

No cenário de IA em rápida evolução, GLM-5.2 da Z.ai (Zhipu AI) destaca-se como um modelo de pesos abertos formidável, otimizado para codificação de agentes, tarefas de longo horizonte e confiabilidade em produção. Com uma janela de contexto utilizável de 1M tokens, modos de raciocínio duplos (High e Max) e forte desempenho a uma fração do custo dos modelos fechados de ponta, está rapidamente se tornando a opção preferida para desenvolvedores que constroem agentes autônomos, integrações com IDE e fluxos complexos de engenharia de software.
Seja você um desenvolvedor solo prototipando agentes, um CTO avaliando escala com bom custo-benefício ou um gerente de produto de IA integrando raciocínio multimodal em SaaS, dominar a API do GLM-5.2 desbloqueia vantagens significativas.
O que é o GLM-5.2?
GLM-5.2 é o mais recente modelo flagship de pesos abertos Mixture-of-Experts (MoE) da Z.ai (Zhipu AI), lançado em meados de junho de 2026. Com aproximadamente 753 bilhões de parâmetros totais (cerca de 40B ativos por token), uma janela de contexto estável de 1 milhão de tokens, licença MIT e forte desempenho em tarefas de codificação de longo horizonte e agentes, posiciona-se como uma alternativa competitiva a modelos fechados de ponta como GPT-5.5, Claude Opus 4.8 e variantes do Gemini — a uma fração do custo para muitas cargas de trabalho.
Arquitetura e especificações técnicas do GLM-5.2
GLM-5.2 baseia-se na família GLM com atualizações-chave para trabalhos de longo horizonte.
- Parâmetros: ~753B totais em design MoE (parâmetros ativos ~40B por token). Isso oferece capacidade massiva com inferência eficiente.
- Janela de contexto: 1.048.576 tokens (1M). Saída máxima tipicamente até 128K–131K tokens.
- Precisão: BF16 (com variantes FP8 para implantações mais leves).
- Inovação-chave – IndexShare: reutiliza um único indexador entre grupos de camadas de atenção esparsa, reduzindo os FLOPs por token em até 2,9x em contexto de 1M. Isso viabiliza inferência de longo contexto sem explodir custos ou latência.
- Modos de raciocínio: “High” (equilibrado) e “Max” (mais profundo, recomendado para codificação). O raciocínio pode ser desativado para tarefas simples.
- Modalidades: principalmente texto/código (sem visão nativa confirmada na versão base).
- Licença: MIT — totalmente aberta para download, modificação e uso comercial.
