

Google hat Gemini 3.5 Flash am 19. Mai 2026 auf der I/O veröffentlicht, und positioniert es als ein hochintelligentes, geschwindigkeitsoptimiertes Modell für nachhaltige Spitzenleistung in agentischen Workflows, Programmierung und multimodalen Aufgaben. Es baut auf der Grundlage von Gemini 3 Flash auf und bietet verbesserte „thinking levels“, um Qualität, Kosten und Latenz auszugleichen.
Dieser umfassende Leitfaden deckt alles ab: was Gemini 3.5 Flash ist, seine Hauptfunktionen, detaillierte Benchmark-Performance, Preise, Vergleiche mit GPT-5.5, Claude 4.7/4.6 und mehr. Als führender AI-API-Aggregator hilft CometAPI Entwicklerinnen und Entwicklern, Gemini 3.5 Flash (und Wettbewerber) mit einheitlicher Preisgestaltung, vereinfachter Integration und Tools zur Kostenoptimierung zu nutzen.
Was ist Gemini 3.5 Flash?
Gemini 3.5 Flash baut auf der Gemini-3-Flash-Reasoning-Grundlage auf mit verbesserten „thinking levels“ (minimal, low, medium/default, high), um den Trade-off zwischen Qualität, Latenz und Kosten feinabzustimmen. Es ist ein nativ multimodales Modell, das Text, Bilder, Video, Audio und Dokumente (einschließlich PDFs) unterstützt, mit einem 1M-Token-Kontextfenster und bis zu 65K Ausgabetokens. Der Wissensstand endet im Januar 2025.
Wesentliche Unterschiede zu früheren Flash-Modellen:
- Sustained frontier performance bei agentischen, Coding- und Long-horizon-Aufgaben.
- Thought preservation: Hält automatisch Zwischenüberlegungen über mehrfache Dialogrunden hinweg fest, ohne zusätzliche API-Änderungen.
- Optimized for scale: Entwickelt für parallele agentische Ausführung, iterative Programmierung und mehrstufige Enterprise-Workflows.
- No computer use support (noch nicht), aber starke Verbesserungen bei Tool-Nutzung und Function Calling.
Google bezeichnet es als das „intelligenteste Flash-Modell“ für den Produktionseinsatz, das das vorherige Gemini 3.1 Pro in vielen agentischen und Coding-Benchmarks übertrifft und gleichzeitig Flash-Level-Geschwindigkeit liefert (in Tests häufig >280 Ausgabetokens/Sekunde).
