Technische Spezifikationen von GLM-5.2
| Element | GLM-5.2 |
|---|---|
| Anbieter | Zhipu AI |
| Veröffentlichungsdatum | 13. Juni 2026 |
| Modelltyp | Open-Weight Mixture-of-Experts (MoE) LLM |
| Gesamtparameter | ~744B |
| Aktive Parameter | ~40B pro Token |
| Kontextfenster | 1.000.000 Tokens |
| Maximale Ausgabe | 131.072 Tokens |
| Reasoning-Modi | High, Max |
| Lizenz | MIT |
| Hauptfokus | Agentenbasiertes Coding, Software Engineering, langfristiges Schlussfolgern |
| API-Verfügbarkeit | Z.ai-Plattform und kompatible Anbieter |
| Offene Gewichte | Ja |
GLM-5.2 ist das neueste Flaggschiffmodell aus Zhipu AIs GLM-Familie. Anders als allgemeine Spitzenmodelle ist GLM-5.2 in erster Linie als coding-first und agentenbasiertes Modell positioniert, das für Software Engineering auf Repository-Ebene, autonome Workflows und extrem lang kontextuelles Reasoning ausgelegt ist. Die herausragende Fähigkeit ist ein natives Kontextfenster mit 1 Million Tokens, was es zu einem der größten öffentlich verfügbaren Kontextfenster unter Open-Weight-Modellen macht.
Hauptfunktionen von GLM-5.2
- 1M-Token-Kontextfenster für gesamte Repositories, umfangreiche Dokumentationssammlungen und agentenbasierte Workflows über mehrere Sitzungen.
- Coding-first-Optimierung mit Fokus auf Refactoring, Debugging, Codegenerierung und Aufgaben im Software Engineering.
- Unterstützung agentenbasierter Workflows für Tools wie Claude Code, Cline, Roo Code, OpenCode und ähnliche Coding-Agenten.
- Open-Weight-Release unter MIT-Lizenz, ermöglicht Self-Hosting und Fine-Tuning.
- Zwei Reasoning-Modi (High und Max) erlauben Abwägungen zwischen Latenz und Tiefe des Schlussfolgerns.
- Große MoE-Architektur mit ca. 744B Gesamtparametern bei Aktivierung von nur ~40B pro Token für Effizienz.
Benchmark-Leistung von GLM-5.2
Zhipu veröffentlichte zum Start keine umfassenden offiziellen Benchmark-Ergebnisse, was direkte Benchmarking-Vergleiche unsicherer macht als bei Modellen wie GPT-5 oder Claude. Mehrere Branchenberichte vermerken das Fehlen unabhängig validierter Benchmark-Veröffentlichungen.
| Benchmark | Gemeldeter Wert |
|---|---|
| Terminal-Bench 2.1 | 81.0 |
| SWE-Bench Pro | 62.1 |
| NL2Repo | 48.9 |
| AIME 2026 | 99.2 |
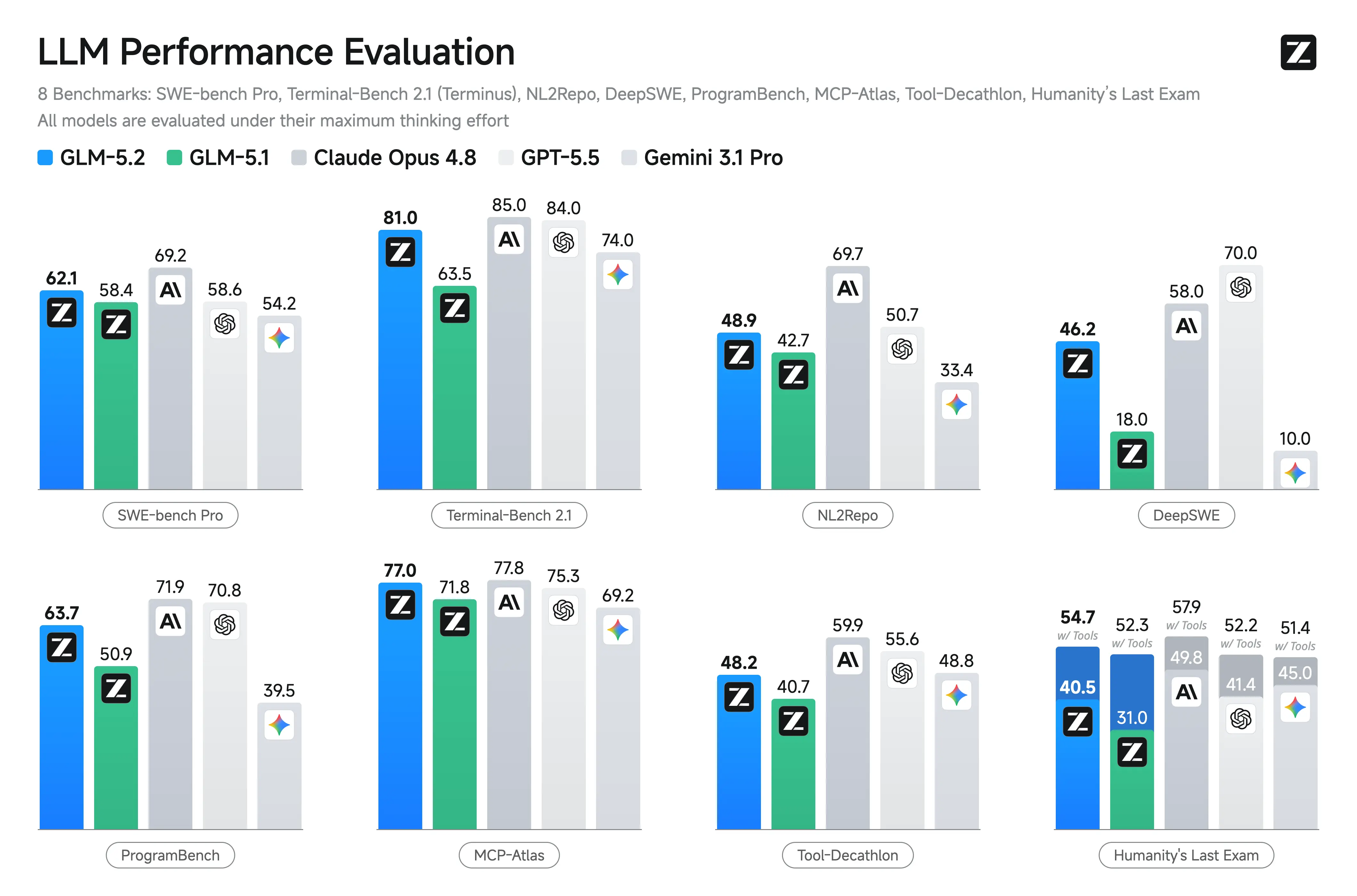
GLM-5.2 vs GLM-5.1 vs Claude Opus 4.8
| Spezifikation | GLM-5.2 | GLM-5.1 | Claude Opus 4.8 |
|---|---|---|---|
| Veröffentlichungsdatum | 2026-06-13 | 2026 | 2026 |
| Kontextfenster | 1,000,000 | ~200,000 | 1,000,000 |
| Offene Gewichte | Ja (MIT) | Ja | Nein |
| Reasoning-Modi | High, Max | Standard | Extended Thinking |
| Gesamtparameter | 744B | 744B | Nicht offengelegt |
| Aktive Parameter | 40B | 40B | Nicht offengelegt |
| Offizielle Benchmark-Daten | Nicht veröffentlicht | Zur Einführung veröffentlicht | Veröffentlicht |