Essa abertura e eficiência tornam o GLM-5.2 ideal para equipes que priorizam privacidade de dados, personalização ou controle de custos.
GLM-5.2 vs GLM-5.1
| Área | GLM-5.1 | GLM-5.2 | Diferença prática |
|---|---|---|---|
| Janela de contexto | Cerca de 200K nas rotas hospedadas comuns | 1M | GLM-5.2 é muito mais adequado para contexto de projeto inteiro |
| Esforço de raciocínio | Menos flexível | High e Max | Melhor controle de custo, latência e qualidade |
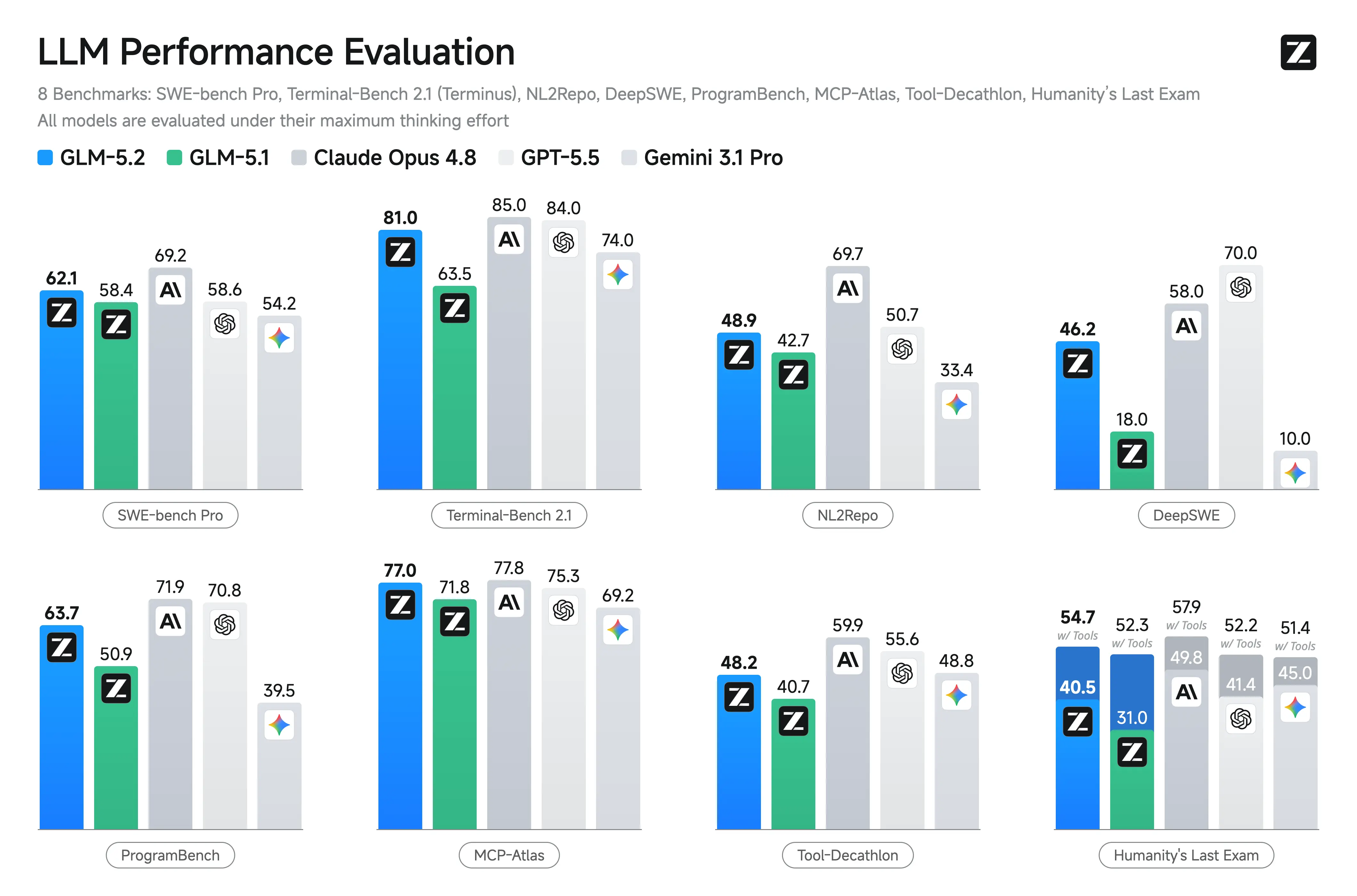
| Terminal Bench 2.1 | 63.5 na tabela publicada | 81.0 | Grande melhoria em tarefas de agente no terminal |
| SWE-bench Pro | 58.4 | 62.1 | Ganho moderado porém relevante em codificação no nível de repositório |
| FrontierSWE | 30.5 | 74.4 | Grande melhoria em engenharia de longo horizonte |
| Postura de pesos abertos | Família GLM de pesos abertos | Lançamento de pesos abertos sob MIT | Abertura semelhante, posicionamento mais forte em longo contexto |
Se o seu fluxo atual no GLM-5.1 é basicamente chat curto ou geração de código simples, a atualização pode não mudar tudo. Se seu fluxo envolve grandes repositórios, agentes de codificação multi-etapas ou execução de tarefas longas, o GLM-5.2 é um modelo muito mais relevante.
GLM-5.2 vs Claude Opus, GPT-5.5, Gemini e DeepSeek
A forma mais clara de comparar o GLM-5.2 é por tipo de tarefa:
| Tipo de tarefa | Posicionamento do GLM-5.2 |
|---|---|
| Codificação de longo horizonte | Uma das opções de pesos abertos mais fortes; próximo a modelos fechados de ponta em benchmarks selecionados |
| Raciocínio geral | Forte, mas nem sempre à frente dos principais modelos fechados |
| Uso de ferramentas | Forte desempenho em MCP-Atlas e HLE-with-tools |
| Competições de matemática | Pontuação AIME 2026 muito forte em resultados publicados |
| Visão | Não é o modelo certo; use um modelo de visão |
| Classificação barata em alto volume | Geralmente superdimensionado; use um modelo menor |
| Auto-hospedagem e personalização | Opção mais forte do que modelos fechados apenas via API |
Para equipes, a melhor resposta geralmente não é “substitua todo modelo pelo GLM-5.2”. A melhor resposta é “direcione o GLM-5.2 para as tarefas onde ele tem vantagem”. Essa é uma das razões pelas quais um provedor de API unificada como a CometAPI pode ser prático. Ela permite comparar e rotear modelos por carga de trabalho sem reconstruir cada integração.
