

En el vertiginoso mundo de los asistentes de programación con IA, el lanzamiento de Kimi K2.7 Code de Moonshot AI el 12 de junio de 2026 destaca como un avance significativo para desarrolladores, agentes de IA y empresas que buscan soluciones potentes, rentables y de código abierto.
Este modelo especializado en programación se basa en la familia K2 y hace hincapié en tareas de ingeniería de software de horizonte largo, seguimiento fiable de instrucciones en contextos masivos, llamadas a herramientas en múltiples turnos, entradas de visión y salidas estructuradas para flujos de trabajo orientados a agentes. Con 1 billón de parámetros totales pero solo 32 mil millones activados por token gracias a un diseño de Mezcla de Expertos (MoE), ofrece capacidades de frontera a una fracción del costo de modelos cerrados como Claude Opus 4.8 o GPT-5.5.
CometAPI ha integrado ahora Kimi K2.7 Code, haciéndolo accesible sin fricciones a través de un único endpoint compatible con OpenAI a un precio inferior al oficial. Esta integración permite a los desarrolladores cambiar de modelo sin esfuerzo, optimizar costos y crear aplicaciones robustas impulsadas por IA sin gestionar múltiples proveedores.
¿Qué es Kimi K2.7 Code?
Kimi K2.7 Code (también denominado Kimi-K2.7-Code o kimi-k2.7-code) es un modelo MoE orientado a programación y agentes desarrollado por Moonshot AI. Está diseñado explícitamente para tareas de ingeniería de software de horizonte largo: escenarios en los que una IA debe mantener el contexto durante miles de pasos, navegar por repositorios, invocar herramientas, editar código en varios módulos, ejecutar pruebas, depurar e iterar hasta completar.
Características clave:
- Pesos abiertos en Hugging Face (
moonshotai/Kimi-K2.7-Code). - Licencia MIT modificada: permisiva para uso comercial con requisitos de atribución en despliegues de alto volumen.
- Soporte multimodal nativo: texto + imagen + video mediante el codificador MoonViT (~400M de parámetros).
- Modo de pensamiento siempre activo: obligatorio para un rendimiento agéntico fiable; no puede desactivarse.
A diferencia de los modelos de chat generales, K2.7 Code está afinado para la fiabilidad en sesiones prolongadas. Reduce el “overthinking” (exceso de tokens de razonamiento interno) aproximadamente un 30% frente a K2.6, lo que se traduce en menores costos, iteraciones más rápidas y mejores tasas de éxito de extremo a extremo en flujos de trabajo complejos.
Esto lo hace ideal para:
- Refactorizaciones a escala de repositorio.
- Generación de código en varios lenguajes (Python, Rust, Go, etc.).
- Uso de herramientas orientado a agentes (MCP, CI/CD, operaciones del sistema de archivos).
- Tareas de frontend, DevOps, optimización del rendimiento e ingeniería de ML.
¿Qué hay de nuevo en Kimi K2.7 Code?
1) Programación de horizonte largo más sólida
La mayor mejora es el mejor rendimiento en tareas de codificación de horizonte largo. Moonshot afirma que K2.7 Code mejora el éxito de extremo a extremo en flujos de trabajo complejos de ingeniería de software, no solo en autocompletado de código puntual. Ese es el tipo de mejora que los desarrolladores notan cuando un modelo puede mantener el hilo de un proyecto a lo largo de muchos turnos en lugar de desviarse tras los primeros pasos.
