

I det hastigt udviklende AI-landskab skiller GLM-5.2 fra Z.ai (Zhipu AI) sig ud som en formidabel open-weights-model, optimeret til agent-baseret kodning, langsigtede opgaver og produktionspålidelighed. Med et brugbart kontekstvindue på 1M tokens, to ræsonneringstilstande (High og Max) og stærk ydeevne til en brøkdel af prisen for lukkede frontier-modeller er den hurtigt ved at blive det foretrukne valg for udviklere, der bygger autonome agenter, IDE-integrationer og komplekse software engineering-arbejdsgange.
Uanset om du er solo-udvikler, der prototyper agenter, en CTO, der vurderer omkostningseffektiv skalering, eller en AI-produktchef, der integrerer multimodale ræsonneringsevner i SaaS, giver det store fordele at mestre GLM-5.2-API'et.
Hvad er GLM-5.2?
GLM-5.2 er Z.ai’s (Zhipu AI) nyeste flagskibs open-weights Mixture-of-Experts (MoE)-model, udgivet i midten af juni 2026. Med cirka 753 milliarder samlede parametre (omkring 40B aktive pr. token), et stabilt kontekstvindue på 1 million tokens, MIT-licens og stærk ydeevne på langsigtet kodning og agentiske opgaver positionerer den sig som et konkurrencedygtigt alternativ til lukkede frontier-modeller som GPT-5.5, Claude Opus 4.8 og Gemini-varianter—til en brøkdel af prisen for mange arbejdsbelastninger.
GLM-5.2-arkitektur og tekniske specifikationer
GLM-5.2 bygger videre på GLM-familien med centrale forbedringer til langsigtet arbejde.
- Parameters: ~753B samlet i MoE-design (aktive parametre ~40B pr. token). Dette giver enorm kapacitet med effektiv inferens.
- Context Window: 1,048,576 tokens (1M). Maks. output typisk op til 128K–131K tokens.
- Precision: BF16 (med FP8-varianter til lettere deployment).
- Key Innovation – IndexShare: Genbruger en enkelt indexer på tværs af grupper af sparse attention-lag, hvilket reducerer FLOPs pr. token med op til 2,9x ved 1M kontekst. Dette gør lang-kontekst-inferens praktisk uden eksploderende omkostninger eller latenstid.
- Reasoning Modes: "High" (balanceret) og "Max" (dybest, anbefalet til kodning). Ræsonnering kan deaktiveres for simple opgaver.
- Modalities: Primært tekst/kode (ingen indbygget vision bekræftet i basisudgaven).
- License: MIT – fuldt åbent for download, modificering og kommerciel brug.
