

Google/DeepMind کے Gemini 3 Pro اور Anthropic کے Claude Sonnet 4.5 دونوں 2025 کے دور کے فلیگ شپ ماڈلز ہیں، جو agentic، طویل المدت، ٹول استعمال کرنے والے ورک فلوز کے لیے بہتر بنائے گئے ہیں — اور دونوں کوڈنگ پر خاصا زور دیتے ہیں۔ دعویٰ کردہ مضبوطیاں مختلف ہیں: Google، Gemini 3 Pro کو ایک عمومی مقصد کے multimodal reasoner کے طور پر پیش کرتا ہے جو agentic coding میں بھی نمایاں ہے، جبکہ Anthropic، Sonnet 4.5 کو دنیا کا بہترین coding/agent ماڈل قرار دیتا ہے، خاص طور پر مضبوط edit/tool کامیابی اور طویل عرصے تک چلنے والے agents کے ساتھ۔
مختصر جواب پہلے: 2025 کے آخر میں سافٹ ویئر انجینئرنگ کے کاموں کے لیے دونوں ماڈلز اعلیٰ درجے کے ہیں۔ Claude Sonnet 4.5 کچھ خالص software-engineering benchmark metrics میں معمولی برتری رکھتا ہے، جبکہ Google کا Gemini 3 Pro (Preview) زیادہ وسیع، multimodal، agentic پاور ہاؤس ہے—خاص طور پر جب آپ کو visual context، tool use، long-context work اور گہرے agent workflows کی فکر ہو۔
میں اس وقت دونوں ماڈلز استعمال کرتا ہوں، اور development environment میں ان میں سے ہر ایک کے مختلف فوائد ہیں۔ اب میں اس مضمون میں ان کا موازنہ کروں گا۔
Gemini 3 Pro صرف Google AI Ultra subscribers اور paid Gemini API users کے لیے دستیاب ہے۔ تاہم، اچھی خبر یہ ہے کہ CometAPI، ایک all-in-one AI platform کے طور پر، Gemini 3 Pro کو integrate کر چکا ہے، اور آپ اسے مفت آزما سکتے ہیں۔
Gemini 3 Pro Preview کیا ہے اور اس کی نمایاں خصوصیات کیا ہیں؟
جائزہ
Gemini 3 Pro (ابتدائی طور پر gemini-3-pro-preview کے طور پر دستیاب) Google/DeepMind کا Gemini 3 family میں تازہ ترین “frontier” LLM ہے۔ اسے ایک high-reasoning، multimodal ماڈل کے طور پر position کیا گیا ہے، جو agentic workflows کے لیے optimize کیا گیا ہے (یعنی ایسے ماڈلز جو tools استعمال کر سکتے ہیں، subagents کو orchestrate کر سکتے ہیں، اور external resources کے ساتھ interact کر سکتے ہیں)۔ یہ مضبوط reasoning، multimodality (images، video frames، PDFs)، اور اندرونی “thinking” depth کے لیے واضح API controls پر زور دیتا ہے۔
اہم خصوصیات (developer-facing)
- Agentic tool use: built-in function calling اور tools (code execution، web grounding، file & URL context، terminal/tool use)۔
- Thinking / Chain-of-Thought support: multi-step planning کے لیے “thinking” primitives اور internal thought signatures تاکہ multi-step reasoning کو زیادہ واضح بنایا جا سکے۔
- Multimodal input/output: text، images، audio، video، اور structured outputs کے ساتھ long context handling۔
- Code execution tool & IDE integrations: ایک hosted code execution tool اور IDEs میں integrations، نیز collaborative autonomous coding کے لیے نیا Google Antigravity agentic IDE۔ Antigravity اس وقت public preview میں ہے۔