Mejoras sustanciales de benchmarks frente a K2.6:
- +21.8% en Kimi Code Bench v2 (62.0% vs. 50.9%)
- +11.0% en Program Bench (53.6% vs. 48.3%)
- +31.5% en MLS Bench Lite (35.1% vs. 26.7%)
- +9.3% en Kimi Claw 24/7 Bench
- +9.5% en MCP Atlas
- +11.4% en MCP Mark Verified (81.1% vs. 72.8%)
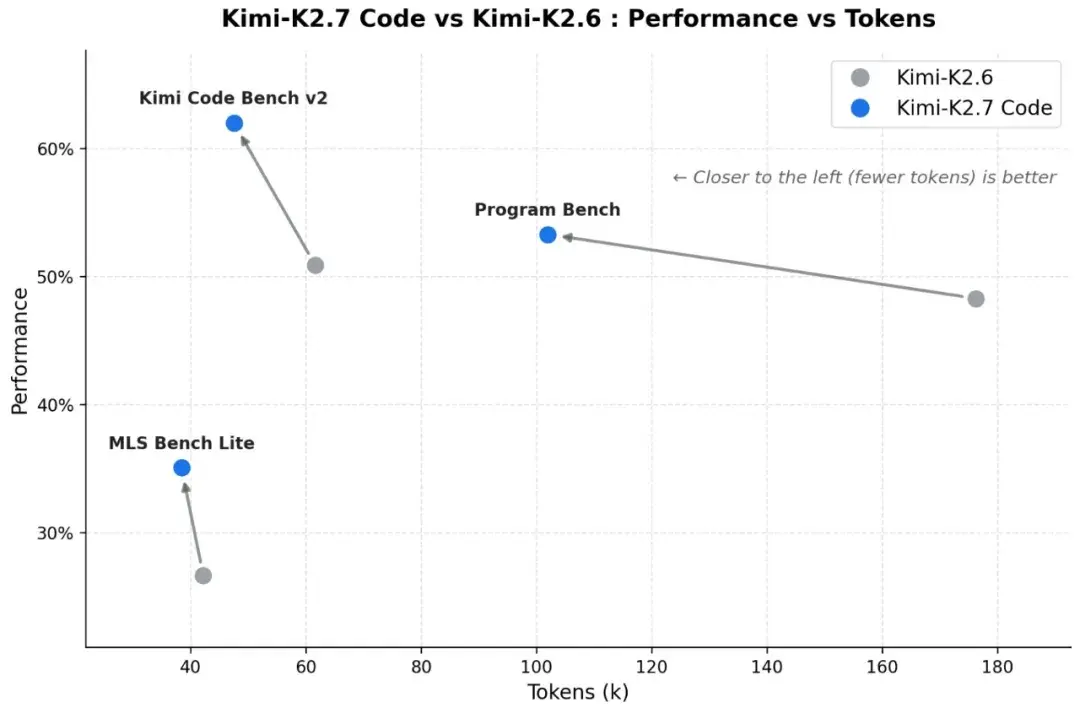
2) Mejor eficiencia de razonamiento
Moonshot informa que K2.7 Code usa alrededor de un 30% menos de tokens de pensamiento que K2.6. El changelog de Workers AI de Cloudflare repite esa afirmación de eficiencia y añade que un menor uso de tokens de razonamiento puede reducir el costo de inferencia en cargas de trabajo intensivas en razonamiento. En términos sencillos: el modelo no solo es más inteligente en tareas de codificación, también es más económico cuando piensa.
3) Comportamiento de pensamiento por defecto
Kimi K2.7 Code es únicamente un modelo con pensamiento. Moonshot dice que no admite modo sin pensamiento y, en Kimi Code, si se desactiva el pensamiento, el sistema vuelve automáticamente a K2.6. Ese es un detalle útil para equipos que construyen herramientas de codificación agénticas, porque implica que se debe diseñar con el razonamiento activado por defecto.
4) Capacidades mejoradas de horizonte largo:
Mejor generalización entre lenguajes (Python, Rust, Go, etc.) y escenarios (frontend, DevOps, seguridad, ML). Mayores tasas de éxito de tareas de extremo a extremo.
5) Multimodal y uso de herramientas mejorados
Codificador de visión (400M de parámetros) para imágenes/videos; integración fluida con MCP/herramientas para entornos reales (GitHub, Postgres, navegadores, etc.).
Arquitectura y parámetros de Kimi K2.7 Code
Kimi K2.7 Code utiliza una arquitectura de Mezcla de Expertos. Según la tarjeta del modelo oficial en Hugging Face, tiene 1T de parámetros totales y 32B de parámetros activados. Incluye 61 capas, 384 expertos, 8 expertos seleccionados por token, 1 experto compartido, atención MLA, activación SwiGLU, un vocabulario de 160K y una longitud de contexto de 256K. El codificador de visión es MoonViT con 400M de parámetros.
Esa arquitectura explica el atractivo del modelo. Un modelo MoE de un billón de parámetros puede preservar un enorme techo de capacidad activando solo un subconjunto de parámetros por token, lo que es una razón por la que los sistemas MoE resultan atractivos para inferencia de alta capacidad. K2.7 Code adopta el mismo enfoque de cuantización nativa INT4 que K2 Thinking, lo que ayuda a la eficiencia de despliegue.
La ventana de contexto es otro punto de venta clave. La documentación oficial describe una ventana de 256K, lo suficientemente grande para bases de código extensas, conversaciones largas y sesiones de agentes de múltiples pasos donde la retención de contexto es crítica.
K2.7 Code comparte el mismo diseño de pensamiento intercalado y llamadas a herramientas de múltiples pasos que K2 Thinking, y recomienda Kimi Code CLI como el marco de agente que mejor se ajusta al modelo. Es una señal clara de que Moonshot considera a K2.7 Code un caballo de batalla agéntico, no meramente un modelo de interfaz de chat.