Denne åbenhed og effektivitet gør GLM-5.2 ideel for teams, der prioriterer dataprivatliv, tilpasning eller omkostningskontrol.
GLM-5.2 vs GLM-5.1
| Area | GLM-5.1 | GLM-5.2 | Practical difference |
|---|---|---|---|
| Context window | Around 200K on common hosted routes | 1M | GLM-5.2 is much better suited for whole-project context |
| Reasoning effort | Less flexible | High and Max | Better control over cost, latency and quality |
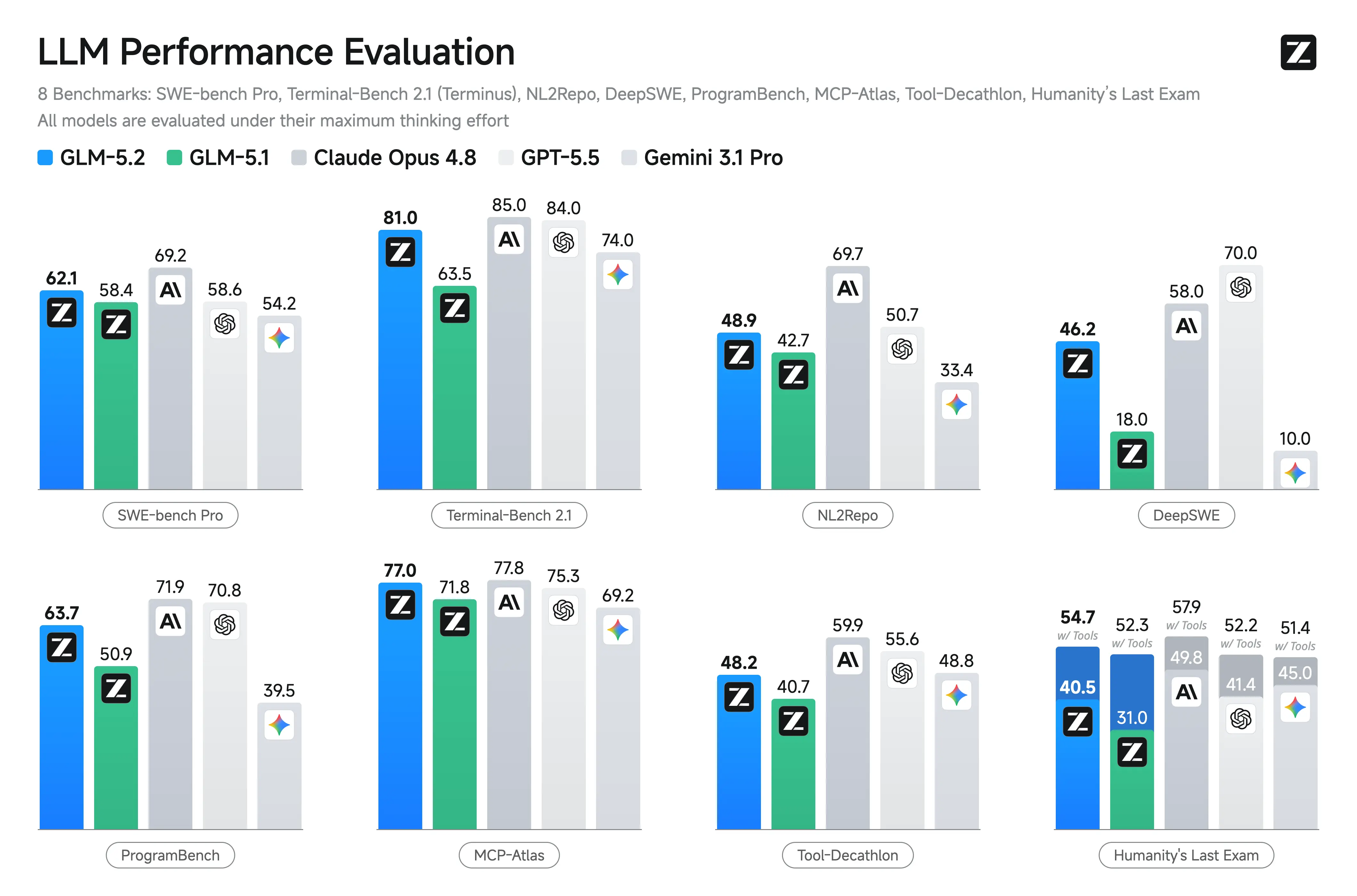
| Terminal Bench 2.1 | 63.5 in the published table | 81.0 | Major improvement in terminal-based agent tasks |
| SWE-bench Pro | 58.4 | 62.1 | Moderate but meaningful repo-level coding gain |
| FrontierSWE | 30.5 | 74.4 | Very large long-horizon engineering improvement |
| Open-weight posture | Open-weight GLM family | Open-weight MIT release | Similar openness, stronger long-context positioning |
Hvis din nuværende GLM-5.1-arbejdsgang mest er korte chats eller basal kodegenerering, ændrer opgraderingen måske ikke alt. Hvis din arbejdsgang involverer store repositories, multi-trins kodeagenter eller langvarig opgaveudførelse, er GLM-5.2 en langt mere relevant model.
GLM-5.2 vs Claude Opus, GPT-5.5, Gemini og DeepSeek
Den reneste måde at sammenligne GLM-5.2 på er efter opgavetype:
| Task type | GLM-5.2 position |
|---|---|
| Long-horizon coding | One of the strongest open-weight options; near frontier closed models on selected benchmarks |
| General reasoning | Strong, but not always ahead of top closed models |
| Tool use | Strong MCP-Atlas and HLE-with-tools performance |
| Math competitions | Very strong AIME 2026 score in published results |
| Vision | Not the right model; use a vision model |
| Low-cost high-volume classification | Usually overpowered; use a smaller model |
| Self-hosting and customization | Stronger option than closed API-only models |
For teams er det bedste svar som regel ikke "erstat alle modeller med GLM-5.2." Det bedre svar er "styr GLM-5.2 mod de opgaver, hvor den har en fordel." Det er en af grundene til, at en samlet API-udbyder som CometAPI kan være praktisk. Det lader dig sammenligne og rute modeller efter arbejdsbelastning uden at genopbygge hver integration.
Priser: Overkommelig kraft til skalering
GLM-5.2 tilbyder overbevisende økonomi, især til token-tunge lang-kontekst-arbejdsbelastninger.