- High/extended thinking controls (
thinking_levelparameter) تاکہ آپ latency اور گہرے internal reasoning کے درمیان توازن قائم کر سکیں۔high، Gemini 3 Pro کے لیے default ہے۔ - Granular multimodal controls (
media_resolution) تاکہ image/video fidelity بمقابلہ cost کو tune کیا جا سکے — مفید جب آپ چاہتے ہیں کہ ماڈل screenshots میں چھوٹا متن پڑھے یا frames کا تجزیہ کرے۔
کوڈنگ کے لیے Gemini 3 Pro کہاں نمایاں ہے
- Agentic development: editor/terminal/browser میں multi-step tasks کو orchestrate کرنا۔ Antigravity کا artifact system + Gemini کے tools اسے بڑے feature work اور automation کے لیے بہترین بناتے ہیں۔
- Visual + code combos: screenshots سے UI bugs ٹھیک کرنا، UI test harnesses بنانا، یا design images کو code میں تبدیل کرنا کیونکہ image-to-code understanding مضبوط ہے۔
Claude Sonnet 4.5 کیا ہے اور اس کی اہم خصوصیات کیا ہیں؟
Claude Sonnet 4.5، Anthropic کی 2025 کی ریلیز ہے جسے Anthropic coding، agentic workflows اور “using computers” (tools، browsers، terminals، spreadsheets وغیرہ کو control کرنا) کے لیے اپنا مضبوط ترین ماڈل قرار دیتا ہے۔ یہ بہتر edit capability، tool success، extended thinking، long-running agent coherence (demonstrations میں 30+ گھنٹے autonomous task execution)، اور پچھلی generations کے مقابلے میں کم code-editing error rates پر زور دیتا ہے۔ Anthropic، Sonnet 4.5 کو اپنا “best coding model” قرار دیتا ہے، جس میں edit reliability اور long-horizon task coherence میں بڑے gains ہیں۔
اہم خصوصیات (developer-facing)
- Real-world engineering benchmarks پر اعلیٰ coding accuracy: Anthropic state-of-the-art SWE-bench Verified scores رپورٹ کرتا ہے اور edit error rates اور tool-based agent success میں بڑی بہتری کا دعویٰ کرتا ہے۔
- Agentic and computer-use improvements: Sonnet 4.5 کو multiple tools (bash، file editing، browser automation) چلانے اور Claude Agent SDK کے ذریعے subagents کو orchestrate کرنے کے لیے ڈیزائن کیا گیا ہے۔ Anthropic اپنی internal evaluations میں “30+ hours” کے continuous multi-step work کو نمایاں کرتا ہے۔
- Large context windows: زیادہ تر customers کے لیے default 200k tokens، جبکہ higher-tier orgs کے لیے beta میں 1M-token context دستیاب ہے (وہی 1M capability جو Gemini preview میں فراہم کرتا ہے)۔
- Code execution tool & file APIs: in-product اور API tools محفوظ code execution، file creation/editing، اور test-run loops کی اجازت دیتے ہیں۔
کوڈنگ کے لیے Sonnet 4.5 کہاں نمایاں ہے
- خالص software-engineering benchmarks اور structured code tasks (unit test generation، repository-wide refactors) جہاں ماڈل کی algorithmic rigor اور long-horizon stability اہم ہو۔
