

Google ha rilasciato Gemini 3.5 Flash il 19 maggio 2026, all'I/O, posizionandolo come un modello ad alta intelligenza, ottimizzato per la velocità, per prestazioni di frontiera sostenute in flussi di lavoro agentici, coding e compiti multimodali. Si basa sulle fondamenta di Gemini 3 Flash con livelli di “pensiero” migliorati per bilanciare qualità, costo e latenza.
Questa guida completa copre tutto: cos’è Gemini 3.5 Flash, le sue caratteristiche chiave, le prestazioni dettagliate nei benchmark, i prezzi, i confronti con GPT-5.5, Claude 4.7/4.6 e altro. In qualità di principale aggregatore di API di IA, CometAPI aiuta gli sviluppatori ad accedere a Gemini 3.5 Flash (e concorrenti) con prezzi unificati, integrazione semplificata e strumenti di ottimizzazione dei costi.
What Is Gemini 3.5 Flash?
Gemini 3.5 Flash si basa sulle fondamenta di ragionamento di Gemini 3 Flash con “livelli di pensiero” migliorati (minimo, basso, medio/predefinito, alto) per affinare il compromesso qualità-latenza-costo. È un modello nativamente multimodale che supporta testo, immagini, video, audio e documenti (inclusi PDF), con una finestra di contesto da 1M token e fino a 65K token di output. Il limite della conoscenza è gennaio 2025.
Differenziatori chiave rispetto ai modelli Flash precedenti:
- Prestazioni di frontiera sostenute su compiti agentici, coding e a lungo orizzonte.
- Conservazione del ragionamento: mantiene automaticamente il ragionamento intermedio nelle conversazioni multi-turn senza modifiche aggiuntive all’API.
- Ottimizzato per la scala: progettato per esecuzione agentica parallela, coding iterativo e flussi di lavoro enterprise multi-step.
- Nessun supporto per l’uso del computer (per ora), ma significativi miglioramenti nell’uso degli strumenti e nelle chiamate di funzione.
Google lo presenta come il “modello Flash più intelligente” per l’uso in produzione, superando il precedente Gemini 3.1 Pro in molti benchmark agentici e di coding, offrendo al contempo velocità da Flash (spesso >280 token di output/secondo nei test).
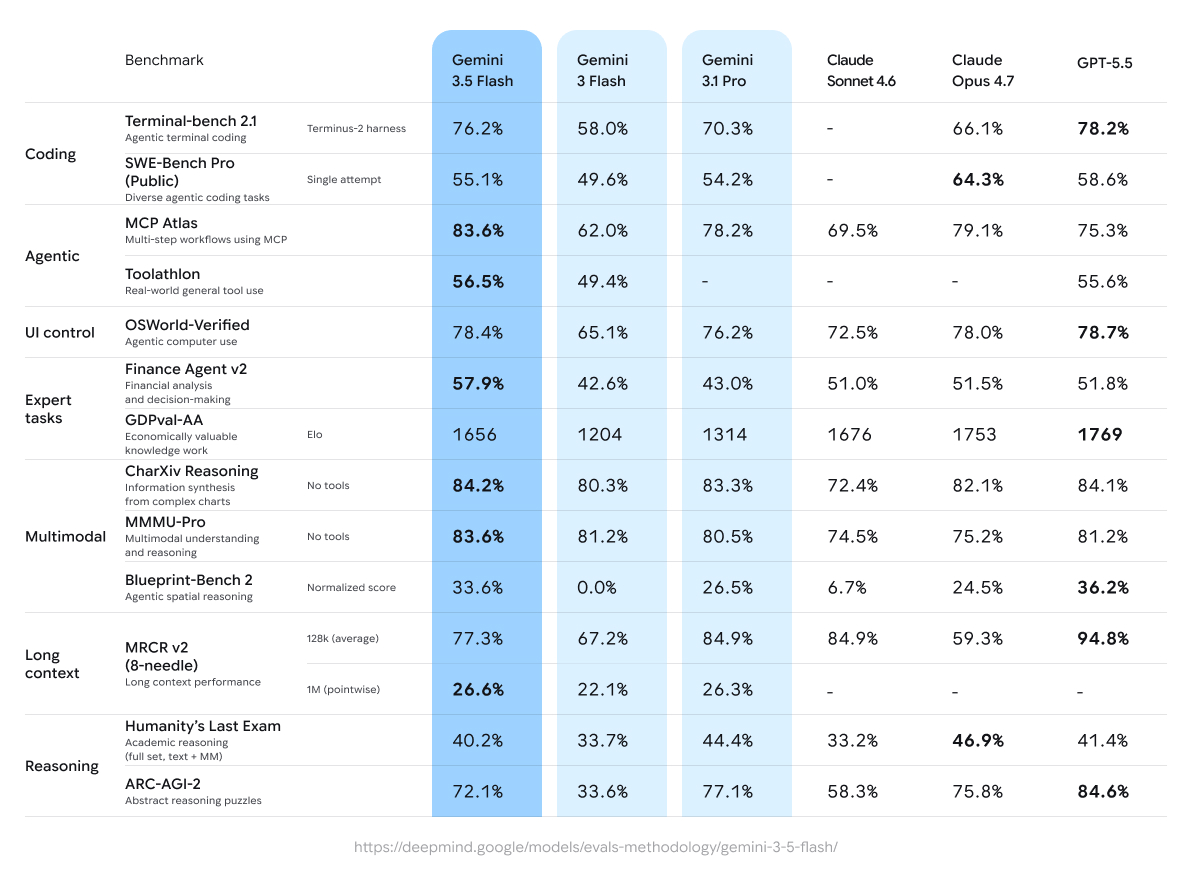
Gemini 3.5 Flash eccelle in flussi di lavoro agentici e coding con intelligenza quasi Pro a latenza e costo ottimizzati, ottenendo punteggi come 76.2% su Terminal-bench 2.1 e 83.6% su task multi-step MCP Atlas.
