

Nel mondo in rapida evoluzione degli assistenti di coding basati su AI, il rilascio di Kimi K2.7 Code da parte di Moonshot AI il 12 giugno 2026 si distingue come un salto significativo per sviluppatori, agenti AI e aziende in cerca di soluzioni potenti, convenienti e open-source.
Questo modello di coding specializzato si basa sulla famiglia K2, enfatizzando compiti di ingegneria del software a lungo orizzonte, un affidabile rispetto delle istruzioni in contesti massivi, chiamate a strumenti multi-turno, input visivi e output strutturati per flussi di lavoro agentici. Con 1 trilione di parametri totali ma solo 32 miliardi attivati per token tramite un design Mixture-of-Experts (MoE), offre capacità di frontiera a una frazione del costo di modelli chiusi come Claude Opus 4.8 o GPT-5.5.
CometAPI ha ora integrato Kimi K2.7 Code, rendendolo accessibile senza soluzione di continuità attraverso un singolo endpoint compatibile con OpenAI a un prezzo inferiore rispetto al prezzo ufficiale. Questa integrazione consente agli sviluppatori di cambiare modello senza sforzo, ottimizzare i costi e creare applicazioni AI robuste senza gestire più provider.
Che cos'è Kimi K2.7 Code?
Kimi K2.7 Code (anche noto come Kimi-K2.7-Code o kimi-k2.7-code) è un modello MoE agentico focalizzato sul coding, sviluppato da Moonshot AI. È esplicitamente costruito per compiti di ingegneria del software a lungo orizzonte—scenari in cui un'AI deve mantenere il contesto per migliaia di passaggi, navigare repository, invocare strumenti, modificare codice tra moduli, eseguire test, fare debug e iterare fino al completamento.
Caratteristiche chiave:
- Pesi aperti su Hugging Face (
moonshotai/Kimi-K2.7-Code). - Licenza MIT modificata – permissiva per uso commerciale con requisiti di attribuzione per distribuzioni ad alto volume.
- Supporto multimodale nativo – testo + immagine + video tramite encoder MoonViT (~400M parametri).
- Modalità di ragionamento sempre attiva – obbligatoria per prestazioni agentiche affidabili; non può essere disabilitata.
A differenza dei modelli di chat generali, K2.7 Code è ottimizzato per l’affidabilità in sessioni estese. Riduce l’“overthinking” (token di ragionamento interni eccessivi) di circa il 30% rispetto a K2.6, con conseguenti costi inferiori, iterazioni più rapide e tassi di successo end-to-end migliori in flussi di lavoro complessi.
Questo lo rende ideale per:
- Refactoring a scala di repository.
- Generazione di codice multi-lingaggio (Python, Rust, Go, ecc.).
- Uso agentico degli strumenti (MCP, CI/CD, operazioni su file system).
- Compiti di frontend, DevOps, ottimizzazione delle prestazioni e ML engineering.
Cosa c'è di nuovo in Kimi K2.7 Code?
1) Coding più forte a lungo orizzonte
Il maggiore upgrade è un miglioramento delle prestazioni nei compiti di coding a lungo orizzonte. Moonshot afferma che K2.7 Code migliora il successo end-to-end in flussi di lavoro complessi di ingegneria del software, non solo nel completamento di codice one-shot. È il tipo di upgrade che gli sviluppatori notano quando un modello riesce a mantenere il filo di un progetto per molti turni invece di perdere la rotta dopo i primi passaggi.