- Code-first CLIs اور “code assistant” flows جیسے Claude Code، جہاں tight terminal integration اور repository scanning out of the box فراہم کی جاتی ہے۔
فوری تقابلی جدول
| پہلو | Gemini 3 Pro (Preview) | Claude Sonnet 4.5 |
|---|---|---|
| ماڈل / ریلیز اسٹیٹس | gemini-3-pro-preview — Google / DeepMind frontier model (preview)۔ Released Nov 2025 (preview)۔ | claude-sonnet-4-5 — Anthropic Sonnet-class frontier model (GA / announced Sep 29, 2025)۔ |
| ہدفی positioning (coding & agents) | reasoning + multimodal + agentic workflows پر زور دینے والا general-purpose frontier model؛ Google کے top coding/agent model کے طور پر position کیا گیا۔ | coding، long-horizon agenting اور computer use کے لیے specialized (Anthropic کا “best for coding & complex agents”)۔ |
| اہم developer features | گہرے internal reasoning کے لیے thinking_level control؛ built-in Google tool integrations (Search grounding، code execution، file/URL context)؛ text+image workflows کے لیے dedicated image variant۔ | Agent SDKs، VS Code integration (Claude Code)، file & code-execution tools، long-horizon agent improvements (واضح طور پر multi-hour runs کے لیے tested)۔ iterative edit/run/test workflows اور checkpointing پر زور۔ |
| Context window (input / output) | gemini-3-pro-preview کے لیے 1,000,000 tokens input / 64k tokens output | 1,000,000 tokens input / 64k tokens output |
| Pricing (published baseline) | <200k tier کے لیے $2 / $12 per 1M tokens (input / output)؛ >200k کے لیے زیادہ rates (docs میں $4 / $18 for >200k)۔ | Anthropic published baseline: Sonnet 4.5 کے لیے $3 / $15 per 1M tokens (input / output)؛ |
| Multimodal capability (vision/video/audio) | مکمل multimodal support: text، images، audio، video frames، configurable image/video resolution parameters کے ساتھ؛ dedicated gemini-3-pro-image-preview۔ coding UIs/screenshots کے لیے image OCR/visual extraction پر مضبوط زور۔ | vision (text+image) inputs کو support کرتا ہے اور coding workflows کو support کرنے کے لیے vision استعمال کرتا ہے؛ بنیادی زور agentic integration پر ہے (image generation parity کے بجائے agent flows کے اندر visual context استعمال کرنا)۔ |
| Long-horizon agentic performance & persistence | explicit multi-step internal reasoning کے لیے “Thinking” primitives؛ مضبوط math/reasoning اور multimodal deep reasoning۔ پیچیدہ algorithmic tasks کو توڑنے میں اچھا۔ heavy single-response reasoning + multimodal analysis کے لیے بہترین۔ | Anthropic long-horizon agentic coherence پر زور دیتا ہے — Anthropic internal tests رپورٹ کرتا ہے جن میں Sonnet 4.5 نے 30+ hours تک coherent multi-step tool use برقرار رکھا اور prior models کے مقابلے میں continuous agent stability بہتر کی۔ persistent automation اور CI-style agent workflows کے لیے اچھا fit۔ |