Benchmark Performance breakthrough
Test indipendenti confermano che offre prestazioni di livello Pro o superiori in compiti di coding/agentici a velocità maggiore, sebbene i costi complessivi di esecuzione dei benchmark aumentino a causa di un maggior numero di token usati in loop agentici complessi e del prezzo 3x rispetto ai precedenti modelli Flash.
Gemini 3.5 Flash mostra forti guadagni rispetto ai predecessori, in particolare nei domini agentici e di coding. Ecco i risultati chiave dal model card di Google DeepMind e da valutazioni indipendenti (a maggio 2026):
Selected Benchmarks (Gemini 3.5 Flash vs. comparators):
Coding:
- Terminal-bench 2.1 (Agentic terminal coding): 76.2% (vs. Gemini 3 Flash 58.0%, Gemini 3.1 Pro 70.3%, GPT-5.5 78.2%)
- SWE-Bench Pro (Public, diverse agentic coding): 55.1% (vs. 49.6% per 3 Flash, 54.2% per 3.1 Pro)
Agentic Tool Use:
- MCP Atlas (Multi-step workflows): 83.6% (netto vantaggio)
- Toolathlon (Uso generale di strumenti nel mondo reale): 56.5%
- Finance Agent v2: 57.9% (+15.3% significativo rispetto a 3 Flash)
Multimodal:
- CharXiv (Ragionamento su grafici): 84.2%
- MMMU-Pro: 83.6% (supera molti concorrenti)
Reasoning & Long Context:
- Humanity’s Last Exam: 40.2%
- ARC-AGI-2: 72.1%
- MRCR v2 (128k): 77.3%; forte su 1M di contesto a 26.6% punto per punto.
Artificial Analysis Intelligence Index: Gemini 3.5 Flash totalizza 55 (pensiero elevato), +9 punti rispetto a Gemini 3 Flash. Guida la frontiera di Pareto Intelligenza vs. Velocità, con progressi nei compiti agentici e riduzione delle allucinazioni (fino al 61% di tasso di allucinazioni). Raggiunge >280 token di output/secondo ma comporta un maggiore uso di token nei loop agentici.
Brilla nel lungo contesto (forte su MRCR v2 e 1M punto per punto), leadership multimodale (grafici, documenti) e prestazioni agentiche sostenute con riduzione dello spreco di token in alcuni flussi di lavoro (ad esempio, +42% su benchmark cyber con il 72% di token in meno).
Balance of Speed and Agentic Capabilities
Gemini 3.5 Flash si distingue nel compromesso velocità-intelligenza. Ottiene un throughput elevato (>280 token/s) supportando comportamenti agentici sofisticati come dispiegamento di sotto-agenti, esecuzione parallela e iterazione rapida.
Lo sforzo di pensiero predefinito ora è medium, cambiato da high in Gemini 3 Flash Preview.
I Thinking Levels consentono un controllo preciso:
- Medium (predefinito): Miglior equilibrio per la maggior parte dei compiti di coding complessi e agentici.
- High: Massimizza il ragionamento profondo per i problemi più difficili.
- Low/Minimal: Latenza ultra-bassa per le query più semplici.
Google riporta significativi guadagni di efficienza dei token in scenari agentici reali (ad es., riduzione del 72% in alcuni benchmark cyber rispetto alle versioni precedenti), rendendolo adatto a flussi di lavoro sostenuti e di lunga durata.