Consistenti miglioramenti sui benchmark rispetto a K2.6:
- +21.8% su Kimi Code Bench v2 (62.0% vs. 50.9%)
- +11.0% su Program Bench (53.6% vs. 48.3%)
- +31.5% su MLS Bench Lite (35.1% vs. 26.7%)
- +9.3% su Kimi Claw 24/7 Bench
- +9.5% su MCP Atlas
- +11.4% su MCP Mark Verified (81.1% vs. 72.8%)
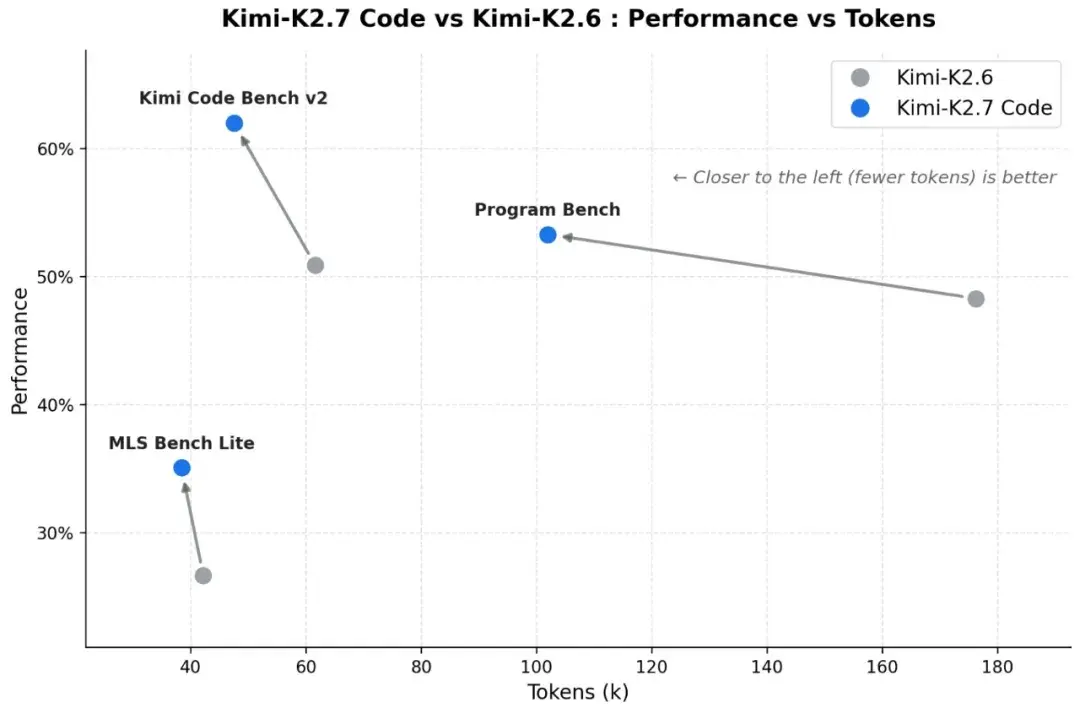
2) Migliore efficienza di ragionamento
Moonshot riporta che K2.7 Code usa circa il 30% di token di ragionamento in meno rispetto a K2.6. Il changelog di Workers AI di Cloudflare conferma tale efficienza e aggiunge che un minore uso di token di ragionamento può ridurre il costo di inferenza su carichi di lavoro pesanti in ragionamento. In parole semplici: il modello non è solo più intelligente nei compiti di coding, è anche più economico quando “pensa”.
3) Comportamento di ragionamento predefinito
Kimi K2.7 Code è solo un modello “pensante”. Moonshot afferma che non supporta la modalità senza ragionamento e, in Kimi Code, se il ragionamento è disattivato, il sistema torna automaticamente a K2.6. È un dettaglio utile per i team che costruiscono strumenti di coding agentici, perché significa che dovreste progettare dando per scontato il ragionamento attivo di default.
4) Capacità potenziate a lungo orizzonte:
Migliore generalizzazione tra linguaggi (Python, Rust, Go, ecc.) e scenari (frontend, DevOps, sicurezza, ML). Maggiori tassi di successo end-to-end.
5) Multimodale e uso strumenti migliorati
Encoder visivo (400M parametri) per immagini/video; integrazione MCP/strumenti senza attriti per ambienti reali (GitHub, Postgres, browser, ecc.).
Architettura e parametri di Kimi K2.7 Code
Kimi K2.7 Code utilizza un’architettura Mixture-of-Experts. Secondo la model card ufficiale su Hugging Face, ha 1T parametri totali e 32B parametri attivati. Include 61 strati, 384 esperti, 8 esperti selezionati per token, 1 esperto condiviso, attenzione MLA, attivazione SwiGLU, un vocabolario da 160K, e una lunghezza del contesto di 256K. L’encoder visivo è MoonViT con 400M parametri.
Questa architettura spiega l’attrattiva del modello. Un modello MoE da un trilione di parametri può mantenere un enorme tetto di capacità attivando solo un sottoinsieme di parametri per token, uno dei motivi per cui i sistemi MoE sono appetibili per l’inferenza ad alta capacità. K2.7 Code adotta lo stesso approccio di quantizzazione INT4 nativa di K2 Thinking, migliorando l’efficienza di deployment.
La finestra di contesto è un altro grande punto di forza. La documentazione ufficiale descrive una finestra da 256K, sufficiente per codebase lunghe, conversazioni estese e sessioni agentiche multi-step in cui la ritenzione del contesto è fondamentale.
K2.7 Code condivide lo stesso disegno di ragionamento intercalato e chiamate a strumenti a più passaggi di K2 Thinking, e raccomanda Kimi Code CLI come framework per agenti più adatto al modello. È un forte segnale che Moonshot vede K2.7 Code come un cavallo di battaglia agentico, non semplicemente un modello per interfacce di chat.