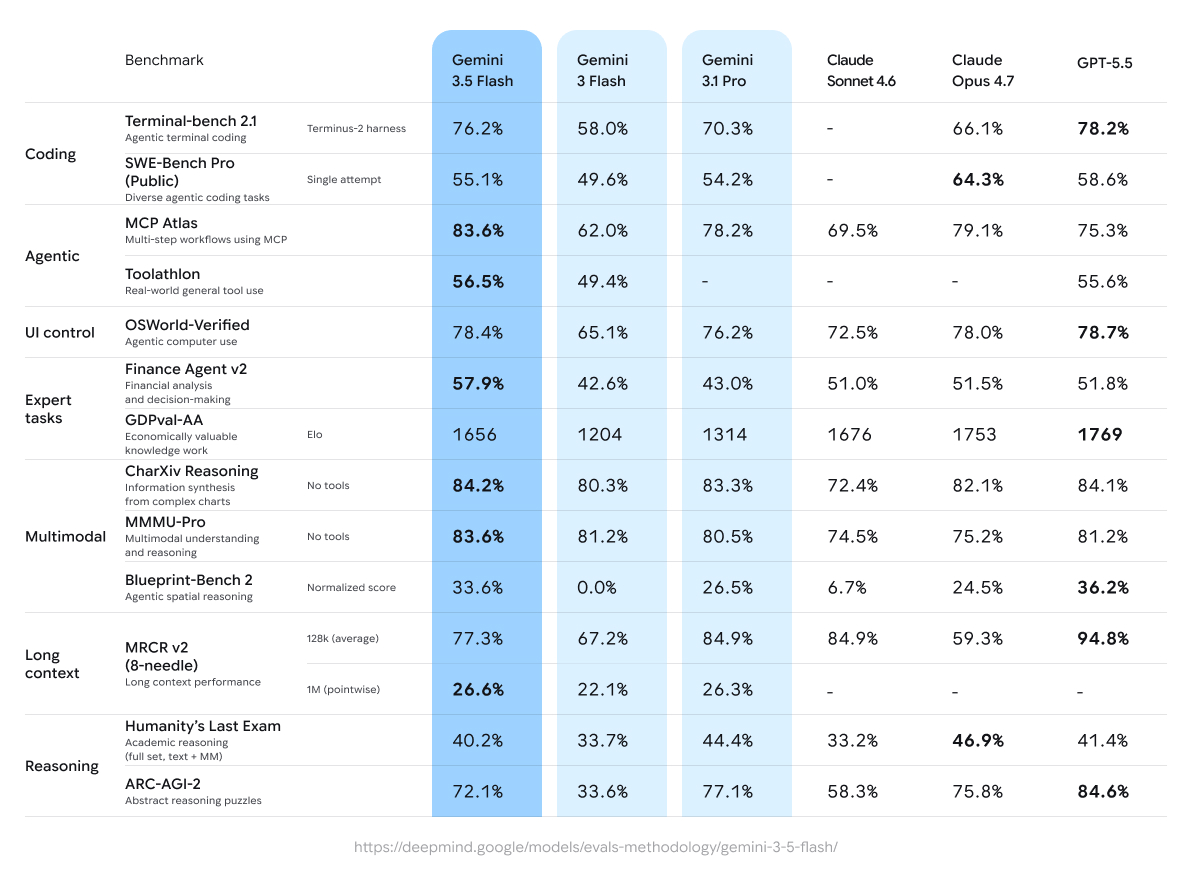
Gemini 3.5 Flash glänzt in agentischen Workflows und beim Coding mit nahezu Pro-Intelligenz bei optimierter Latenz und Kosten und erzielt Werte wie 76,2 % auf Terminal-bench 2.1 und 83,6 % bei mehrstufigen Aufgaben auf MCP Atlas.
Durchbruch bei der Benchmark-Performance
Unabhängige Tests bestätigen, dass es bei Coding/agentischen Aufgaben Leistung auf Pro-Niveau oder besser bei höherer Geschwindigkeit liefert, wobei die Gesamtkosten der Benchmark-Läufe aufgrund von mehr Tokens in komplexen Agent-Loops und des 3-fachen Preisanstiegs gegenüber früheren Flash-Modellen steigen.
Gemini 3.5 Flash zeigt starke Zugewinne gegenüber seinen Vorgängern, insbesondere in den Bereichen Agentik und Coding. Hier sind zentrale Ergebnisse aus der Model Card von Google DeepMind und unabhängigen Bewertungen (Stand Mai 2026):
Ausgewählte Benchmarks (Gemini 3.5 Flash vs. Vergleichsmodelle):
Programmierung:
- Terminal-bench 2.1 (agentisches Terminal-Coding): 76,2 % (vs. Gemini 3 Flash 58,0 %, Gemini 3.1 Pro 70,3 %, GPT-5.5 78,2 %)
- SWE-Bench Pro (öffentlich, diverse agentische Programmierung): 55,1 % (vs. 49,6 % für 3 Flash, 54,2 % für 3.1 Pro)
Agentische Tool-Nutzung:
- MCP Atlas (mehrstufige Workflows): 83,6 % (deutliche Führung)
- Toolathlon (allgemeine Tool-Nutzung in der Praxis): 56,5 %
- Finance Agent v2: 57,9 % (großes +15,3 % gegenüber 3 Flash)
Multimodal:
- CharXiv (Diagramm-Reasoning): 84,2 %
- MMMU-Pro: 83,6 % (führt viele Wettbewerber an)
Reasoning & langer Kontext:
- Humanity’s Last Exam: 40,2 %
- ARC-AGI-2: 72,1 %
- MRCR v2 (128k): 77,3 %; 1M-Kontext stark mit 26,6 % punktweise.
Artificial Analysis Intelligence Index: Gemini 3.5 Flash erzielt 55 (hohes „Thinking“), 9 Punkte mehr als Gemini 3 Flash. Es führt die Pareto-Grenze von Intelligenz vs. Geschwindigkeit an, mit Zugewinnen in agentischen Aufgaben und reduzierten Halluzinationen (bis auf 61 % Halluzinationsrate). Es erreicht >280 Ausgabetokens/Sekunde, verursacht jedoch durch agentische Loops höheren Tokenverbrauch.