Trade-off: Prezzo più alto rispetto ai precedenti modelli Flash comporta costi complessivi maggiori in scenari agentici a elevato uso di token (costo dell’Intelligence Index 5.5x vs. Gemini 3 Flash per effetto combinato di prezzo + utilizzo).
Enhanced Capabilities of Intelligent Agents
Gemini 3.5 Flash fa avanzare la “era Gemini agentica”. Miglioramenti chiave includono:
- Loop di esecuzione agentici paralleli: dispiegare più sotto-agenti per la risoluzione di problemi complessi.
- Coding e prototipazione iterativi: esplorazione rapida dei percorsi di soluzione con uso dinamico degli strumenti.
- Flussi di lavoro multi-step a lungo orizzonte: gestisce processi enterprise estesi con conservazione del ragionamento.
- Miglioramenti nell’uso degli strumenti: corrispondenza rigorosa delle risposte di funzione, risposte di funzione multimodali e riduzione delle chiamate non necessarie tramite prompt migliori e livelli di pensiero più bassi. Forte su OSWorld e attività UI.
Alimenta i nuovi agenti informativi di Google, la ricerca autonoma e le pipeline di coding. In test interni, eccelle nella costruzione di sistemi complessi e nella gestione di progetti di ricerca.
Per gli sviluppatori, la nuova Interactions API (beta) semplifica la gestione della cronologia lato server, in linea con pattern avanzati di altri ecosistemi.
Raccomandazione CometAPI: Usa la nostra API unificata per concatenare Gemini 3.5 Flash con modelli specializzati (ad es., Claude per revisioni di codice approfondite o GPT per compiti creativi) in sistemi agentici. Le nostre funzionalità di instradamento e fallback assicurano affidabilità e risparmi.
Multimodal Leadership
Google mantiene la leadership nella comprensione multimodale. Gemini 3.5 Flash elabora e ragiona nativamente su testo + immagini + video + audio + documenti. Guida o compete da vicino in benchmark come CharXiv, MMMU-Pro e compiti di comprensione video.
Casi d’uso: sintesi di grafici/dati, analisi video, chiamate di funzione multimodali (ad es., elaborazione di immagini nelle risposte degli strumenti) e agenti multimediali ricchi. Ciò lo rende ideale per applicazioni in e-commerce, creazione di contenuti, visualizzazione scientifica e altro.
Pricing: How Much Does Gemini 3.5 Flash Cost?
Prezzi Gemini API (per 1M token, tariffe globali approssimative):
- Input (testo/immagine/video/audio): $1.50
- Output: $9.00
- Context caching: $0.15 (risparmi significativi per prompt ripetuti)
Questo rappresenta un aumento di ~3x rispetto a Gemini 3 Flash Preview ($0.50/$3) ma resta competitivo per il salto di capacità. Si avvicina ai prezzi di Gemini 3.1 Pro ($2/$12) offrendo al contempo una velocità migliore per molti carichi.
Questo rappresenta un aumento di ~3x rispetto a Gemini 3 Flash Preview ($0.50/$3) ma resta competitivo per il salto di capacità. Si avvicina ai prezzi di Gemini 3.1 Pro ($2/$12) offrendo al contempo una velocità migliore per molti carichi.
Free Tier: Accesso limitato tramite Google AI Studio/app Gemini; a pagamento per la produzione.
Vantaggio Cometapi: Accedi alla Gemini 3.5 Flash API insieme a 100+ modelli con tariffe competitive, analisi dell’utilizzo e strumenti di ottimizzazione per ridurre la spesa di token. La nostra piattaforma spesso offre prezzi effettivi migliori tramite routing intelligente e batching. I prezzi API sono tipicamente inferiori del 20% rispetto a quelli ufficiali.
Gemini 3.5 Flash vs. GPT-5.5, Claude 4.7/4.6 and Others
Punti di forza di Gemini 3.5 Flash:
- Equilibrio velocità + agenticità: inferenza più rapida della maggior parte dei modelli di frontiera riducendo il gap di intelligenza.
- Multimodale & lungo contesto: contesto nativo da 1M e leadership nella visione.
- Costo per volume: più economico per token rispetto ai migliori Claude/GPT per molti carichi, specialmente con caching.
- Ecosistema Google: integrazione senza soluzione di continuità con Search, Workspace, Cloud.
Dove i concorrenti lo superano:
- GPT-5.5 spesso guida nel ragionamento puro (ad es., ARC-AGI) e può avere capacità creative/generali più forti.
- Claude Opus 4.7/Sonnet 4.6 eccellono nel coding attento (SWE-Bench più alto in alcuni casi) e nella scrittura/sicurezza sfumata.
- L’efficienza dei token varia; i loop agentici possono rendere 3.5 Flash più costoso complessivamente.