| coding کے لیے output quality (edits, tests, reliability) | بہت مضبوط single-shot reasoning + code generation؛ Google tooling کے ذریعے code چلانے کے built-in tools؛ vendor claims کے مطابق algorithmic benchmarks پر اعلیٰ کارکردگی۔ جب workflow visual specs + code کو mix کرتا ہو تو عملی برتری۔ | iterative edit→run→test loops کے لیے ڈیزائن کیا گیا؛ Sonnet 4.5 بہتر “patching” reliability (rejection sampling / scoring techniques تاکہ robust patches منتخب کیے جا سکیں) اور iterative developer workflows کو support کرنے والے tooling (checkpoints، tests) کو نمایاں کرتا ہے۔ |
ان کی architectures اور core capabilities کا موازنہ کیسے کیا جا سکتا ہے؟
Architecture اور design intent (high level)
Gemini 3 Pro: ایک multimodal، general-purpose foundation model کے طور پر پیش کیا گیا ہے، جس میں “thinking” اور tool use کے لیے واضح engineering کی گئی ہے: design گہرے reasoning، video/audio understanding، اور built-in function calling اور code execution environments کے ذریعے agentic orchestration پر زور دیتا ہے۔ Google، Gemini 3 Pro کو family کا “most intelligent” ماڈل قرار دیتا ہے، جو code سے آگے وسیع کاموں کے لیے optimize کیا گیا ہے (اگرچہ agentic coding ایک ترجیح ہے)۔
Claude Sonnet 4.5: خاص طور پر agentic workflows اور code کے لیے optimize کیا گیا ہے: Anthropic instruction-following، tool reliability، edit/correction proficiency، اور long horizon state management پر زور دیتا ہے۔ engineering focus destructive یا hallucinated edits کو کم سے کم کرنا اور مضبوط real-world computer interactions کو ممکن بنانا ہے۔
نتیجہ: Gemini 3 Pro کو ایک top generalist کے طور پر پیش کیا جاتا ہے جسے multimodal reasoning اور agentic integration پر بہت آگے بڑھایا گیا ہے؛ Sonnet 4.5 کو coding اور agentic tool use کے specialist کے طور پر پیش کیا جاتا ہے جس میں بہتر edit/correction guarantees موجود ہیں۔
Tooling اور integrations
- Gemini: built-in Google toolset، بشمول Search grounding، file search، code execution، اور first-class image/video parameters؛ internal compute/latency tradeoffs کو control کرنے کے لیے
thinking_levelparameter۔ Google infra میں گہرا integration اسے اُن teams کے لیے آسان بناتا ہے جو پہلے ہی Google Cloud پر ہیں۔ - Claude: robust agent SDK اور stable long-run computation پر زور (Sonnet کی reported 30+ hour coherence)۔ Anthropic code execution، file APIs، اور Claude Code اور VS Code extension میں ایک نیا “checkpoints” editing UX بھی فراہم کرتا ہے — ایسی خصوصیات جو iterative coding workflows کو حقیقی طور پر بہتر بناتی ہیں۔
