

Nel panorama dell’IA in rapida evoluzione, GLM-5.2 di Z.ai (Zhipu AI) si distingue come un formidabile modello a pesi aperti ottimizzato per il coding agentico, i compiti a lungo termine e l’affidabilità in produzione. Con una finestra di contesto utilizzabile da 1M token, doppi livelli di ragionamento (High e Max) e prestazioni elevate a una frazione del costo dei modelli chiusi all’avanguardia, sta rapidamente diventando la scelta di riferimento per sviluppatori che costruiscono agenti autonomi, integrazioni IDE e workflow complessi di ingegneria del software.
Che tu sia uno sviluppatore singolo che prototipa agenti, un CTO che valuta una scalabilità conveniente, o un product manager di AI che integra capacità di ragionamento multimodali in un SaaS, padroneggiare le API di GLM-5.2 sblocca vantaggi significativi.
Che cos’è GLM-5.2?
GLM-5.2 è l’ultimo modello di punta a pesi aperti con architettura Mixture-of-Experts (MoE) di Z.ai (Zhipu AI), rilasciato a metà giugno 2026. Con circa 753 miliardi di parametri totali (circa 40B attivi per token), una stabile finestra di contesto da 1 milione di token, licenza MIT e forti prestazioni su coding a lungo termine e compiti agentici, si posiziona come un’alternativa competitiva ai modelli chiusi di frontiera come GPT-5.5, Claude Opus 4.8 e varianti Gemini—a una frazione del costo per molti carichi di lavoro.
Architettura e specifiche tecniche di GLM-5.2
GLM-5.2 si basa sulla famiglia GLM con aggiornamenti chiave per il lavoro a lungo termine.
- Parametri: ~753B totali in design MoE (parametri attivi ~40B per token). Offre capacità massiva con inferenza efficiente.
- Finestra di contesto: 1.048.576 token (1M). Output massimo tipicamente fino a 128K–131K token.
- Precisione: BF16 (con varianti FP8 per deployment più leggeri).
- Innovazione chiave – IndexShare: Riutilizza un singolo indexer su gruppi di layer di attenzione sparsa, riducendo i FLOP per token fino a 2,9x a contesto 1M. Rende l’inferenza su lunghi contesti praticabile senza esplosione di costi o latenza.
- Modalità di ragionamento: "High" (bilanciata) e "Max" (più profonda, consigliata per il coding). Il “pensiero” può essere disattivato per compiti semplici.
- Modalità: Principalmente testo/codice (nessuna visione nativa confermata nella release base).
- Licenza: MIT – completamente aperta al download, alla modifica e all’uso commerciale.