Especificaciones principales (de la tarjeta de modelo oficial):
- Parámetros totales: 1T (1 billón)
- Parámetros activados por token: 32B (aprox. 3% de activación dispersa para eficiencia)
- Expertos: 384 en total (8 seleccionados por token + 1 experto compartido)
- Capas: 61 (incluida 1 capa densa)
- Atención: MLA (Multi-head Latent Attention)
- Activación de feed-forward: SwiGLU
- Tamaño del vocabulario: ~160K–166K
- Codificador de visión: MoonViT (~400M de parámetros) para multimodal nativo (texto + imagen/video)
- Longitud de contexto: 256K tokens (262,144)
- Cuantización: Soporte nativo INT4 para despliegue eficiente
- Entrenamiento: Optimizador Muon, entrenado con enormes tokens mixtos de texto/visual con mejoras de estabilidad.
Por qué importa MoE: Solo ~3% de los parámetros se activan por token, ofreciendo capacidad cercana a la frontera a una fracción del costo computacional de modelos densos de tamaño total similar. Esto habilita autoalojamiento o uso por API asequible para tareas de programación de alto volumen.
El modelo es grande (~595 GB de pesos), orientado a inferencia en clase servidor (vLLM, SGLang, KTransformers). Reutiliza patrones de despliegue de K2.5/K2.6.
Benchmarks de rendimiento: ¿Qué tan bueno es?
Moonshot proporciona benchmarks detallados de primera parte que comparan K2.7 Code con K2.6, GPT-5.5 y Claude Opus 4.8. Si bien continúa la verificación independiente (por ejemplo, algunos profesionales observan resultados mixtos en kernels públicos), las mejoras son impresionantes para un especialista en programación.
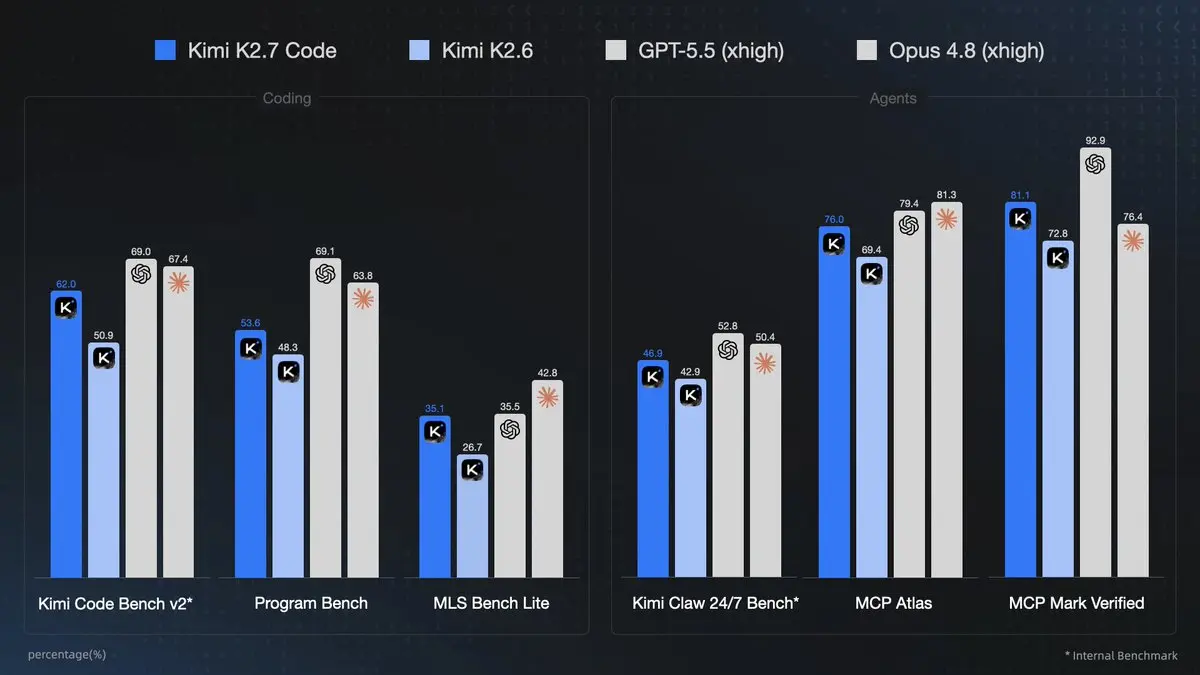
Tabla de benchmarks clave:
| Benchmark | Kimi K2.6 | Kimi K2.7 Code | GPT-5.5 | Claude Opus 4.8 | Mejora (K2.7 vs K2.6) |
|---|---|---|---|---|---|
| Kimi Code Bench v2 | 50.9 | 62.0 | 69.0 | 67.4 | +21.8% |
| Program Bench | 48.3 | 53.6 | 69.1 | 63.8 | +11.0% |
| MLS Bench Lite | 26.7 | 35.1 | 35.5 | 42.8 | +31.5% |
| Kimi Claw 24/7 Bench | 42.9 | 46.9 | 52.8 | 50.4 | +9.3% |
| MCP Atlas | 69.4 | 76.0 | 79.4 | 81.3 | +9.5% |
| MCP Mark Verified | 72.8 | 81.1 | 92.9 | 76.4 | +11.4% |
Interpretación:
- K2.7 Code reduce la brecha con modelos de frontera en tareas de programación/agentes y supera a Opus 4.8 en MCP Mark Verified.