- API Pricing (via Z.ai/OpenRouter/etc.): $1.40 / 1M input tokens, $4.40 / 1M output tokens. Cache-læsning ned til $0.26/1M på nogle ruter.
- GLM Coding Plan-abonnementer (inkluderer fuld adgang, ingen ekstra for 5.2):
- Lite: ~$10-12.60/måned (let iteration).
- Pro: ~$30/måned.
- Max/Team: Højere kvoter til tung brug.
Cost Savings Example: For en lang agentisk session med 500K kontekst + output kan GLM-5.2 være 4-5x billigere end tilsvarende Claude, samtidig med at den håndterer større kontekster nativt.
CometAPI Recommendation: Få adgang til GLM-5.2 (og 500+ andre modeller) via CometAPI’s samlede OpenAI-kompatible endpoint til konkurrencedygtige priser. Én nøgle, ingen leverandørlåsning, testkreditter ved tilmelding. Ideelt til at sammenligne GLM-5.2 side om side med Claude/GPT i produktion. Besøg cometapi for problemfri integration.
1M-kontekstvindue: Den fremtrædende funktion
1M-konteksten er "solid" og i praksis tabsløs til arbejde i projektstørrelse—langt ud over marketinghype. Den gør det muligt at holde hele mellemstore til store repositories i kontekst, hvilket reducerer opsummeringsoverhead og fejlakkumulation i agenter.
Tips til effektiv brug:
- Brug glm-5.2[1m]-identifikatoren.
- Indstil max tokens passende; overvåg i produktion.
- Kombinér med tools/MCP til dynamisk datahentning.
Tidlige tests bekræfter stabilitet over 200K, et almindeligt fejlpunkt for andre "lang-kontekst"-modeller.
Grundlæggende ydeevne og benchmarks
Z.ai og uafhængige rapporter fremhæver GLM-5.2’s styrker i kodning og agentiske scenarier. Den viser markante gevinster over GLM-5.1 og konkurrencedygtige resultater mod lukkede modeller på langsigtede opgaver.
Nøglebenchmarks (Z.ai og tredjepartsaggregater):
- Terminal-Bench 2.1: 81.0 (op fra GLM-5.1’s 62.0) – Fremragende til terminal-/agentoperationer.
- SWE-bench Pro: 62.1 (ligger foran GPT-5.5 på 58.6).
- MCP-Atlas: 77.0 (nær Claude Opus 4.8).
- Humanity’s Last Exam (med værktøjer): 54.7.
Andre styrker: Topper eller nær toppen blandt åbne modeller på FrontierSWE, PostTrainBench, SWE-Marathon. Stærk på AIME 2026 (~99.2) og GPQA-Diamond (91.2).
GLM-5.2 API-adgangsmuligheder
Der er to almindelige måder at få adgang til GLM-5.2 fra en applikation.
Mulighed 1: Brug Z.ai direkte
Den direkte vej er at bruge den officielle Z.ai-API. Dette kan være det rigtige valg, når dit team ønsker et direkte forhold til modeludbyderen, kun bruger Z.ai-modeller eller har brug for leverandørspecifikke kontroller, så snart de frigives.
Kompromiset er operationelt. Hvis dit produkt bruger flere modelfamilier, kan du få behov for at vedligeholde separate SDK-konfigurationer, faktureringsflows, failover-logik, prisnormalisering og observabilitetskonventioner. Til et forskningsprojekt kan det være acceptabelt. Til en produktions-SaaS-platform kan integrationsfladen vokse hurtigt.
Mulighed 2: Brug GLM-5.2 via CometAPI
CometAPI giver adgang til GLM-5.2 via en samlet API-gateway. Den praktiske fordel er, at udviklere kan kalde forskellige AI-modeller gennem ét OpenAI-kompatibelt interface i stedet for at bygge én integration pr. udbyder. Du holder din kode tættere på OpenAI SDK-mønstret, angiver modelnavnet til glm-5.2, og ruter forespørgsler gennem CometAPI.
Dette er nyttigt for startups og produktteams, der vil:
- Teste GLM-5.2 mod andre modeller uden at genopbygge deres backend
- Holde én API-nøgle og ét faktureringslag for flere modeller
- Komme hurtigere fra benchmark til prototype til produktion
- Implementere model-fallback eller -ruteringsstrategier
- Sammenligne pris og kvalitet på tværs af udbydere
- Bruge velkendte OpenAI-lignende forespørgselsmønstre
Tilmeld dig på CometAPI.com for øjeblikkelige testkreditter og OpenAI-kompatible endpoints, der abstraherer udbyderforskelle.
