

A Google lançou o Gemini 3.5 Flash em 19 de maio de 2026, no I/O, posicionando-o como um modelo de alta inteligência, otimizado para velocidade, com desempenho de ponta sustentado em fluxos de trabalho orientados a agentes, programação e tarefas multimodais. Ele se baseia na fundação do Gemini 3 Flash com “thinking levels” aprimorados para equilibrar qualidade, custo e latência.
Este guia abrangente cobre tudo: o que é o Gemini 3.5 Flash, seus principais recursos, desempenho detalhado em benchmarks, preços, comparações com GPT-5.5, Claude 4.7/4.6 e mais. Como um agregador líder de APIs de IA, CometAPI ajuda os desenvolvedores a acessar o Gemini 3.5 Flash (e concorrentes) com preços unificados, integração simplificada e ferramentas de otimização de custos.
O que é o Gemini 3.5 Flash?
Gemini 3.5 Flash se baseia na fundação de raciocínio do Gemini 3 Flash com “thinking levels” (minimal, low, medium/default, high) aprimorados para ajustar com precisão o trade-off qualidade–latência–custo. É um modelo nativamente multimodal que suporta texto, imagens, vídeo, áudio e documentos (incluindo PDFs), com janela de contexto de 1M tokens e até 65K tokens de saída. O recorte de conhecimento é janeiro de 2025.
Diferenciais principais em relação aos modelos Flash anteriores:
- Desempenho de ponta sustentado em tarefas orientadas a agentes, programação e de longo horizonte.
- Preservação do raciocínio: mantém automaticamente raciocínios intermediários em conversas multi-turno sem mudanças adicionais na API.
- Otimizado para escala: projetado para execução paralela com agentes, codificação iterativa e fluxos de trabalho empresariais de múltiplas etapas.
- Sem suporte a computer use (ainda), mas com fortes melhorias em uso de ferramentas e chamadas de função.
A Google o posiciona como o “modelo Flash mais inteligente” para produção, superando o anterior Gemini 3.1 Pro em muitos benchmarks de tarefas com agentes e de programação, ao mesmo tempo em que entrega velocidade de nível Flash (frequentemente >280 tokens de saída/segundo em testes).
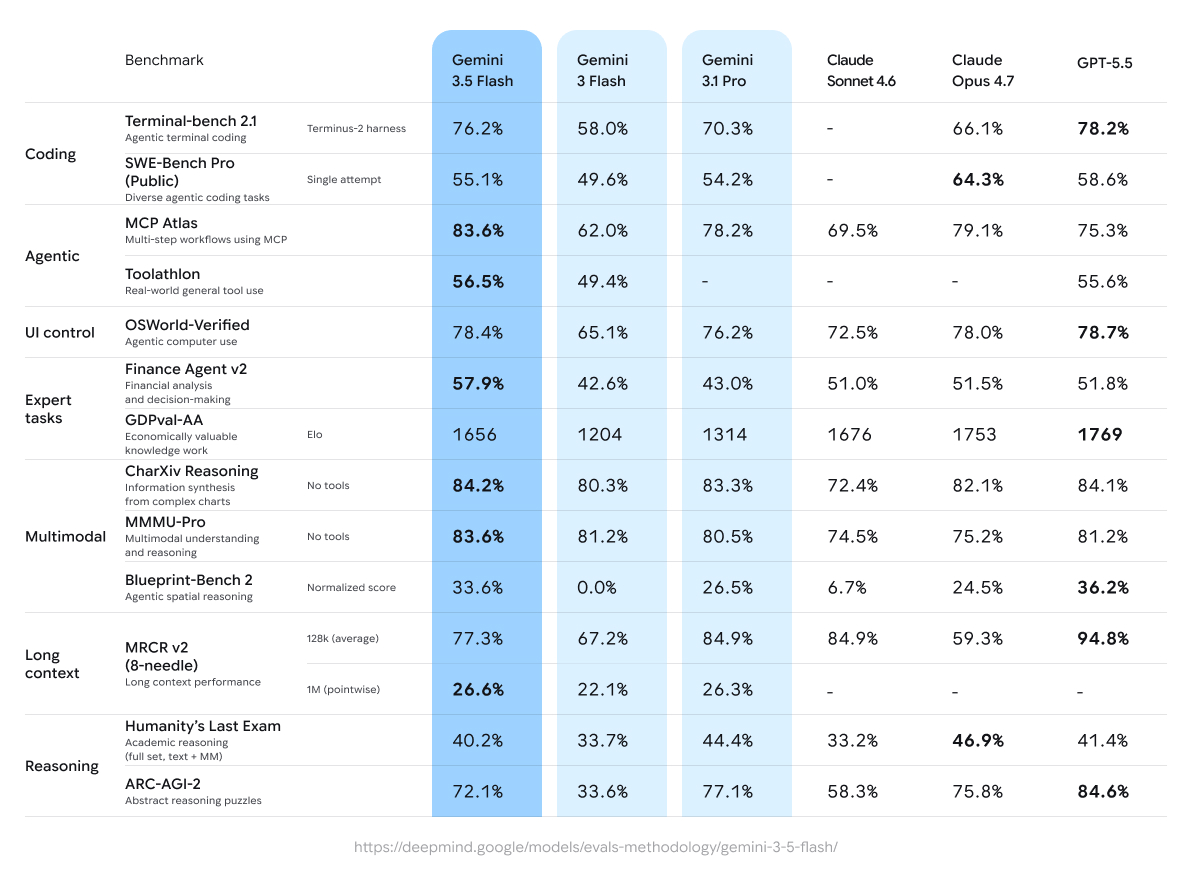
O Gemini 3.5 Flash se destaca em fluxos de trabalho com agentes e programação, com inteligência quase de nível Pro, latência e custo otimizados, alcançando pontuações como 76,2% no Terminal-bench 2.1 e 83,6% em tarefas multietapas do MCP Atlas.