- Fuerte en escenarios de ingeniería de software del mundo real multilenguaje y uso de herramientas.
- La ventaja de eficiencia (30% menos tokens) a menudo lo hace preferible para agentes de larga duración, aunque no siempre lidere en precisión bruta. Menos tokens por tarea significan más iteraciones dentro del presupuesto/límites de contexto.
Advertencias: Muchas cifras son internas o de configuraciones específicas. Pruebas independientes (p. ej., KernelBench) muestran resultados mixtos en ciertas tareas de bajo nivel, pero en general los profesionales destacan su utilidad práctica en bucles largos de codificación.
Ganancias de eficiencia: ventajas de costo y velocidad
Una reducción del 30% en tokens de pensamiento suena abstracta hasta que se lleva a producción. Menos tokens de razonamiento suelen significar menor latencia, menor costo y menos posibilidades de que el modelo divague con pasos internos innecesarios en tareas largas. Moonshot afirma que K2.7 Code mejora la eficiencia preservando un mayor grado de finalización de tareas, y Cloudflare lo enmarca específicamente como una ventaja de costo para cargas de trabajo intensivas en razonamiento.
Esa combinación importa en agentes de codificación porque las tareas de ingeniería de software rara vez se resuelven en un solo intento. Implican leer una base de código, realizar un cambio, verificarlo, manejar excepciones e iterar. Un modelo más eficiente en tokens y mejor en finalización de tareas de horizonte largo puede ser materialmente mejor para la productividad del equipo que un modelo simplemente fuerte en respuestas breves. Esa es una inferencia basada en los benchmarks y afirmaciones de flujo de trabajo de Moonshot, pero se desprende directamente de cómo se posiciona el modelo.
¿Cuánto cuesta Kimi K2.7 Code?
La membresía de Kimi Code de Moonshot incluye K2.7 Code y parte desde $19/mes, según la página oficial. Ese es el camino orientado al consumidor. Para uso por API, el precio depende de dónde accedas al modelo. En comparación con Claude Opus (~$5–25 / M) u otros precios de frontera similares, K2.7 Code ofrece hasta 5–12x mejor valor para cargas de trabajo de programación. El autoalojamiento reduce aún más los costos para usos de alto volumen.
En CometAPI, Kimi K2.7 Code figura a $0.76 por millón de tokens de entrada y $3.19998 por millón de tokens de salida, mientras que el precio oficial se muestra como $0.95 por millón de tokens de entrada y $3.999975 por millón de tokens de salida, lo que CometAPI presenta como un 20% de descuento frente al precio oficial.
Eso hace que CometAPI sea interesante para equipos que quieran experimentar con Kimi K2.7 Code sin gestionar integraciones con proveedores separados ni pagar el precio directo más alto.
Dónde acceder a Kimi K2.7 Code
1) Kimi Code
Moonshot afirma que Kimi K2.7 Code es ahora el modelo por defecto en Kimi Code, con el modo de pensamiento activado por defecto. Es la forma más nativa de probar el modelo si deseas el entorno de codificación de Moonshot.
2) Kimi API / Kimi Platform
La plataforma abierta de Moonshot documenta Kimi K2.7 Code como disponible a través de Kimi API, y señala que la plataforma usa el formato de la API de OpenAI. Eso facilita integrarlo en arquitecturas de aplicaciones que ya manejan patrones de API compatibles con OpenAI.
3) Hugging Face
La tarjeta de modelo oficial en Hugging Face confirma la publicación de pesos abiertos, muestra el resumen del modelo y datos de benchmarks, y establece que el repositorio de código y los pesos del modelo se publican bajo una Licencia MIT modificada. Esta es la vía para desarrolladores que quieran inspeccionar los pesos, desplegar por su cuenta o usar el modelo en ecosistemas de herramientas abiertas.