Preços: potência acessível em escala
GLM-5.2 oferece uma economia atraente, especialmente para trabalhos de longo contexto intensivos em tokens.
- Preços de API (via Z.ai/OpenRouter/etc.): $1.40 / 1M tokens de entrada, $4.40 / 1M tokens de saída. Leitura de cache a partir de $0.26/1M em algumas rotas.
- Assinaturas do GLM Coding Plan (inclui acesso completo, sem adicional para 5.2):
- Lite: ~$10–12.60/mês (iteração leve).
- Pro: ~$30/mês.
- Max/Team: cotas maiores para uso intenso.
Exemplo de economia de custos: para uma sessão agente longa com 500K de contexto + saídas, o GLM-5.2 pode ser 4–5x mais barato do que equivalentes do Claude, ao mesmo tempo em que lida com contextos maiores de forma nativa.
Recomendação da CometAPI: acesse o GLM-5.2 (e 500+ outros modelos) por meio do endpoint unificado compatível com OpenAI da CometAPI com tarifas competitivas. Uma única chave, sem aprisionamento de fornecedor, créditos de teste no cadastro. Ideal para comparar o GLM-5.2 lado a lado com Claude/GPT em produção. Visite cometapi para integração fluida.
Janela de contexto de 1M: o recurso de destaque
O contexto de 1M é “sólido” e sem perdas na prática para trabalhos em escala de projeto — muito além do hype de marketing. Ele permite manter repositórios de médio a grande porte em contexto, reduzindo a sobrecarga de sumarização e a acumulação de erros em agentes.
Dicas para uso eficaz:
- Use o identificador glm-5.2[1m].
- Defina max tokens adequadamente; monitore em produção.
- Combine com ferramentas/MCP para busca dinâmica de dados.
Testes iniciais confirmam estabilidade acima de 200K, um ponto comum de falha de outros modelos de “longo contexto”.
Desempenho de base e benchmarks
Relatórios da Z.ai e independentes destacam as forças do GLM-5.2 em cenários de codificação e agentes. Ele mostra ganhos substantivos sobre o GLM-5.1 e resultados competitivos contra modelos fechados em tarefas de longo horizonte.
Principais benchmarks relatados (Z.ai e agregados de terceiros):
- Terminal-Bench 2.1: 81.0 (subindo do 62.0 do GLM-5.1) — Excelente para operações de terminal/agentes.
- SWE-bench Pro: 62.1 (supera o GPT-5.5 em 58.6).
- MCP-Atlas: 77.0 (perto do Claude Opus 4.8).
- Humanity’s Last Exam (com ferramentas): 54.7.
Outras lideranças: no topo ou próximo ao topo entre modelos abertos no FrontierSWE, PostTrainBench, SWE-Marathon. Forte no AIME 2026 (~99.2) e GPQA-Diamond (91.2).
Opções de acesso à API do GLM-5.2
Há duas formas comuns de acessar o GLM-5.2 a partir de uma aplicação.
Opção 1: usar Z.ai diretamente
A rota direta é usar a API oficial da Z.ai. Pode ser a escolha certa quando sua equipe deseja um relacionamento direto com o provedor do modelo, usa apenas modelos da Z.ai ou precisa de controles específicos do provedor assim que forem lançados.
A contrapartida é operacional. Se seu produto usa várias famílias de modelos, você pode precisar manter configurações de SDK separadas, fluxos de faturamento, lógica de failover, normalização de preços e convenções de observabilidade. Para um projeto de pesquisa, isso pode ser aceitável. Para um SaaS em produção, a superfície de integração pode crescer rapidamente.
Opção 2: usar GLM-5.2 via CometAPI
A CometAPI fornece acesso ao GLM-5.2 por meio de um gateway de API unificado. O benefício prático é que desenvolvedores podem chamar diferentes modelos de IA por uma única interface compatível com OpenAI em vez de construir uma integração por provedor. Você mantém seu código próximo ao padrão do SDK da OpenAI, define o nome do modelo como glm-5.2 e roteia as requisições pela CometAPI.
Isso é útil para startups e equipes de produto que desejam:
- Testar o GLM-5.2 contra outros modelos sem reconstruir o backend
- Manter uma única chave de API e uma única camada de faturamento para múltiplos modelos
- Avançar mais rápido do benchmark ao protótipo e à produção
- Implementar estratégias de fallback ou roteamento de modelos
- Comparar custo e qualidade entre provedores
- Usar padrões de requisição no estilo OpenAI
Cadastre-se em CometAPI.com para créditos de teste instantâneos e endpoints compatíveis com OpenAI que abstraem peculiaridades de provedores.
- Obtenha sua chave de API.