Specifiche principali (dalla model card ufficiale):
- Parametri totali: 1T (1 trilione)
- Parametri attivati per token: 32B (circa 3% di attivazione sparsa per efficienza)
- Esperti: 384 totali (8 selezionati per token + 1 esperto condiviso)
- Strati: 61 (incluso 1 strato denso)
- Attenzione: MLA (Multi-head Latent Attention)
- Attivazione Feed-Forward: SwiGLU
- Dimensione del vocabolario: ~160K–166K
- Encoder visivo: MoonViT (~400M parametri) per multimodale nativo (testo + immagine/video)
- Lunghezza del contesto: 256K token (262,144)
- Quantizzazione: supporto INT4 nativo per deployment efficiente
- Addestramento: ottimizzatore Muon, addestrato su massivi token testuali/visivi con miglioramenti di stabilità.
Perché l’architettura MoE è importante: Solo ~3% dei parametri si attiva per token, offrendo capacità quasi di frontiera a una frazione del costo computazionale dei modelli densi di dimensioni totali simili. Ciò abilita self-hosting o uso API abbordabili per compiti di coding ad alto volume.
Il modello è grande (pesi ~595 GB), mirato a inferenza di classe server (vLLM, SGLang, KTransformers). Riutilizza pattern di deployment da K2.5/K2.6.
Benchmark delle prestazioni: quanto è valido?
Moonshot fornisce benchmark dettagliati di prima parte che confrontano K2.7 Code con K2.6, GPT-5.5 e Claude Opus 4.8. Sebbene la verifica indipendente sia in corso (ad es., alcuni practitioner notano risultati misti su kernel pubblici), i guadagni sono notevoli per uno specialista del coding.
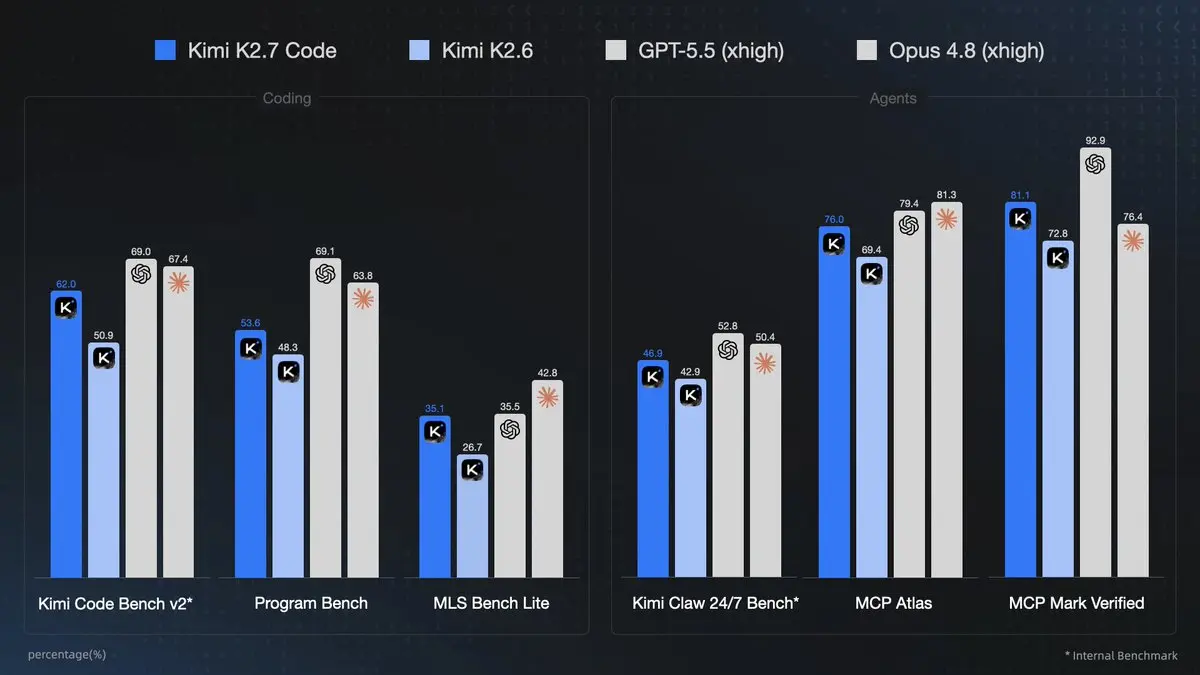
Tabella dei benchmark chiave:
| Benchmark | Kimi K2.6 | Kimi K2.7 Code | GPT-5.5 | Claude Opus 4.8 | Incremento (K2.7 vs K2.6) |
|---|---|---|---|---|---|
| Kimi Code Bench v2 | 50.9 | 62.0 | 69.0 | 67.4 | +21.8% |
| Program Bench | 48.3 | 53.6 | 69.1 | 63.8 | +11.0% |
| MLS Bench Lite | 26.7 | 35.1 | 35.5 | 42.8 | +31.5% |
| Kimi Claw 24/7 Bench | 42.9 | 46.9 | 52.8 | 50.4 | +9.3% |
| MCP Atlas | 69.4 | 76.0 | 79.4 | 81.3 | +9.5% |
| MCP Mark Verified | 72.8 | 81.1 | 92.9 | 76.4 | +11.4% |
Interpretazione:
- K2.7 Code riduce il gap con i modelli di frontiera su compiti di coding/agentici e supera Opus 4.8 su MCP Mark Verified.