Die primär dokumentierten Verbesserungen von GLM-5.2 gegenüber GLM-5.1 sind die Erweiterung auf ein 1M-Token-Kontextfenster und die Einführung wählbarer Reasoning-Modi High und Max. Zum Start veröffentlichte Z.ai keine offiziellen Ergebnisse für SWE-Bench, LiveCodeBench, HumanEval oder ähnliche Benchmarks, weshalb Leistungsvergleiche mit Claude Opus 4.8, GPT-5, DeepSeek oder Qwen-Modellen unbestätigt bleiben.
Im Vergleich zu anderen offenen Modellen liegt GLM-5.2s Hauptunterscheidungsmerkmal in der Kombination aus sehr großem Kontextfenster, Spezialisierung auf Coding und MIT-Lizenzierung. Die stärkste Anziehungskraft liegt im Software Engineering auf Repository-Ebene, weniger in allgemeinen Chat-Anwendungen.
Warum GLM-5.2 über CometAPI nutzen?
CometAPI ermöglicht Entwicklern, GLM-5.2 über dieselbe Schnittstelle zu integrieren, die für Dutzende führender KI-Modelle verwendet wird.
Vorteile sind:
- Einheitliche Authentifizierung über mehrere Anbieter hinweg
- OpenAI-kompatible API-Integration
- Vereinfachte Abrechnung und Nutzungsverwaltung
- Schnelle Experimente mit alternativen Modellen
- Einfaches Wechseln zwischen Coding-, Reasoning-, Bild-, Audio- und Video-Modellen
- Reduzierter Vendor-Lock-in für Produktivsysteme
Ob Sie eine KI-IDE, einen internen Engineering-Assistenten oder eine Enterprise-Automatisierungsplattform aufbauen: CometAPI minimiert den Integrationsaufwand bei gleichzeitiger Wahrung der Flexibilität.
So greifen Sie auf die GLM-5.2-API auf CometAPI zu
Starten Sie mit unserem Produkt in nur wenigen einfachen Schritten...
Schritt 1: Registrieren Sie Ihren GLM-5.2-API-Schlüssel
Erstellen Sie ein Konto auf Kie.ai und navigieren Sie zum API-Dashboard, um Ihren GLM-5.2-API-Schlüssel zu generieren. Dieser Schlüssel authentifiziert alle Ihre Anfragen und gewährt Ihnen sofortigen Zugriff auf die vollen Fähigkeiten der GLM-5.2-API, einschließlich des 1M-Token-Kontextfensters und 128k Ausgabetokens.
Schritt 2: Senden Sie Anfragen an die GLM-5.2-API
Verwenden Sie Ihren GLM-5.2-API-Schlüssel, um POST-Anfragen an den Kie.ai-Endpunkt zu senden. Übergeben Sie Ihren Prompt, setzen Sie Modellparameter wie Effort-Level und maximale Tokens, und die GLM-5.2-API verarbeitet Ihre Anfrage — von Codegenerierung über Dokumentenanalyse bis hin zur agentenbasierten Tool-Nutzung.
Schritt 3: Ergebnisse abrufen und GLM-5.2-API integrieren
Die GLM-5.2-API liefert strukturierte Antworten, einschließlich Antworttext, Anweisungen zum Aufrufen von Tools und Metadaten zur Token-Nutzung. Sie unterstützt sowohl standardmäßig synchrone Antworten als auch Echtzeit-Streaming über Server-Sent Events (SSE), wenn stream: true konfiguriert ist. Der Endpunkt lässt sich leicht in Ihre bestehenden Workflows integrieren, indem Sie Standard-HTTP-Clients oder OpenAI-kompatible SDKs verwenden und Anfragen über url(//api.cometapi.com/v1) mit Ihrem Bearer Token leiten.