4) CometAPI
CometAPI ahora lista Kimi K2.7 Code como un modelo integrado y ofrece precios por token, una página de modelo y acceso por API a través de su gateway unificado. También destaca que la plataforma es compatible con OpenAI y está diseñada para reducir la fragmentación de proveedores poniendo muchos modelos detrás de un único punto de entrada. Admite la ventana de contexto de 256K, entradas de visión, llamadas a herramientas en múltiples turnos y una ruta compatible con OpenAI vía /v1/chat/completions. No se requieren cambios de parámetros si estás migrando desde K2.6.
Recomendación de CometAPI: Para la mayoría de los usuarios, empieza aquí. Una sola clave, pago por uso en más de 500 modelos, reintentos automáticos y tarifas efectivas más bajas. Perfecto para probar K2.7 Code junto con Claude, GPT o modelos abiertos sin bloqueo de proveedor. Regístrate en Cometapi.com y cambia la URL base/nombre de modelo en tu cliente de OpenAI.
Consejo para autoalojamiento: Usa cuantización INT4 y paralelismo de expertos para un VRAM/rendimiento óptimos en GPUs empresariales.
Kimi K2.7 Code vs K2.6 vs otros modelos
Si tu stack actual ya usa K2.6, K2.7 Code es la actualización obvia cuando la calidad de codificación y la eficiencia de razonamiento importan más que simplemente mantener la misma base. Moonshot afirma que la arquitectura es la misma que K2.5/K2.6, el despliegue puede reutilizarse y el rendimiento en benchmarks mejora de forma material. Cloudflare también dice que el uso por API es idéntico, lo que reduce la fricción de migración.
En comparación con modelos de frontera más amplios como GPT-5.5 y Claude Opus 4.8, K2.7 Code es más especializado. La tabla de benchmarks muestra que sigue siendo competitivo en tareas de programación y agentes, pero su verdadero diferenciador es la combinación de acceso de código abierto, contexto largo y diseño centrado en programación. Eso lo hace especialmente atractivo para equipos que valoran la flexibilidad de despliegue y el control de costos.
Conclusión: por qué integrar Kimi K2.7 Code vía CometAPI hoy
Kimi K2.7 Code representa la madurez del ecosistema de asistentes de programación de código abierto: potente, eficiente, accesible y listo para agentes. Su arquitectura, mejoras de benchmarks y eficiencia en tokens lo convierten en una prueba obligatoria para desarrolladores en 2026.
CometAPI rebaja aún más la barrera con integración sin fricciones, precios competitivos y acceso unificado. Ya sea autoalojando, usando la API oficial o aprovechando la plataforma de CometAPI, K2.7 Code potencia flujos de trabajo de codificación más rápidos y fiables.
¿Listo para probarlo? Visita CometAPI, consigue tu clave de API y empieza a construir con Kimi K2.7 Code hoy. Experimenta, haz benchmarks en tus casos de uso y escala con confianza.
Preguntas frecuentes
¿Es Kimi K2.7 Code de código abierto?
Sí. Moonshot afirma que tanto el repositorio de código como los pesos del modelo se publican bajo una Licencia MIT modificada, y el modelo está disponible en Hugging Face.
¿Cuál es la ventana de contexto?
La documentación de Moonshot indica una ventana de contexto de 256K, y la tarjeta del modelo y Cloudflare la describen como 262,144 o 262.1K tokens. Es esencialmente la misma escala.
¿Kimi K2.7 Code admite modo sin pensamiento?
No. Moonshot dice que K2.7 Code solo funciona con el pensamiento activado. En Kimi Code, desactivar el pensamiento hace que el sistema vuelva a K2.6.
¿Cuál es la mayor mejora frente a K2.6?
La mayor mejora reportada es un mejor rendimiento en codificación de horizonte largo más alrededor de un 30% menos de tokens de pensamiento. Moonshot también reporta mejoras de +21.8% en Kimi Code Bench v2, +11.0% en Program Bench y +31.5% en MLS Bench Lite.
¿Puedo usarlo a través de CometAPI?
Sí. CometAPI ahora lista Kimi K2.7 Code como un modelo integrado y muestra precios por token, lo que lo convierte en una vía de acceso conveniente para desarrolladores que quieren una capa de API unificada.
¿Es bueno para agentes de codificación de IA?
Sí. La documentación de Moonshot enfatiza llamadas a herramientas de múltiples pasos, pensamiento intercalado y flujos de trabajo orientados a agentes, mientras que Cloudflare destaca llamadas a herramientas en múltiples turnos y salidas estructuradas.