- Forte in scenari multi-lingua, di ingegneria del software reale e di uso strumenti.
- Il vantaggio di efficienza (30% di token in meno) spesso lo rende preferibile per agenti di lunga durata, pur non primeggiando sempre in accuratezza grezza: meno token per task significa più iterazioni entro limiti di budget/contesto.
Avvertenze: Molti test sono interni o con setup specifici. Test indipendenti (es., KernelBench) mostrano risultati misti su alcuni task di basso livello, ma il riscontro dei practitioner evidenzia un’utilità pratica nei loop di coding prolungati.
Vantaggi di efficienza: costi e velocità
Una riduzione del 30% dei token di ragionamento può sembrare astratta finché non la si traduce in produzione. Meno token di ragionamento significano spesso minore latenza, costi inferiori e minore probabilità che il modello divaghi con passaggi interni non necessari su compiti lunghi. Moonshot afferma che K2.7 Code migliora l’efficienza preservando un completamento dei task più solido, e Cloudflare inquadra specificamente ciò come un vantaggio di costo per carichi di lavoro intensivi in ragionamento.
Questa combinazione conta negli agenti di coding perché i compiti di ingegneria del software raramente si risolvono in un solo passaggio. Comportano la lettura di una codebase, l’apporto di una modifica, la verifica, la gestione delle eccezioni e l’iterazione. Un modello più efficiente in termini di token e migliore nel completamento di compiti a lungo orizzonte può migliorare in modo sostanziale la produttività del team rispetto a un modello forte solo nelle risposte brevi. Si tratta di un’inferenza basata sui benchmark e sulle affermazioni di Moonshot sui flussi di lavoro, ma aderisce al posizionamento del modello.
Quanto costa Kimi K2.7 Code?
L’abbonamento Kimi Code di Moonshot include K2.7 Code e parte da $19/mese, secondo la pagina ufficiale. Questo è il percorso consumer. Per l’uso API, il prezzo dipende da dove si accede al modello. Rispetto a Claude Opus (~$5–25 / M) o prezzi simili di frontiera, K2.7 Code offre fino a 5–12x valore migliore per carichi di lavoro di coding. Il self-hosting riduce ulteriormente i costi per usi ad alto volume.
Su CometAPI, Kimi K2.7 Code è elencato a $0.76 per milione di token in input e $3.19998 per milione di token in output, mentre il prezzo ufficiale è indicato come $0.95 per milione di token in input e $3.999975 per milione di token in output, che CometAPI presenta come uno sconto del 20% rispetto al listino ufficiale.
Questo rende CometAPI interessante per i team che vogliono sperimentare con Kimi K2.7 Code senza gestire integrazioni con vendor separati o pagare il prezzo diretto più alto.
Dove accedere a Kimi K2.7 Code
1) Kimi Code
Moonshot afferma che Kimi K2.7 Code è ora il modello predefinito in Kimi Code, con modalità di ragionamento abilitata di default. È il modo più nativo per provare il modello se volete l’ambiente di coding di Moonshot.
2) Kimi API / Kimi Platform
La piattaforma aperta di Moonshot documenta Kimi K2.7 Code come disponibile tramite Kimi API, e indica che la piattaforma usa il formato dell’API OpenAI. Ciò facilita l’inserimento in architetture applicative esistenti che già parlano pattern API compatibili con OpenAI.
3) Hugging Face
La model card ufficiale su Hugging Face conferma il rilascio a pesi aperti, mostra il sommario del modello e i dati di benchmark e dichiara che il repository di codice e i pesi sono rilasciati sotto una Licenza MIT modificata. Questo è il percorso per gli sviluppatori che vogliono ispezionare i pesi, eseguire deployment autonomo o usare il modello in ecosistemi open.