Technical specifications اور benchmarks کیا کہتے ہیں؟
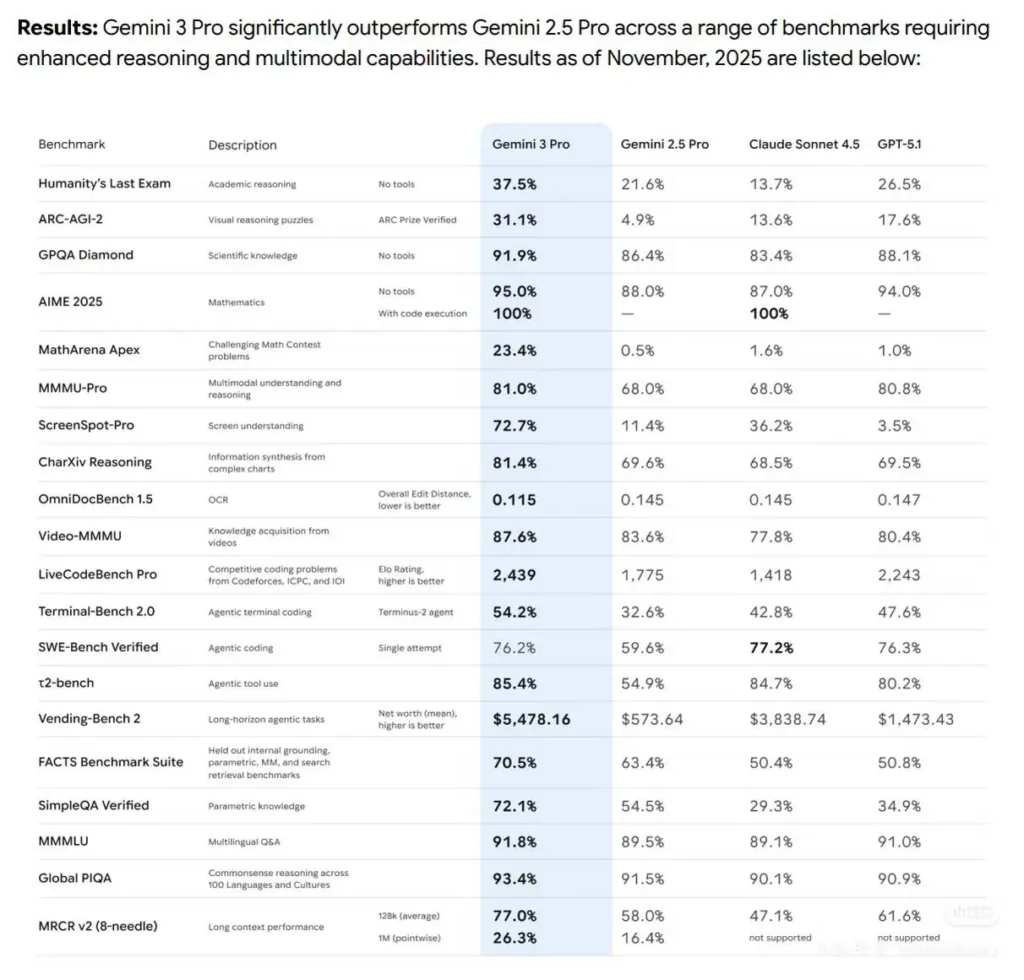
Benchmarks evaluator اور configuration کے لحاظ سے تھوڑے مختلف ہوتے ہیں (single attempt بمقابلہ multi-attempt، tool access، extended-thinking settings)۔ ذیل میں coding ability کے benchmark data کا تجزیہ ہے:
SWE-bench Verified (real-world software engineering tests)
Claude Sonnet 4.5 (Anthropic reported): 77.2% (200k thinking budget؛ 1M config میں 78.2%)۔ Anthropic parallel attempts/rejection sampling استعمال کرتے ہوئے 82.0% high-compute score بھی رپورٹ کرتا ہے۔
Gemini 3 Pro (DeepMind reporting / related leaderboards): SWE-bench پر ~76.2% single-attempt (vendor table)۔ Public leaderboards مختلف ہوتے ہیں (Gemini اور Sonnet کے margins کم فرق سے بدلتے رہتے ہیں)۔
Terminal-Bench اور Agentic tasks
Gemini 3 Pro: Terminal/agentic bench numbers (vendor table) مضبوط performance دکھاتے ہیں (مثلاً vendor table میں Terminal-Bench 54.2%)، جو Sonnet کی agentic strengths کے مقابلے میں مسابقتی ہیں۔
Sonnet 4.5: agentic tool orchestration میں نمایاں ہے (Anthropic، OSWorld اور Terminal-style benchmarks پر substantial gains رپورٹ کرتا ہے اور زیادہ دیر تک continuous task performance کو نمایاں کرتا ہے)۔
نتیجہ: code-understanding اور code-generation benchmarks پر دونوں ماڈلز بہت قریب ہیں؛ Sonnet 4.5 کو بعض software-engineering verification suites میں معمولی برتری حاصل ہے (Anthropic کے published numbers کے مطابق)، جبکہ Gemini 3 Pro نہایت مسابقتی ہے اور اکثر multimodal اور بعض coding-competition style leaderboards میں آگے ہوتا ہے۔ ہمیشہ exact evaluation configuration (tool access، context-size، thinking budgets) کے ساتھ validation کریں، کیونکہ یہ settings scores کو نمایاں طور پر بدل دیتی ہیں۔
ان کی multimodal capabilities کا موازنہ کیسے کیا جا سکتا ہے؟
Vision اور image handling
- Gemini 3 Pro: image/video
media_resolutionکے ساتھ fine-grained multimodal controls (فی image/frame low/medium/high token budgets)، image generation/editing (الگ image preview model)، اور OCR/visual detail کے لیے واضح guidance۔ یہ Gemini کو خاص طور پر اُس وقت مضبوط بناتا ہے جب coding tasks میں screenshots، UI mockups، یا video frames پڑھ کر code تیار یا modify کرنا ہو۔ - Claude Sonnet 4.5: text+image multimodality کو support کرتا ہے اور Anthropic کے product integrations (Claude apps) visual workflows فراہم کرتے ہیں؛ Sonnet 4.5 میں بنیادی توجہ raw image synthesis parity کے بجائے visual context کو agentic workflows میں integrate کرنے پر ہے۔
جب multimodality کوڈنگ کے لیے اہم ہو