- Hent din API-nøgle.
- Sæt miljøvariabler (sikkerhedsbedste praksis):
export GLM_API_KEY="your_key_here"
export BASE_URL="https://api.cometapi.com/v1" # or direct Z.ai endpoint
Sådan foretager du dit første GLM-5.2 API-kald
cURL-eksempel (hurtig test):
bash
curl https://api.z.ai/api/paas/v4/chat/completions \
-H "Authorization: Bearer $GLM_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5.2",
"messages": [
{"role": "system", "content": "You are an expert full-stack engineer."},
{"role": "user", "content": "Write a FastAPI endpoint for user authentication with JWT."}
],
"temperature": 0.7,
"max_tokens": 2048
}'
Almindelige GLM-5.2-anvendelser
GLM-5.2 er en stærk kandidat til arbejdsgange, hvor lang kontekst, ræsonnering og værktøjsbrug kombineres.
| Use case | Example implementation | Why GLM-5.2 may fit |
|---|---|---|
| Developer assistant | Analyze bug reports, code snippets, logs, and tests | Requires reasoning across technical context |
| Document intelligence | Review contracts, policies, claims, or reports | Long inputs and structured extraction |
| Research agent | Read sources, compare claims, produce summaries | Benefits from long context and citation discipline |
| Customer support copilot | Combine ticket history, docs, account data, and policy | Needs retrieval plus tool calling |
| AI product manager assistant | Synthesize feedback, specs, usage data, and roadmap notes | Long context and business reasoning |
| Security analysis | Review incident reports, alerts, and remediation plans | Needs careful multi-step reasoning |
| Sales engineering | Generate technical answers from docs and customer requirements | Useful for complex B2B sales cycles |
Det fælles mønster er ikke "chatbot." Det fælles mønster er arbejdsgangskomprimering. GLM-5.2 kan reducere tiden mellem rå information og en nyttig beslutning.
Hvem bør bruge GLM-5.2?
GLM-5.2 passer godt til:
- Udviklere, der bygger AI-kodeværktøjer.
- SaaS-virksomheder, der tilføjer repository-bevidste assistenter.
- CTO’er, der evaluerer open-weights-alternativer til lukkede kodningsmodeller.
- AI-produktchefer, der tester lang-kontekst-arbejdsgange.
- Enterprise-organisationer med fremtidige self-hosting- eller datakontrolbehov.
- Udviklerplatforme, der har brug for model-valgfrihed.
- Teams, der arbejder med store tekniske dokumenter, SDK’er eller kodebaser.
Den er særligt attraktiv, når opgaven er dyr at fejle. Hvis en models fejl medfører ødelagte builds, dårlige migrationer eller spildt udviklertid, kan omkostningen ved at bruge en stærkere model hurtigt retfærdiggøres.
Hvornår du ikke bør bruge GLM-5.2
Brug ikke GLM-5.2 som standard til:
- Korte og repetitive klassifikationsopgaver.
- Enkel tekstomskrivning.
- Billede- eller skærmbilledeforståelse.
- Lav-latens autoudfyldning, hvor millisekunder tæller.
- Arbejdsgange, hvor en mindre model allerede performer godt.
- Produkter, der ikke kan tolerere langvarig generering.
Målet er ikke at tilbede det største kontekstvindue. Målet er at løse opgaven med den rette profil for kvalitet, pris og latenstid.
Konklusion
GLM-5.2 er en af de vigtigste open-weights AI-modeludgivelser for software engineering-teams i 2026. Kombinationen af 1M kontekst, stærke kodningsbenchmarks, High- og Max-ræsonneringstilstande, funktionkald-understøttelse og MIT-licens gør den til en seriøs mulighed for kodeagenter og langsigtede AI-arbejdsgange.
For teams, der vil prøve den hurtigt, er CometAPI et pragmatisk adgangslag. Du kan kalde GLM-5.2 via et OpenAI-kompatibelt endpoint, sammenligne den med andre førende modeller, overvåge forbrug og bygge en ruteringsstrategi uden at genopbygge din stack omkring én udbyder. Start med en lille privat evaluering, mål pris pr. løst opgave, og bring kun GLM-5.2 i produktion, hvor dens lang-kontekst-styrker tydeligt betaler sig.
Klar til at teste GLM-5.2 i din egen app? Udforsk GLM-5.2 på CometAPI, opret en API-nøgle, og kør din første OpenAI-kompatible forespørgsel på få minutter. Brug den til en reel repository-opgave, ikke en legetøjsprompt, og sammenlign resultatet med din nuværende modelstack.