Avanço no desempenho em benchmarks
Testes independentes confirmam que ele oferece desempenho de nível Pro ou melhor em tarefas de programação/com agentes com maior velocidade, embora o custo total de execução de benchmarks aumente devido ao uso de mais tokens em loops de agentes complexos e ao preço 3x superior ao de modelos Flash anteriores.
O Gemini 3.5 Flash mostra ganhos robustos sobre os predecessores, particularmente em domínios de agentes e programação. Aqui estão resultados-chave do model card da Google DeepMind e de avaliações independentes (em maio de 2026):
Benchmarks selecionados (Gemini 3.5 Flash vs. comparadores):
Programação:
- Terminal-bench 2.1 (programação com agente no terminal): 76,2% (vs. Gemini 3 Flash 58,0%, Gemini 3.1 Pro 70,3%, GPT-5.5 78,2%)
- SWE-Bench Pro (programação com agentes pública e diversa): 55,1% (vs. 49,6% do 3 Flash, 54,2% do 3.1 Pro)
Uso de ferramentas com agentes:
- MCP Atlas (fluxos multietapas): 83,6% (grande liderança)
- Toolathlon (uso de ferramentas em cenários reais): 56,5%
- Finance Agent v2: 57,9% (+15,3% sobre o 3 Flash)
Multimodal:
- CharXiv (raciocínio sobre gráficos): 84,2%
- MMMU-Pro: 83,6% (lidera muitos concorrentes)
Raciocínio e longo contexto:
- Humanity’s Last Exam: 40,2%
- ARC-AGI-2: 72,1%
- MRCR v2 (128k): 77,3%; contexto de 1M forte em 26,6% (pontual).
Índice de Inteligência de Análise Artificial: o Gemini 3.5 Flash marca 55 (alto raciocínio), +9 pontos em relação ao Gemini 3 Flash. Ele lidera a fronteira de Pareto Inteligência vs. Velocidade, com ganhos em tarefas com agentes e redução de alucinações (queda para 61% de taxa de alucinação). Atinge >280 tokens de saída/segundo, mas incorre em maior uso de tokens em loops com agentes.
Brilha em long-context (forte no MRCR v2 e 1M pontual), liderança multimodal (gráficos, documentos) e desempenho sustentado com agentes, com redução de desperdício de tokens em alguns fluxos (por exemplo, 42% melhor em benchmark de ciber com 72% menos tokens).
Equilíbrio entre velocidade e capacidades com agentes
O Gemini 3.5 Flash se destaca no trade-off entre velocidade e inteligência. Ele alcança alta vazão (>280 tokens/s) enquanto suporta comportamentos sofisticados com agentes, como implantação de subagentes, execução paralela e iteração rápida.
O esforço de “pensamento” padrão agora é medium, alterado de high no Gemini 3 Flash Preview.
Os níveis de pensamento permitem controle preciso:
- Médio (padrão): Melhor equilíbrio para a maioria das tarefas complexas de código e com agentes.
- Alto: Maximiza o raciocínio profundo para os problemas mais difíceis.
- Baixo/Mínimo: Latência ultrabaixa para consultas mais simples.
A Google relata ganhos significativos de eficiência de tokens em cenários reais com agentes (por exemplo, redução de 72% em alguns benchmarks de ciber em comparação com versões anteriores), tornando-o viável para fluxos de trabalho sustentados e de longa duração.