4) CometAPI
CometAPI ora elenca Kimi K2.7 Code come modello integrato e fornisce prezzi per token, una pagina del modello e accesso API tramite il suo gateway unificato. Evidenzia inoltre che la piattaforma è compatibile con OpenAI e progettata per ridurre la frammentazione dei vendor mettendo molti modelli dietro un unico entrypoint. Supporta la finestra di contesto da 256K, input visivi, chiamate a strumenti multi-turno e un percorso compatibile con OpenAI via /v1/chat/completions. Non sono richieste modifiche ai parametri se si migra da K2.6.
Raccomandazione CometAPI: Per la maggior parte degli utenti, iniziate qui. Una sola chiave, pay-as-you-go su oltre 500 modelli, fallback automatici e tariffe effettive inferiori. Perfetto per testare K2.7 Code accanto a Claude, GPT o modelli open senza lock-in del vendor. Registrati su Cometapi.com e sostituisci la base URL/nome modello nel tuo client OpenAI.
Suggerimento per il self-hosting: Utilizza la quantizzazione INT4 e il parallelismo degli esperti per VRAM/prestazioni ottimali su GPU enterprise.
Kimi K2.7 Code vs K2.6 vs altri modelli
Se il vostro stack utilizza già K2.6, K2.7 Code è l’upgrade ovvio quando qualità del coding ed efficienza di ragionamento contano più del semplice mantenimento della baseline. Moonshot afferma che l’architettura è la stessa di K2.5/K2.6, il deployment riutilizzabile e le prestazioni ai benchmark migliorano in modo sostanziale. Cloudflare afferma inoltre che l’uso dell’API è identico, riducendo l’attrito di migrazione.
Rispetto a modelli di frontiera più generali come GPT-5.5 e Claude Opus 4.8, K2.7 Code è più specializzato. La tabella dei benchmark mostra che resta competitivo in compiti di coding e agent, ma il suo vero elemento distintivo è la combinazione di accesso open-source, lungo contesto e design incentrato sul coding. Ciò lo rende particolarmente attraente per i team che valorizzano flessibilità di deployment e controllo dei costi.
Conclusione: perché integrare Kimi K2.7 Code tramite CometAPI oggi
Kimi K2.7 Code rappresenta un ecosistema di AI per il coding open-source maturo—potente, efficiente, accessibile e pronto per agenti. La sua architettura, i guadagni nei benchmark e l’efficienza in token lo rendono un must-try per gli sviluppatori nel 2026.
CometAPI abbassa ulteriormente la barriera con integrazione senza attriti, prezzi competitivi e accesso unificato. Che si tratti di self-hosting, uso dell’API ufficiale o affidarsi alla piattaforma di CometAPI, K2.7 Code abilita flussi di lavoro di coding più rapidi e affidabili.
Pronto a provarlo? Visita CometAPI, ottieni la tua chiave API e inizia a costruire con Kimi K2.7 Code oggi. Sperimenta, confronta con i tuoi casi d’uso e scala con fiducia.
Domande frequenti
Kimi K2.7 Code è open source?
Sì. Moonshot afferma che sia il repository di codice sia i pesi del modello sono rilasciati sotto Licenza MIT modificata, e il modello è disponibile su Hugging Face.
Qual è la finestra di contesto?
La documentazione di Moonshot indica una finestra di contesto di 256K, e la model card e Cloudflare la descrivono come 262,144 o 262.1K token. Si tratta sostanzialmente della stessa scala.
Kimi K2.7 Code supporta la modalità senza ragionamento?
No. Moonshot afferma che K2.7 Code funziona solo con il ragionamento abilitato. In Kimi Code, disattivare il ragionamento comporta il fallback a K2.6.
Qual è il miglioramento più grande rispetto a K2.6?
Il maggiore miglioramento riportato è una performance migliore nel coding a lungo orizzonte, insieme a circa il 30% di token di ragionamento in meno. Moonshot segnala anche guadagni di +21.8% su Kimi Code Bench v2, +11.0% su Program Bench e +31.5% su MLS Bench Lite.
Posso usarlo tramite CometAPI?
Sì. CometAPI elenca ora Kimi K2.7 Code come modello integrato e mostra prezzi per token, rendendolo un percorso di accesso conveniente per sviluppatori che vogliono uno strato API unificato.
È adatto per agenti di coding basati su AI?
Sì. La documentazione di Moonshot enfatizza chiamate a strumenti a più passaggi, ragionamento intercalato e flussi di lavoro orientati agli agenti, mentre Cloudflare evidenzia chiamate a strumenti multi-turno e output strutturati.