Questa apertura ed efficienza rendono GLM-5.2 ideale per team che danno priorità a privacy dei dati, personalizzazione o controllo dei costi.
GLM-5.2 vs GLM-5.1
| Ambito | GLM-5.1 | GLM-5.2 | Differenza pratica |
|---|---|---|---|
| Finestra di contesto | Circa 200K sulle route ospitate comuni | 1M | GLM-5.2 è molto più adatto a contesti di progetto interi |
| Sforzo di ragionamento | Meno flessibile | High e Max | Miglior controllo su costo, latenza e qualità |
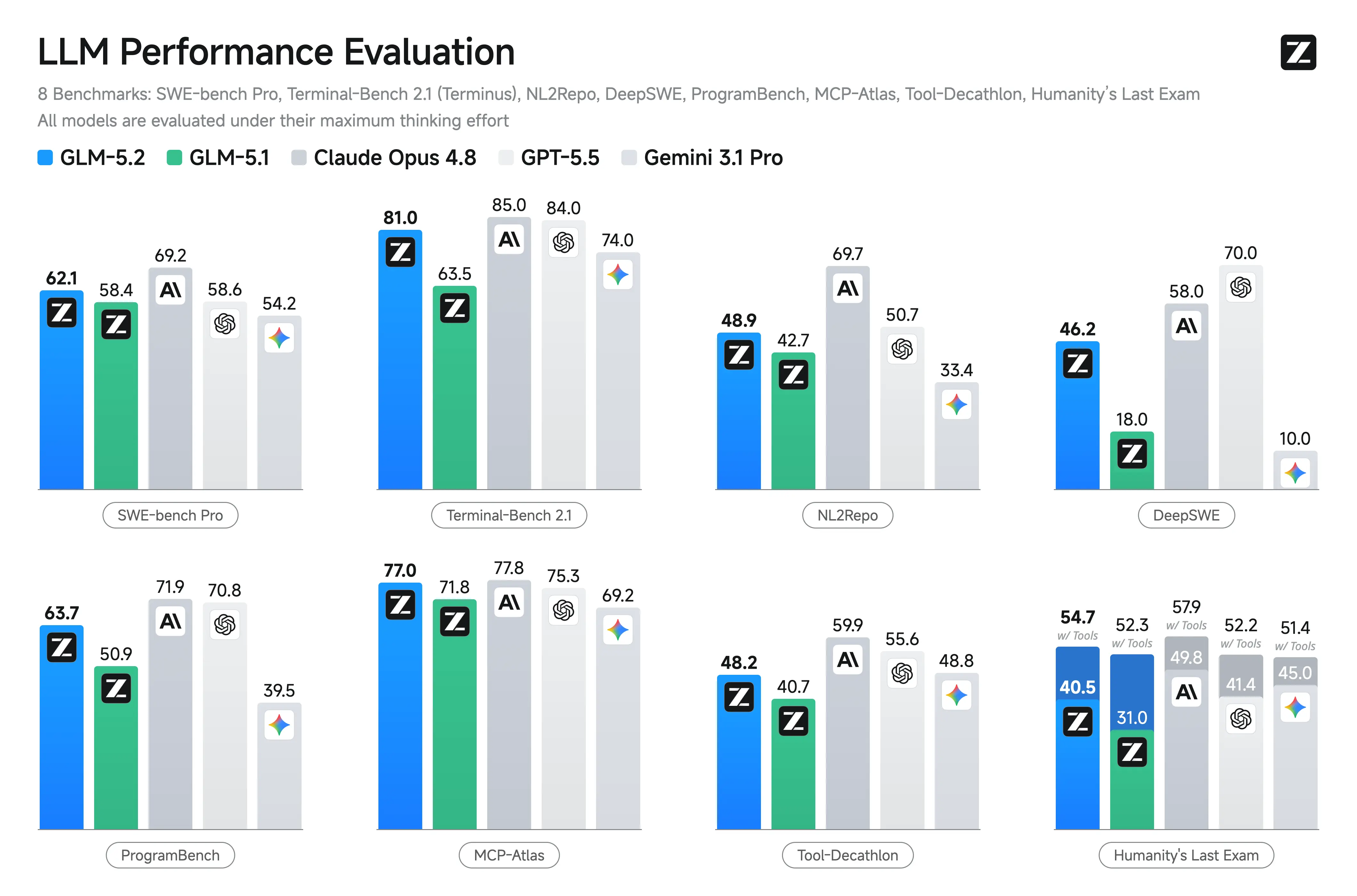
| Terminal Bench 2.1 | 63.5 nella tabella pubblicata | 81.0 | Grande miglioramento nelle attività agentiche da terminale |
| SWE-bench Pro | 58.4 | 62.1 | Guadagno moderato ma significativo a livello di repo |
| FrontierSWE | 30.5 | 74.4 | Notevole miglioramento nell’ingegneria a lungo orizzonte |
| Impostazione a pesi aperti | Famiglia GLM a pesi aperti | Rilascio MIT a pesi aperti | Apertura simile, posizionamento più forte sul lungo contesto |
Se il tuo workflow attuale con GLM-5.1 è per lo più chat brevi o generazione di codice di base, l’upgrade potrebbe non cambiare tutto. Se il tuo workflow coinvolge grandi repository, agenti di coding multi-step o esecuzione di task lunghi, GLM-5.2 è un modello molto più pertinente.
GLM-5.2 vs Claude Opus, GPT-5.5, Gemini e DeepSeek
Il modo più chiaro per confrontare GLM-5.2 è per tipo di task:
| Tipo di task | Posizionamento di GLM-5.2 |
|---|---|
| Coding a lungo termine | Una delle opzioni a pesi aperti più forti; vicino ai modelli chiusi di frontiera su benchmark selezionati |
| Ragionamento generale | Forte, ma non sempre davanti ai migliori modelli chiusi |
| Uso di strumenti | Prestazioni elevate su MCP-Atlas e HLE-with-tools |
| Competizioni di matematica | Punteggio AIME 2026 molto alto nei risultati pubblicati |
| Visione | Non è il modello giusto; usare un modello di visione |
| Classificazione a basso costo e alto volume | Di solito sovradimensionato; usare un modello più piccolo |
| Self-hosting e personalizzazione | Opzione più forte rispetto ai modelli chiusi solo API |
Per i team, la risposta migliore di solito non è "sostituire ogni modello con GLM-5.2". La risposta migliore è "instradare GLM-5.2 ai compiti in cui ha un vantaggio". Questo è uno dei motivi per cui un provider di API unificato come CometAPI può essere pratico. Consente di confrontare e instradare i modelli per carico di lavoro senza ricostruire ogni integrazione.