Confronto di alto livello (metriche approssimative/selezionate; verifica sempre le classifiche più recenti):
| Benchmark / Metric | Gemini 3.5 Flash | GPT-5.5 | Claude Opus 4.7 / Sonnet 4.6 | Gemini 3.1 Pro | Note |
|---|---|---|---|---|---|
| Terminal-bench 2.1 (Coding) | 76.2% | 78.2% | ~66% | 70.3% | Coding agentico |
| MCP Atlas (Agentic) | 83.6% | 75.3% | 79.1% / 69.5% | 78.2% | Flussi di lavoro multi-step |
| GDPval-AA (Agentic Knowledge) | 1656 Elo | 1769 | 1753 | 1314 | Valore economico |
| MMMU-Pro (Multimodale) | 83.6% | 81.2% | ~75% | 80.5% | Forte vantaggio Gemini |
| Intelligence Index (AA) | 55 | Alto (varia) | Competitivo | Inferiore | Pareto velocità/intel |
| Speed (tokens/s) | >280 | Inferiore | Variabile | Più lento | Vantaggio Flash |
| Input/Output Price ($/1M) | 1.50 / 9.00 | Più alto | Più alto (spec. Opus) | 2/12 | Frontiera conveniente |
| Context Window | 1M | Competitivo | Forte | 1M+ | Tutti di livello frontiera |
Riepilogo dei compromessi:
- Gemini 3.5 Flash vince su velocità + multimodale + efficienza agentica per la scala.
- GPT-5.5 spesso prevale su picchi di ragionamento/coding.
- Claude 4.7 Opus eccelle nel coding attento e ad alta affidabilità ma a costo/latenza maggiori.
Gemini spesso guida o eguaglia nelle suite multimodali e agentiche specifiche, risultando più veloce e più economico per usi ad alto volume.
How to Access and Integrate Gemini 3.5 Flash
Accesso tramite:
- App Gemini / Google AI Studio
- Gemini API (
gemini-3.5-flash) - Google Cloud Vertex AI / Enterprise Agent Platform
- Aggregatori di terze parti per flessibilità multi-provider.
Raccomandazione Cometapi: Per applicazioni in produzione su Cometapi.com, integra una sola volta con una singola chiave API per accedere a Gemini 3.5 Flash (e 500+ modelli da OpenAI, Anthropic, xAI, ecc.) con prezzi effettivi inferiori del 20-40%, senza lock-in del fornitore e facile sostituzione dei modelli.
Vantaggi per i tuoi progetti:
- Prova Gemini 3.5 Flash rispetto a GPT-5.5 o Claude 4.7 istantaneamente cambiando il nome del modello.
- Fatturazione unificata, fallback routing e latenza ottimizzata.
- Ideale per app agentiche che necessitano affidabilità tra provider.
- Registrazione con chiave API gratuita con limiti di test generosi.
L’integrazione è semplice con gli SDK ufficiali o l’endpoint unificato di CometAPI—perfetta per scalare la codifica
Use Cases and Best Practices
- Automazione agentica: costruisci sistemi multi-agente robusti per ricerca, analisi dei dati o assistenza clienti.
- Coding & sviluppo: prototipazione iterativa, debug e generazione di pipeline complete in Antigravity o IDE.
- Applicazioni multimodali: analisi di immagini/video, comprensione di grafici, generazione di contenuti.
- Flussi di lavoro enterprise: processi a lungo orizzonte con controllo dei costi via caching e livelli di pensiero.
Suggerimenti: usa l’intera cronologia della conversazione per la conservazione del ragionamento. Parti da medium. Ottimizza i prompt per ridurre le chiamate agli strumenti. Monitora l’uso di token per l’efficienza dei costi.
Limitations and Considerations
- L’aumento di prezzo richiede un’ottimizzazione attenta per app ad alto volume.
- Nessun computer use per ora (monitora gli aggiornamenti).
- Le valutazioni di sicurezza mostrano buone prestazioni con miglioramenti nel tono, sebbene le metriche automatizzate varino.
- La riduzione delle allucinazioni è notevole, ma verifica sempre gli output critici.
- Aumento di prezzo: superiore ai precedenti modelli Flash; ottimizza con livelli di pensiero e caching.
- Limite della conoscenza: gennaio 2025—usa strumenti di grounding/Search per eventi attuali.
Conclusion: Is Gemini 3.5 Flash Worth It?
Sì—per sviluppatori ed enterprise che danno priorità a velocità, affidabilità agentica, capacità multimodali e prestazioni scalabili. Spinge la frontiera di Pareto, rendendo l’IA di frontiera più accessibile ai carichi di produzione.
Pronti a creare? Vai su CometAPI oggi stesso per testare Gemini 3.5 Flash insieme ad altri top model in un’unica dashboard. Ottimizza il tuo stack di IA, riduci i costi e distribuisci più velocemente.