Trade-offs: O preço mais alto em relação aos modelos Flash anteriores leva a custos gerais maiores em cenários com agentes intensivos em tokens (custo do Índice de Inteligência 5,5x vs. Gemini 3 Flash devido a preço + uso).
Capacidades aprimoradas de agentes inteligentes
O Gemini 3.5 Flash avança a “era Gemini com agentes”. Melhorias-chave incluem:
- Loops de execução paralela com agentes: implante múltiplos subagentes para solução de problemas complexos.
- Codificação e prototipação iterativas: exploração rápida de caminhos de solução com uso dinâmico de ferramentas.
- Fluxos de trabalho de longo horizonte e multietapas: lida com processos corporativos estendidos com preservação do raciocínio.
- Melhorias no uso de ferramentas: correspondência estrita de respostas de função, respostas de função multimodais e redução de chamadas desnecessárias via melhor prompting e níveis de pensamento mais baixos. Forte em OSWorld e tarefas de UI.
Ele alimenta os novos agentes de informação da Google, pesquisas autônomas e pipelines de programação. Em testes internos, se destaca na construção de sistemas complexos e no gerenciamento de projetos de pesquisa.
Para desenvolvedores, a nova Interactions API (beta) simplifica o gerenciamento de histórico no servidor, semelhante a padrões avançados em outros ecossistemas.
Recomendação da CometAPI: use nossa API unificada para encadear o Gemini 3.5 Flash com modelos especializados (por exemplo, Claude para revisão de código profunda ou GPT para tarefas criativas) em sistemas com agentes. Nossos recursos de roteamento e fallback garantem confiabilidade e economia.
Liderança multimodal
A Google mantém a liderança em compreensão multimodal. O Gemini 3.5 Flash processa e raciocina nativamente sobre texto + imagem + vídeo + áudio + documentos. Ele lidera ou compete de perto em benchmarks como CharXiv, MMMU-Pro e tarefas de compreensão de vídeo.
Casos de uso: síntese de gráficos/dados, análise de vídeo, chamadas de função multimodais (por exemplo, processar imagens em respostas de ferramentas) e agentes de mídia rica. Isso o torna ideal para aplicações em e-commerce, criação de conteúdo, visualização científica e mais.
Preços: Quanto custa o Gemini 3.5 Flash?
Preços da API do Gemini (por 1M de tokens, taxas globais aproximadas):
- Entrada (texto/imagem/vídeo/áudio): $1.50
- Saída: $9.00
- Cache de contexto: $0.15 (economias significativas para prompts repetidos)
Isso representa um aumento de ~3x sobre o Gemini 3 Flash Preview ($0.50/$3), mas permanece competitivo pelo salto de capacidade. Aproxima-se do preço do Gemini 3.1 Pro ($2/$12) oferecendo melhor velocidade para muitas cargas.
Isso representa um aumento de ~3x sobre o Gemini 3 Flash Preview ($0.50/$3), mas permanece competitivo pelo salto de capacidade. Aproxima-se do preço do Gemini 3.1 Pro ($2/$12) oferecendo melhor velocidade para muitas cargas.
Camada gratuita: acesso limitado via Google AI Studio/app Gemini; pago para produção.
Vantagem CometAPI: acesse a API do Gemini 3.5 Flash junto com 100+ modelos com tarifas competitivas, análises de uso e ferramentas de otimização para minimizar gastos com tokens. Nossa plataforma frequentemente oferece melhor preço efetivo via roteamento inteligente e batching. Os preços de API costumam ser 20% inferiores aos oficiais.
Gemini 3.5 Flash vs. GPT-5.5, Claude 4.7/4.6 e outros
Pontos fortes do Gemini 3.5 Flash:
- Equilíbrio velocidade + agentes: inferência mais rápida que a maioria dos modelos de fronteira enquanto reduz a lacuna de inteligência.
- Multimodal e longo contexto: contexto nativo de 1M e liderança em visão.
- Custo para volume: mais barato por token que Claudes/GPTs de topo para muitas cargas, especialmente com cache.
- Ecossistema Google: integração fluida com Search, Workspace, Cloud.
Onde os concorrentes levam vantagem:
- GPT-5.5 frequentemente lidera em raciocínio bruto (por exemplo, ARC-AGI) e pode ter capacidades criativas/gerais mais fortes.
- Claude Opus 4.7/Sonnet 4.6 se destacam em codificação cuidadosa (SWE-Bench mais alto em alguns casos) e escrita/segurança nuançada.
- A eficiência de tokens varia; loops com agentes podem tornar o 3.5 Flash mais caro no geral.