Prezzi: potenza conveniente per la scalabilità
GLM-5.2 offre un’economia convincente, soprattutto per lavori a lungo contesto ad alto volume di token.
- Prezzi API (via Z.ai/OpenRouter/etc.): $1.40 / 1M token in input, $4.40 / 1M token in output. Lettura da cache fino a $0.26/1M in alcune route.
- Abbonamenti al piano GLM Coding (include accesso completo, senza extra per 5.2):
- Lite: ~$10-12.60/mese (iterazione leggera).
- Pro: ~$30/mese.
- Max/Team: Quote più alte per uso intensivo.
Esempio di risparmio sui costi: Per una lunga sessione agentica con 500K di contesto + output, GLM-5.2 può costare 4-5x meno degli equivalenti Claude gestendo nativamente contesti più grandi.
Raccomandazione CometAPI: Accedi a GLM-5.2 (e oltre 500 altri modelli) tramite l’endpoint unificato compatibile con OpenAI di CometAPI a tariffe competitive. Una sola chiave, nessun vendor lock-in, crediti di test alla registrazione. Ideale per confrontare GLM-5.2 fianco a fianco con Claude/GPT in produzione. Visita cometapi per un’integrazione senza attriti.
Finestra di contesto da 1M: la caratteristica distintiva
L’1M di contesto è "solido" e senza perdite in pratica per lavori a scala di progetto—ben oltre l’hype di marketing. Consente di mantenere in contesto interi repository di dimensioni medio-grandi, riducendo l’overhead di sintesi e l’accumulo di errori negli agenti.
Suggerimenti per un uso efficace:
- Usa l’identificatore glm-5.2[1m].
- Imposta correttamente il valore di max tokens; monitora in produzione.
- Combina con strumenti/MCP per il recupero dinamico dei dati.
Test preliminari confermano stabilità oltre i 200K, un punto di fallimento comune per altri modelli "a lungo contesto".
Prestazioni di base e benchmark
Z.ai e report indipendenti evidenziano i punti di forza di GLM-5.2 in scenari di coding e agentici. Mostra guadagni sostanziali rispetto a GLM-5.1 e risultati competitivi rispetto ai modelli chiusi su compiti a lungo termine.
Benchmark chiave riportati (Z.ai e aggregati di terze parti):
- Terminal-Bench 2.1: 81.0 (in aumento rispetto ai 62.0 di GLM-5.1) – Eccellente per operazioni da terminale/agent.
- SWE-bench Pro: 62.1 (supera GPT-5.5 a 58.6).
- MCP-Atlas: 77.0 (vicino a Claude Opus 4.8).
- Humanity’s Last Exam (con strumenti): 54.7.
Altri punti di forza: Ai vertici o quasi tra i modelli open su FrontierSWE, PostTrainBench, SWE-Marathon. Forte su AIME 2026 (~99.2) e GPQA-Diamond (91.2).
Opzioni di accesso all’API di GLM-5.2
Ci sono due modi comuni per accedere a GLM-5.2 da un’applicazione.
Opzione 1: Usare Z.ai direttamente
La via diretta è usare l’API ufficiale di Z.ai. Può essere la scelta giusta quando il tuo team desidera una relazione diretta con il fornitore del modello, usa solo modelli Z.ai o necessita di controlli specifici del provider appena vengono rilasciati.
Il compromesso è operativo. Se il tuo prodotto usa più famiglie di modelli, potresti dover mantenere configurazioni SDK separate, flussi di fatturazione, logica di failover, normalizzazione dei prezzi e convenzioni di osservabilità. Per un progetto di ricerca può andare bene. Per una piattaforma SaaS in produzione, la superficie di integrazione può crescere rapidamente.
Opzione 2: Usare GLM-5.2 tramite CometAPI
CometAPI fornisce accesso a GLM-5.2 tramite un gateway API unificato. Il vantaggio pratico è che gli sviluppatori possono chiamare diversi modelli di IA attraverso un’unica interfaccia compatibile con OpenAI invece di costruire un’integrazione per provider. Mantieni il tuo codice vicino al pattern dell’SDK di OpenAI, imposta il nome del modello su glm-5.2 e instrada le richieste tramite CometAPI.
Questo è utile per startup e team di prodotto che vogliono:
- Testare GLM-5.2 rispetto ad altri modelli senza ricostruire il backend
- Mantenere una sola chiave API e un solo livello di fatturazione per più modelli
- Passare più velocemente da benchmark a prototipo a produzione
- Implementare strategie di fallback o routing tra modelli
- Confrontare costo e qualità tra provider
- Usare pattern di richieste in stile OpenAI
Registrati su CometAPI.com per crediti di test istantanei e endpoint compatibili con OpenAI che astraggono le peculiarità dei provider.
