pour des tâches créatives) dans des systèmes agentiques. Nos fonctions de routage et de repli garantissent fiabilité et économies.
Leadership multimodal
Google maintient son leadership en compréhension multimodale. Gemini 3.5 Flash traite et raisonne nativement sur texte + image + vidéo + audio + documents. Il mène ou concurrence de près sur des benchmarks comme CharXiv, MMMU-Pro et des tâches de compréhension vidéo.
Cas d’usage : synthèse de graphiques/données, analyse vidéo, appels de fonctions multimodaux (par ex., traitement d’images dans les réponses d’outils), et agents riches en médias. Cela en fait un choix idéal pour des applications en e-commerce, création de contenu, visualisation scientifique, etc.
Tarification : Combien coûte Gemini 3.5 Flash ?
Tarification de l’API Gemini (par 1M de jetons, tarifs globaux approximatifs) :
- Entrée (texte/image/vidéo/audio) : $1.50
- Sortie : $9.00
- Mise en cache de contexte : $0.15 (économies significatives pour les prompts répétés)
Cela représente une augmentation d’environ ~3x par rapport à Gemini 3 Flash Preview ($0.50/$3) tout en restant compétitif au vu du gain de capacités. Cela se rapproche de la tarification de Gemini 3.1 Pro ($2/$12) tout en offrant une meilleure vitesse pour de nombreuses charges.
Les paliers Enterprise/Agent Platform peuvent varier avec des remises volume et des options additionnelles. Les entrées mises en cache et un prompting efficace (niveaux de réflexion plus bas, historiques optimisés) aident à maîtriser significativement les coûts.
Cela représente une augmentation d’environ ~3x par rapport à Gemini 3 Flash Preview ($0.50/$3) tout en restant compétitif au vu du gain de capacités. Cela se rapproche de la tarification de Gemini 3.1 Pro ($2/$12) tout en offrant une meilleure vitesse pour de nombreuses charges.
Niveau gratuit : accès limité via Google AI Studio/Gemini app ; payant pour la production.
Avantage CometAPI : Accédez à l’API Gemini 3.5 Flash aux côtés de 100+ modèles avec des tarifs compétitifs, de l’analytique d’usage et des outils d’optimisation pour minimiser la dépense en jetons. Notre plateforme offre souvent une tarification effective meilleure via un routage intelligent et du batching. Les prix API sont typiquement 20% inférieurs aux prix officiels.
Gemini 3.5 Flash vs. GPT-5.5, Claude 4.7/4.6 et autres
Points forts de Gemini 3.5 Flash :
- Équilibre vitesse + agentique : inférence plus rapide que la plupart des modèles de pointe tout en comblant l’écart d’intelligence.
- Multimodal & long contexte : contexte natif 1M et leadership en vision.
- Coût pour les volumes : moins cher par jeton que les principaux Claude/GPT pour de nombreux workloads, surtout avec cache.
- Écosystème Google : intégration fluide avec Search, Workspace, Cloud.
Où les concurrents le dépassent :
- GPT-5.5 domine souvent le raisonnement brut (par ex., ARC-AGI) et peut avoir de meilleures capacités créatives/générales.
- Claude Opus 4.7/Sonnet 4.6 excellent en codage prudent (SWE-Bench plus élevé dans certains cas) et en écriture/fiabilité fine.
- L’efficacité en jetons varie ; les boucles agentiques peuvent rendre 3.5 Flash plus coûteux au global.