Comparação em alto nível (métricas aproximadas/selecionadas; sempre verifique os rankings mais recentes):
| Benchmark / Métrica | Gemini 3.5 Flash | GPT-5.5 | Claude Opus 4.7 / Sonnet 4.6 | Gemini 3.1 Pro | Observações |
|---|---|---|---|---|---|
| Terminal-bench 2.1 (coding) | 76,2% | 78,2% | ~66% | 70,3% | Programação com agentes |
| MCP Atlas (Agentic) | 83,6% | 75,3% | 79,1% / 69,5% | 78,2% | Fluxos multietapas |
| GDPval-AA (Conhecimento c/ agentes) | 1656 Elo | 1769 | 1753 | 1314 | Valor econômico |
| MMMU-Pro (Multimodal) | 83,6% | 81,2% | ~75% | 80,5% | Forte liderança Gemini |
| Índice de Inteligência (AA) | 55 | Alto (varia) | Competitivo | Inferior | Pareto vel./intel. |
| Velocidade (tokens/s) | >280 | Inferior | Variável | Mais lento | Vantagem Flash |
| Preço entrada/saída ($/1M) | 1.50 / 9.00 | Maior | Maior (esp. Opus) | 2/12 | Fronteira custo-efetiva |
| Janela de contexto | 1M | Competitiva | Forte | 1M+ | Todos em nível fronteira |
Resumo dos trade-offs:
- O Gemini 3.5 Flash vence em velocidade + multimodalidade + eficiência com agentes em escala.
- O GPT-5.5 frequentemente supera em picos de raciocínio/codificação bruta.
- O Claude 4.7 Opus se destaca em codificação cuidadosa e de alta confiabilidade, porém com maior custo/latência.
O Gemini frequentemente lidera ou empata em suítes multimodais e específicas de agentes, sendo mais rápido e mais acessível para uso em alto volume.
Como acessar e integrar o Gemini 3.5 Flash
Acesse via:
- App Gemini / Google AI Studio
- API do Gemini (
gemini-3.5-flash) - Google Cloud Vertex AI / Enterprise Agent Platform
- Agregadores de terceiros para flexibilidade multi-fornecedor.
Recomendação da CometAPI: para aplicações de produção no Cometapi.com, integre uma única vez com uma chave de API para acessar o Gemini 3.5 Flash (e 500+ modelos da OpenAI, Anthropic, xAI etc.) com preço efetivo 20–40% menor, sem lock-in do fornecedor e fácil troca de modelos.
Benefícios para seus projetos:
- Teste o Gemini 3.5 Flash contra o GPT-5.5 ou o Claude 4.7 instantaneamente alterando o nome do modelo.
- Faturamento unificado, roteamento de fallback e latência otimizada.
- Ideal para apps com agentes que precisam de confiabilidade entre provedores.
- Cadastro gratuito de chave de API com limites de teste generosos.
A integração é direta com SDKs oficiais ou o endpoint unificado da CometAPI — perfeito para escalar programação
Casos de uso e melhores práticas
- Automação com agentes: construa sistemas multiagente robustos para pesquisa, análise de dados ou suporte ao cliente.
- Programação e desenvolvimento: prototipagem iterativa, depuração e geração de pipeline completo no Antigravity ou em IDEs.
- Aplicações multimodais: análise de imagem/vídeo, compreensão de gráficos, geração de conteúdo.
- Fluxos corporativos: processos de longo horizonte com controle de custos via cache e níveis de pensamento.
Dicas: use o histórico completo da conversa para preservação do raciocínio. Comece com medium. Otimize prompts para reduzir chamadas de ferramentas. Monitore o uso de tokens para eficiência de custos.
Limitações e considerações
- O aumento de preço exige otimização cuidadosa para apps de alto volume.
- Ainda sem computer use (acompanhe atualizações).
- Avaliações de segurança mostram desempenho sólido com melhorias de tom, embora métricas automatizadas variem.
- A redução de alucinações é notável, mas sempre valide saídas críticas.
- Aumento de preço: maior que modelos Flash anteriores; otimize com níveis de pensamento e cache.
- Recorte de conhecimento: janeiro de 2025 — use ferramentas de grounding/Search para eventos atuais.
Conclusão: Vale a pena o Gemini 3.5 Flash?
Sim — para desenvolvedores e empresas que priorizam velocidade, confiabilidade com agentes, capacidades multimodais e desempenho escalável. Ele empurra a fronteira de Pareto, tornando a IA de ponta mais acessível para workloads de produção.
Pronto para construir? Acesse a CometAPI hoje para testar o Gemini 3.5 Flash com outros modelos de ponta em um único dashboard. Otimize sua stack de IA, reduza custos e lance mais rápido.