Es glänzt bei langem Kontext (starkes MRCR v2 und 1M punktweise), führt multimodal (Charts, Dokumente) und liefert nachhaltige agentische Performance mit reduziertem Tokenverschwendung in einigen Workflows (z. B. 42 % besser auf Cyber-Benchmark bei 72 % weniger Tokens).
Balance zwischen Geschwindigkeit und agentischen Fähigkeiten
Gemini 3.5 Flash überzeugt im Trade-off aus Geschwindigkeit und Intelligenz. Es erreicht hohen Durchsatz (>280 Tokens/s) und unterstützt zugleich ausgefeilte agentische Verhaltensweisen wie Sub-Agent-Deployment, parallele Ausführung und schnelle Iteration.
Der standardmäßige Denkaufwand ist jetzt medium, geändert von high in Gemini 3 Flash Preview.
Thinking Levels ermöglichen präzise Steuerung:
- Medium (default): Beste Balance für die meisten komplexen Coding- und agentischen Aufgaben.
- High: Maximiert tiefes Reasoning für die schwierigsten Probleme.
- Low/Minimal: Ultraniedrige Latenz für einfachere Anfragen.
Google meldet signifikante Token-Effizienzgewinne in realen agentischen Szenarien (z. B. 72 % Reduktion in einigen Cyber-Benchmarks gegenüber früheren Versionen), was es für nachhaltige, lang laufende Workflows geeignet macht.
Trade-offs: Höherer Preis als frühere Flash-Modelle führt in tokenintensiven agentischen Szenarien zu gestiegenen Gesamtkosten (5,5x Intelligence-Index-Kosten vs. Gemini 3 Flash aufgrund von Preisgestaltung + Nutzung).
Erweiterte Fähigkeiten intelligenter Agents
Gemini 3.5 Flash treibt die „agentic Gemini era“ voran. Wichtige Verbesserungen umfassen:
- Parallele agentische Ausführungsschleifen: Einsatz mehrerer Sub-Agents für komplexe Problemlösung.
- Iteratives Coding und Prototyping: Schnelle Exploration von Lösungswegen mit dynamischer Tool-Nutzung.
- Langfristige mehrstufige Workflows: Handhabt erweiterte Enterprise-Prozesse mit Thought Preservation.
- Tool-Nutzungsverbesserungen: Striktes Funktionsantwort-Matching, multimodale Funktionsantworten und weniger unnötige Aufrufe durch besseres Prompting und niedrigere Thinking Levels. Stark bei OSWorld- und UI-Aufgaben.
Es treibt Googles neue Informations-Agents, autonome Recherche und Coding-Pipelines an. In internen Tests überzeugt es beim Aufbau komplexer Systeme und der Verwaltung von Forschungsprojekten.
Für Entwicklerinnen und Entwickler vereinfacht die neue Interactions API (beta) die serverseitige Historienverwaltung, ähnlich fortgeschrittenen Mustern in anderen Ökosystemen.
CometAPI Empfehlung: Nutzen Sie unsere einheitliche API, um Gemini 3.5 Flash mit spezialisierten Modellen zu verketten (z. B. Claude für tiefgehende Code-Reviews oder GPT für kreative Aufgaben) in agentischen Systemen. Unsere Routing- und Fallback-Funktionen sorgen für Zuverlässigkeit und Kosteneinsparungen.
Multimodale Führungsrolle
Google behauptet die Führungsrolle in multimodalem Verständnis. Gemini 3.5 Flash verarbeitet und begründet nativ über Text + Bild + Video + Audio + Dokumente. Es führt oder konkurriert eng auf Benchmarks wie CharXiv, MMMU-Pro und Videoverständnis-Aufgaben.
Anwendungsfälle: Chart-/Datensynthese, Videoanalyse, multimodales Function Calling (z. B. Verarbeitung von Bildern in Tool-Antworten) und Rich-Media-Agents. Dies macht es ideal für Anwendungen in E-Commerce, Content-Erstellung, wissenschaftlicher Visualisierung und mehr.
Preise: Was kostet Gemini 3.5 Flash?