- Ottieni la tua chiave API.
- Imposta le variabili d’ambiente (best practice di sicurezza):
export GLM_API_KEY="your_key_here"
export BASE_URL="https://api.cometapi.com/v1" # or direct Z.ai endpoint
Effettuare la tua prima chiamata API a GLM-5.2
Esempio cURL (test rapido):
bash
curl https://api.z.ai/api/paas/v4/chat/completions \
-H "Authorization: Bearer $GLM_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5.2",
"messages": [
{"role": "system", "content": "You are an expert full-stack engineer."},
{"role": "user", "content": "Write a FastAPI endpoint for user authentication with JWT."}
],
"temperature": 0.7,
"max_tokens": 2048
}'
Casi d’uso comuni di GLM-5.2
GLM-5.2 è un forte candidato per workflow in cui contesto lungo, ragionamento e uso di strumenti si combinano.
| Caso d’uso | Esempio di implementazione | Perché GLM-5.2 può essere adatto |
|---|---|---|
| Assistente per sviluppatori | Analizzare report di bug, snippet di codice, log e test | Richiede ragionamento su un contesto tecnico |
| Intelligenza documentale | Esaminare contratti, policy, reclami o report | Input lunghi ed estrazione strutturata |
| Agente di ricerca | Leggere fonti, confrontare affermazioni, produrre sintesi | Beneficia del lungo contesto e della disciplina delle citazioni |
| Copilota per supporto clienti | Combinare cronologia dei ticket, documentazione, dati account e policy | Necessita di retrieval e chiamata di strumenti |
| Assistente per product manager di AI | Sintetizzare feedback, specifiche, dati d’uso e note di roadmap | Lungo contesto e ragionamento business |
| Analisi di sicurezza | Esaminare report di incidenti, allarmi e piani di remediation | Richiede ragionamento multi-step accurato |
| Ingegneria delle vendite | Generare risposte tecniche da documentazione e requisiti clienti | Utile per cicli di vendita B2B complessi |
Il pattern comune non è "chatbot". Il pattern comune è la compressione del flusso di lavoro. GLM-5.2 può ridurre il tempo tra informazione grezza e decisione utile.
Chi dovrebbe usare GLM-5.2?
GLM-5.2 è particolarmente adatto a:
- Sviluppatori che costruiscono strumenti di AI per il coding.
- Aziende SaaS che aggiungono assistenti consapevoli del repository.
- CTO che valutano alternative a pesi aperti ai modelli di coding chiusi.
- Product manager di AI che testano workflow a lungo contesto.
- Imprese con future esigenze di self-hosting o controllo dei dati.
- Piattaforme per sviluppatori che necessitano di opzionalità di modello.
- Team che lavorano con ampi documenti tecnici, SDK o codebase.
È particolarmente interessante quando l’errore è costoso. Se un errore del modello causa build rotte, migrazioni errate o tempo di ingegneria sprecato, il costo di usare un modello più potente può essere rapidamente giustificato.
Quando non usare GLM-5.2
Non usare GLM-5.2 di default per:
- Task brevi e ripetitivi di classificazione.
- Semplice riscrittura di testo.
- Comprensione di immagini o screenshot.
- Autocomplete a bassa latenza dove contano i millisecondi.
- Workflow in cui un modello più piccolo già funziona bene.
- Prodotti che non possono tollerare generazioni di lunga durata.
L’obiettivo non è venerare la finestra di contesto più grande. L’obiettivo è risolvere il compito con il giusto profilo di qualità, costo e latenza.
Verdetto finale
GLM-5.2 è uno dei rilasci di modelli a pesi aperti più importanti per i team di ingegneria del software nel 2026. La combinazione di contesto da 1M, forti benchmark di coding, modalità di ragionamento High e Max, supporto alla chiamata di funzioni e licenza MIT lo rende un’opzione seria per agenti di coding e workflow di IA a lungo termine.
Per i team che vogliono provarlo rapidamente, CometAPI è uno strato di accesso pragmatico. Puoi chiamare GLM-5.2 attraverso un endpoint compatibile con OpenAI, confrontarlo con altri modelli leader, monitorare l’uso e costruire una strategia di instradamento senza ricostruire lo stack attorno a un solo provider. Inizia con una piccola valutazione privata, misura il costo per task risolto e porta GLM-5.2 in produzione solo dove i suoi punti di forza sul lungo contesto ripagano chiaramente.
Pronto a testare GLM-5.2 nella tua app? Esplora GLM-5.2 su CometAPI, crea una chiave API ed esegui la tua prima richiesta compatibile con OpenAI in pochi minuti. Usalo per un vero task su repository, non per un prompt giocattolo, e confronta il risultato con il tuo stack di modelli attuale.