Comparaison de haut niveau (métriques approximatives/sélectionnées ; vérifiez toujours les derniers classements) :
| Benchmark / Indicateur | Gemini 3.5 Flash | GPT-5.5 | Claude Opus 4.7 / Sonnet 4.6 | Gemini 3.1 Pro | Notes |
|---|---|---|---|---|---|
| Terminal-bench 2.1 (Codage) | 76.2% | 78.2% | ~66% | 70.3% | Codage agentique |
| MCP Atlas (Agentique) | 83.6% | 75.3% | 79.1% / 69.5% | 78.2% | Workflows multi-étapes |
| GDPval-AA (Connaissance agentique) | 1656 Elo | 1769 | 1753 | 1314 | Valeur économique |
| MMMU-Pro (Multimodal) | 83.6% | 81.2% | ~75% | 80.5% | Fort leadership Gemini |
| Intelligence Index (AA) | 55 | Elevé (varie) | Compétitif | Inférieur | Pareto vitesse/intel |
| Vitesse (jetons/s) | >280 | Inférieure | Variable | Plus lent | Avantage Flash |
| Prix Entrée/Sortie ($/1M) | 1.50 / 9.00 | Plus élevé | Plus élevé (surtout Opus) | 2/12 | Coût-efficacité de pointe |
| Fenêtre de contexte | 1M | Compétitive | Solide | 1M+ | Tous niveau de pointe |
Résumé des compromis :
- Gemini 3.5 Flash gagne sur vitesse + multimodal + efficacité agentique à l’échelle.
- GPT-5.5 domine souvent en raisonnement/codage brut.
- Claude 4.7 Opus excelle en codage soigneux, haute fiabilité, mais avec un coût/latence plus élevés.
Gemini mène fréquemment ou égalise sur le multimodal et certaines suites agentiques, tout en étant plus rapide et plus abordable pour des volumes élevés.
Comment accéder et intégrer Gemini 3.5 Flash
Accès via :
- Gemini App / Google AI Studio
- Gemini API (
gemini-3.5-flash) - Google Cloud Vertex AI / Enterprise Agent Platform
- Agrégateurs tiers pour une flexibilité multi-fournisseurs.
Recommandation CometAPI : Pour des applications de production sur Cometapi.com, intégrez une seule fois via une clé API unique pour accéder à Gemini 3.5 Flash (et 500+ modèles d’OpenAI, Anthropic, xAI, etc.) avec une tarification effective 20-40% inférieure, sans verrouillage fournisseur, et un échange de modèles aisé.
Avantages pour vos projets :
- Testez Gemini 3.5 Flash face à GPT-5.5 ou Claude 4.7 instantanément en changeant le nom du modèle.
- Facturation unifiée, routage de repli, et latence optimisée.
- Idéal pour les apps agentiques nécessitant fiabilité multi-fournisseurs.
- Inscription clé API gratuite avec limites de test généreuses.
L’intégration d’exemple est simple avec les SDK officiels ou l’endpoint unifié de CometAPI — parfait pour mettre à l’échelle le codage
Cas d’usage et bonnes pratiques
- Automatisation agentique : Construisez des systèmes multi-agents robustes pour la recherche, l’analyse de données ou le support client.
- Codage & développement : Prototypage itératif, débogage, et génération de pipelines complets dans Antigravity ou des IDE.
- Applications multimodales : Analyse d’images/vidéos, compréhension de graphiques, génération de contenu.
- Workflows d’entreprise : Processus à long horizon avec contrôle des coûts via cache et niveaux de réflexion.
Conseils : Utilisez l’historique complet de conversation pour la préservation de la réflexion. Commencez avec medium. Optimisez les prompts pour réduire les appels d’outils. Surveillez l’usage des jetons pour l’efficacité des coûts.
Limites et considérations
- L’augmentation de prix nécessite une optimisation soignée pour les apps à grand volume.
- Pas d’« utilisation de l’ordinateur » pour l’instant (surveillez les mises à jour).
- Les évaluations de sécurité montrent des performances solides avec des améliorations de ton, bien que les métriques automatisées varient.
- La réduction des hallucinations est notable mais validez toujours les sorties critiques.
- Augmentation de prix : plus élevé que les modèles Flash précédents ; optimisez via niveaux de réflexion et cache.
- Date limite des connaissances : janvier 2025 — utilisez des outils de grounding/Search pour l’actualité.
Conclusion : Gemini 3.5 Flash en vaut-il la peine ?
Oui — pour les développeurs et entreprises priorisant vitesse, fiabilité agentique, capacités multimodales et performances à l’échelle. Il pousse la frontière de Pareto, rendant l’IA de pointe plus accessible pour des charges de production.
Prêt à construire ? Rendez-vous sur CometAPI pour tester Gemini 3.5 Flash avec d’autres modèles de premier plan sur un même tableau de bord. Optimisez votre pile IA, réduisez les coûts et livrez plus vite.