Gemini-API-Preise (pro 1M Tokens, ungefähre globale Preise):
- Input (Text/Bild/Video/Audio): $1.50
- Output: $9.00
- Context Caching: $0.15 (signifikante Einsparungen bei wiederholten Prompts)
Dies entspricht einer ~3-fachen Erhöhung gegenüber Gemini 3 Flash Preview ($0.50/$3), bleibt aber wettbewerbsfähig angesichts des Fähigkeitssprungs. Es nähert sich der Preisgestaltung von Gemini 3.1 Pro ($2/$12), bietet jedoch für viele Workloads bessere Geschwindigkeit.
Enterprise/Agent Platform-Tarife können je nach Volumenrabatten und Add-ons variieren. Zwischengespeicherte Eingaben und effizientes Prompting (niedrigere Thinking Levels, optimierte Historien) helfen, die Kosten signifikant zu kontrollieren.
Dies entspricht einer ~3-fachen Erhöhung gegenüber Gemini 3 Flash Preview ($0.50/$3), bleibt aber wettbewerbsfähig angesichts des Fähigkeitssprungs. Es nähert sich der Preisgestaltung von Gemini 3.1 Pro ($2/$12), bietet jedoch für viele Workloads bessere Geschwindigkeit.
Free Tier: Begrenzter Zugang über Google AI Studio/Gemini-App; kostenpflichtig für Produktion.
Cometapi Vorteil: Zugriff auf die Gemini 3.5 Flash API neben 100+ Modellen mit konkurrenzfähigen Tarifen, Nutzungsanalysen und Optimierungstools zur Minimierung des Token-Verbrauchs. Unsere Plattform liefert häufig bessere effektive Preise durch smartes Routing und Batching. API-Preise sind typischerweise 20 % niedriger als offizielle Preise.
Gemini 3.5 Flash vs. GPT-5.5, Claude 4.7/4.6 und andere
Stärken von Gemini 3.5 Flash:
- Speed + Agentic Balance: Schnellere Inferenz als die meisten Spitzenmodelle bei gleichzeitig kleiner werdender Intelligenzlücke.
- Multimodal & langer Kontext: Native 1M-Kontextfenster und Führungsrolle bei Vision.
- Kosten bei Volumen: Günstiger pro Token als Top-Claudes/GPTs für viele Workloads, insbesondere mit Caching.
- Google-Ökosystem: Nahtlose Integration mit Search, Workspace, Cloud.
Wo Wettbewerber die Nase vorn haben:
- GPT-5.5 führt häufig in rohem Reasoning (z. B. ARC-AGI) und kann stärkere kreative/allgemeine Fähigkeiten haben.
- Claude Opus 4.7/Sonnet 4.6 glänzen beim sorgfältigen Coding (höhere SWE-Bench in einigen Fällen) und nuancierter Schreib-/Safety-Performance.
- Token-Effizienz variiert; agentische Loops können 3.5 Flash insgesamt teurer machen.
Vergleich auf hoher Ebene (ungefähre/ausgewählte Metriken; stets die neuesten Leaderboards prüfen):
| Benchmark / Metrik | Gemini 3.5 Flash | GPT-5.5 | Claude Opus 4.7 / Sonnet 4.6 | Gemini 3.1 Pro | Hinweise |
|---|---|---|---|---|---|
| Terminal-bench 2.1 (Programmierung) | 76,2% | 78,2% | ~66% | 70,3% | Agentisches Coding |
| MCP Atlas (Agentisch) | 83,6% | 75,3% | 79,1% / 69,5% | 78,2% | Mehrstufige Workflows |
| GDPval-AA (agentisches Wissen) | 1656 Elo | 1769 | 1753 | 1314 | Ökonomischer Wert |
| MMMU-Pro (Multimodal) | 83,6% | 81,2% | ~75% | 80,5% | Starke Gemini-Führung |
| Intelligence Index (AA) | 55 | Hoch (variiert) | Wettbewerbsfähig | Niedriger | Pareto Geschwindigkeit/Intelligenz |
| Geschwindigkeit (Tokens/s) | >280 | Niedriger | Variabel | Langsamer | Flash-Vorteil |
| Input/Output-Preis ($/1M) | 1.50 / 9.00 | Höher | Höher (insb. Opus) | 2/12 | Kosteneffiziente Frontier |
| Kontextfenster | 1M | Wettbewerbsfähig | Stark | 1M+ | Alle auf Frontier-Niveau |
Zusammenfassung der Trade-offs:
- Gemini 3.5 Flash gewinnt bei Geschwindigkeit + Multimodalität + agentischer Effizienz für Skalierung.