اگر آپ کا workflow بہت زیادہ UI screenshots، design specs in images، یا video walkthroughs پر انحصار کرتا ہے جنہیں model نے analyze کر کے code تیار یا modify کرنا ہو، تو Gemini کے dedicated image resolution controls اور image-generation variant ایک عملی فائدہ بن سکتے ہیں۔ اگر آپ کی pipeline agent-driven automation ہے (clicking around، commands چلانا، files edit کرنا across tools)، تو Claude کا agent SDK اور code-execution tooling first-class ہیں۔
Advanced reasoning اور long-horizon planning — کون بہتر ہے؟
Sonnet 4.5: endurance اور alignment
Sonnet 4.5 پیچیدہ multi-stage tasks (planning، research، litigation drafting، long-running code tasks) میں 30 گھنٹے سے زیادہ تک coherent work برقرار رکھ سکتا ہے۔ یہ endurance، اور Anthropic کی alignment پر زور، Sonnet کو end-to-end automation کے لیے ایک پرکشش انتخاب بناتا ہے، جہاں model کو goals کا track رکھنا اور محفوظ رویہ برقرار رکھنا ضروری ہو۔
Gemini 3 Pro: deep reasoning + agent orchestration
Gemini 3 Pro ایک “Deep Think” variant اور multi-step planning کے لیے richer internal thinking APIs متعارف کراتا ہے، Google کے agentic IDE کے ساتھ۔ عملی طور پر اس کا مطلب یہ ہے کہ Gemini tools (editor، shell، web) کے درمیان agentic steps کو plan بھی کر سکتا ہے اور execute بھی۔ اگر آپ کے automation میں external tool access کے ساتھ artifact creation درکار ہو، تو Gemini کا integrated agentic tooling (Antigravity) ایک مضبوط فائدہ ہے۔ نوٹ: Deep Think، latency کے بدلے depth فراہم کرتا ہے۔
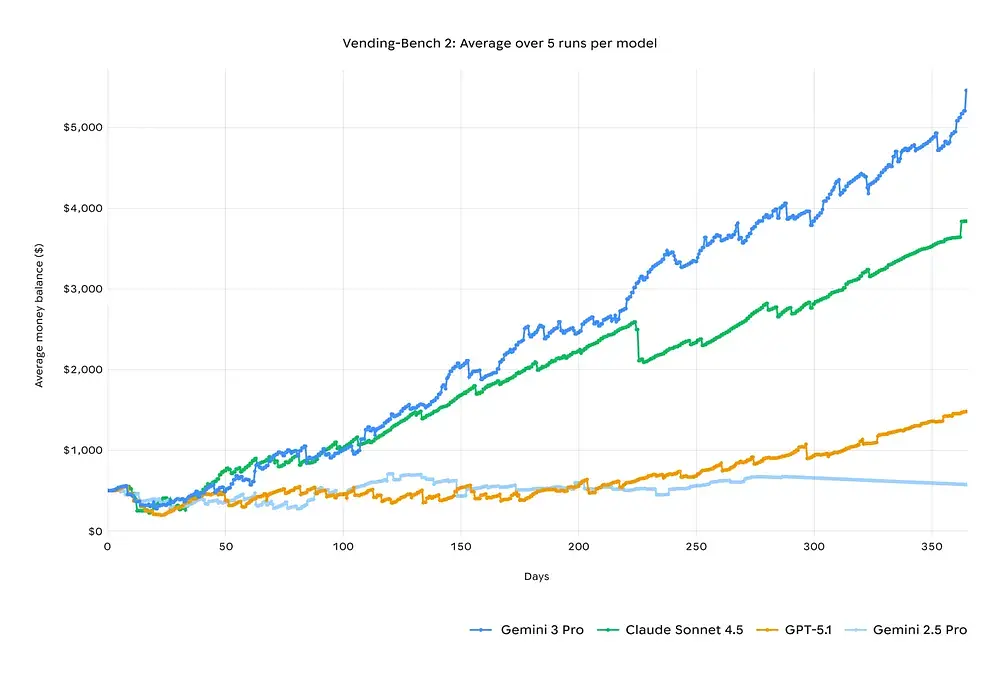
Long-Horizon Planning Comparison: Vending-Bench 2
“Vending-Bench 2” simulation test میں، Gemini 3 نے Claude 4.5 سے بہتر کارکردگی دکھائی، ایک virtual company کو پورے سال چلاتے ہوئے اور منافع میں رہتے ہوئے۔ short-term tests میں Gemini 3 Pro اور Claude 4 Sonnet کا data ملتا جلتا تھا، لیکن طویل testing periods میں فرق زیادہ نمایاں ہو گیا۔
عملی فرق
- single-shot high-reasoning tasks کے لیے (complex algorithmic debugging، code میں شامل deep logical proofs)، Gemini کا
thinking_levelاور Deep Think زیادہ single-response depth کا وعدہ کرتے ہیں۔ - long-duration, tool-driven automation کے لیے (persistent agents جو بہت سے commands چلاتے ہیں، tests لکھتے ہیں، iterate کرتے ہیں، اور state manage کرتے ہیں)، Claude Sonnet 4.5 کی long-horizon focus اور agent SDK نمایاں فرق پیدا کرتے ہیں۔
Developer use کے لیے API access اور pricing کا موازنہ کیسے کیا جا سکتا ہے؟
Gemini 3 Pro (Google) — access اور pricing
- Access: Gemini 3 Pro preview، Google AI Studio اور Vertex AI (model garden) کے ذریعے دستیاب ہے۔ SDKs میں Python/JS/Go وغیرہ کے لیے google-genai شامل ہے، نیز آسان migration کے لیے OpenAI-compat layers، REST endpoints، اور function calling / code execution tools۔ Antigravity ایک IDE surface فراہم کرتا ہے جو preview میں Gemini 3 Pro استعمال کرتا ہے۔