- Defina variáveis de ambiente (boa prática de segurança):
bash
export GLM_API_KEY="your_key_here"
export BASE_URL="https://api.cometapi.com/v1" # or direct Z.ai endpoint
Fazendo sua primeira chamada à API do GLM-5.2
Exemplo cURL (teste rápido):
bash
curl https://api.z.ai/api/paas/v4/chat/completions \
-H "Authorization: Bearer $GLM_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5.2",
"messages": [
{"role": "system", "content": "You are an expert full-stack engineer."},
{"role": "user", "content": "Write a FastAPI endpoint for user authentication with JWT."}
],
"temperature": 0.7,
"max_tokens": 2048
}'
Casos de uso comuns do GLM-5.2
GLM-5.2 é um forte candidato para fluxos em que longo contexto, raciocínio e uso de ferramentas se combinam.
| Caso de uso | Exemplo de implementação | Por que o GLM-5.2 pode se encaixar |
|---|---|---|
| Assistente de desenvolvedor | Analisar relatórios de bugs, trechos de código, logs e testes | Exige raciocínio sobre contexto técnico |
| Inteligência de documentos | Revisar contratos, políticas, sinistros ou relatórios | Entradas longas e extração estruturada |
| Agente de pesquisa | Ler fontes, comparar afirmações, produzir resumos | Beneficia de longo contexto e disciplina de citação |
| Copiloto de suporte ao cliente | Combinar histórico de tickets, docs, dados de conta e política | Precisa de recuperação mais chamadas de ferramentas |
| Assistente de produto de IA | Sintetizar feedback, especificações, dados de uso e notas de roadmap | Longo contexto e raciocínio de negócios |
| Análise de segurança | Revisar relatórios de incidentes, alertas e planos de remediação | Precisa de raciocínio cuidadoso em múltiplas etapas |
| Engenharia de vendas | Respostas técnicas a partir de docs e requisitos do cliente | Útil em ciclos B2B complexos |
O padrão comum não é “chatbot”. O padrão comum é compressão de fluxo de trabalho. O GLM-5.2 pode reduzir o tempo entre informação bruta e uma decisão útil.
Quem deve usar o GLM-5.2?
GLM-5.2 é uma forte opção para:
- Desenvolvedores construindo ferramentas de codificação com IA.
- Empresas SaaS adicionando assistentes cientes do repositório.
- CTOs avaliando alternativas de pesos abertos a modelos de codificação fechados.
- Gerentes de produto de IA testando fluxos de longo contexto.
- Empresas com planos futuros de auto-hospedagem ou controle de dados.
- Plataformas para desenvolvedores que precisam de opcionalidade de modelos.
- Equipes que trabalham com grandes documentos técnicos, SDKs ou bases de código.
É especialmente atraente quando a falha na tarefa é cara. Se o erro de um modelo causa builds quebrados, migrações ruins ou tempo de engenharia desperdiçado, o custo de usar um modelo mais forte pode se justificar rapidamente.
Quando não usar o GLM-5.2
Não padronize o GLM-5.2 para:
- Tarefas curtas e repetitivas de classificação.
- Reescrita simples de texto.
- Entendimento de imagem ou captura de tela.
- Autocomplete de baixa latência onde milissegundos importam.
- Fluxos em que um modelo menor já desempenha bem.
- Produtos que não toleram geração de longa duração.
O objetivo não é venerar a maior janela de contexto. O objetivo é resolver a tarefa com o perfil certo de qualidade, custo e latência.
Veredito final
GLM-5.2 é um dos lançamentos de modelos de pesos abertos mais importantes para equipes de engenharia de software em 2026. A combinação de contexto de 1M, fortes benchmarks em codificação, modos de raciocínio High e Max, suporte a chamadas de função e licença MIT o torna uma opção séria para agentes de codificação e fluxos de IA de longo horizonte.
Para equipes que desejam testá-lo rapidamente, a CometAPI é uma camada de acesso pragmática. Você pode chamar o GLM-5.2 por um endpoint compatível com OpenAI, compará-lo com outros modelos líderes, monitorar uso e construir uma estratégia de roteamento sem reconstruir seu stack em torno de um único provedor. Comece com uma avaliação privada pequena, meça o custo por tarefa resolvida e mova o GLM-5.2 para produção apenas onde suas forças de longo contexto claramente se pagam.
Pronto para testar o GLM-5.2 no seu próprio app? Explore GLM-5.2 no CometAPI, crie uma chave de API e execute sua primeira requisição compatível com OpenAI em minutos. Use-o em uma tarefa real de repositório, não um prompt de brinquedo, e compare o resultado com sua pilha de modelos atual.