- GPT-5.5 hat oft die Nase vorn bei rohem Reasoning/Coding-Spitzenwerten.
- Claude 4.7 Opus überzeugt bei sorgfältigem, hochzuverlässigem Coding, jedoch mit höherer Kosten/Latenz.
Gemini führt häufig oder liegt gleichauf in multimodalen und spezifischen agentischen Suites, ist dabei schneller und für hohes Volumen erschwinglicher.
Zugang und Integration von Gemini 3.5 Flash
Zugang über:
- Gemini-App / Google AI Studio
- Gemini API (
gemini-3.5-flash) - Google Cloud Vertex AI / Enterprise Agent Platform
- Drittanbieter-Aggregatoren für Multi-Provider-Flexibilität.
CometAPI Empfehlung: Für Produktionsanwendungen auf Cometapi.com einmalig integrieren über einen einzigen API-Schlüssel, um Zugriff auf Gemini 3.5 Flash (und 500+ Modelle von OpenAI, Anthropic, xAI usw.) mit 20–40 % niedrigerer effektiver Preisgestaltung, ohne Vendor-Lock-in und einfachem Model-Swapping zu erhalten.
Vorteile für Ihre Projekte:
- Testen Sie Gemini 3.5 Flash im Vergleich zu GPT-5.5 oder Claude 4.7 sofort, indem Sie den Modellnamen ändern.
- Einheitliche Abrechnung, Fallback-Routing und optimierte Latenz.
- Ideal für agentische Apps, die Zuverlässigkeit über Anbieter hinweg benötigen.
- Kostenloser API-Key mit großzügigen Testlimits.
Die Beispielintegration ist unkompliziert mit offiziellen SDKs oder CometAPI’s einheitlichem Endpoint – perfekt für die Skalierung der Programmierung.
Use Cases und Best Practices
- Agentische Automatisierung: Robuste Multi-Agent-Systeme für Forschung, Datenanalyse oder Kundensupport aufbauen.
- Coding & Entwicklung: Iteratives Prototyping, Debugging und vollständige Pipeline-Generierung in Antigravity oder IDEs.
- Multimodale Anwendungen: Bild-/Videoanalyse, Diagrammverständnis, Content-Erstellung.
- Enterprise-Workflows: Langfristige Prozesse mit Kostenkontrolle durch Caching und Thinking Levels.
Tipps: Nutzen Sie die vollständige Gesprächshistorie für Thought Preservation. Beginnen Sie mit medium Thinking. Optimieren Sie Prompts, um Tool-Aufrufe zu reduzieren. Überwachen Sie den Tokenverbrauch für Kosteneffizienz.
Einschränkungen und Überlegungen
- Preiserhöhung erfordert sorgfältige Optimierung für Anwendungen mit hohem Volumen.
- Noch keine Computer-Nutzung (Updates beobachten).
- Safety-Evaluierungen zeigen solide Performance mit Verbesserungen im Ton, wenngleich automatisierte Metriken variieren.
- Halluzinationsreduktion ist bemerkenswert, kritische Ausgaben sollten dennoch stets validiert werden.
- Preiserhöhung: Höher als frühere Flash-Modelle; mit Thinking Levels und Caching optimieren.
- Wissensstand: Januar 2025 – Grounding/Search-Tools für aktuelle Ereignisse nutzen.
Fazit: Lohnt sich Gemini 3.5 Flash?
Ja – für Entwicklerinnen, Entwickler und Unternehmen, die Geschwindigkeit, agentische Zuverlässigkeit, multimodale Fähigkeiten und skalierbare Performance priorisieren. Es verschiebt die Pareto-Grenze und macht Frontier-AI für Produktions-Workloads zugänglicher.
Bereit zum Bauen? Besuchen Sie CometAPI, um Gemini 3.5 Flash zusammen mit anderen Top-Modellen in einem Dashboard zu testen. Optimieren Sie Ihren AI-Stack, senken Sie Kosten und liefern Sie schneller.