- Price: Google docs پر listed preview pricing: <200k tier کے لیے $2 / $12 per 1M tokens (input / output)؛ >200k کے لیے زیادہ rates (docs میں examples $4 / $18 for >200k دکھاتے ہیں)۔
Claude Sonnet 4.5 — access اور pricing
- APIs & SDKs: Anthropic Claude API، Claude Agent SDK برائے agentic workflows، file APIs، اور code-execution tools فراہم کرتا ہے (native VS Code extension، Claude Code improvements، اور “checkpoint” feature)۔
- Price: default 200k-token context window، enterprise کے لیے beta میں 1M-token context؛ pricing $3 / $15 per 1M tokens (بالترتیب input/output)
ایک developer کے طور پر، آپ کو ماڈل کا انتخاب اپنی ضروریات اور اس کی خصوصیات کی بنیاد پر کرنا چاہیے، صرف سب سے سستا ہونے کی بنیاد پر نہیں۔ اگر ایک task کو دو ماڈلز handle کر سکتے ہوں، تو context کی بنیاد پر فیصلہ کریں۔
اگر آپ ایک ساتھ دو ماڈلز استعمال کرنا چاہتے ہیں، تو میں CometAPI کی سفارش کرتا ہوں، جو Gemini 3 Pro Preview API اور Claude Sonnet 4.5 API دونوں فراہم کرتا ہے، اور official price کے 20% پر priced ہے۔
| Gemini 3 Pro Preview | GPT-5.1 | |
| Input Tokens | $1.60 | $2.4.00 |
| Output Tokens | $9.60 | $12.00 |
آخری خیالات
Gemini 3 Pro (Preview) اور Claude Sonnet 4.5 دونوں 2025 کے آخر میں coding assistants کے لیے state-of-the-art انتخاب ہیں۔ Sonnet 4.5 مخصوص software-engineering verification benchmarks اور long-horizon tasks میں stamina کے لحاظ سے Gemini سے معمولی آگے ہے، جبکہ Gemini 3 Pro زیادہ مضبوط multimodal understanding اور گہرا agentic tooling لاتا ہے جو editor/terminal/browser environments میں execute کر سکتا ہے۔ درست انتخاب اس بات پر منحصر ہے کہ آپ کی بنیادی ضرورت pure code reasoning and verification (Sonnet) ہے، یا multimodal, agentic, tool-augmented development (Gemini)۔ enterprise-grade deployment کے لیے، بہت سی teams معقول طور پر hybrid approach اپنائیں گی، اور development workflow کے کسی خاص stage کے لیے وہی model استعمال کریں گی جو زیادہ مضبوط ہو۔
Developers، CometAPI کے ذریعے Gemini 3 Pro Preview API اور Claude Sonnet 4.5 API تک رسائی حاصل کر سکتے ہیں۔ آغاز کے لیے، CometAPI کے Playground میں model capabilities دریافت کریں اور تفصیلی ہدایات کے لیے API guide دیکھیں۔ رسائی سے پہلے، براہِ کرم یقینی بنائیں کہ آپ CometAPI میں login کر چکے ہیں اور API key حاصل کر چکے ہیں۔ CometAPI integration میں مدد کے لیے official price سے کہیں کم قیمت پیش کرتا ہے۔
Ready to Go?→ Gemini 3 pro اور GPT-5.1 models کا مفت trial !
اگر آپ AI سے متعلق مزید tips، guides اور news جاننا چاہتے ہیں تو ہمیں VK، X اور Discord پر follow کریں!