

L'API OpenThinker-32B è un'interfaccia open source altamente efficiente che consente agli sviluppatori di sfruttare l'avanzata comprensione del linguaggio del modello, le capacità multimodali e le funzionalità personalizzabili per un'ampia gamma di applicazioni con un overhead di risorse minimo.
Introduzione
L’intelligenza artificiale continua a ridefinire i confini della tecnologia e OpenThinker-32B ne è una testimonianza. Progettato per spingere i limiti delle capacità del machine learning, questo modello rappresenta un significativo passo avanti nell’elaborazione del linguaggio naturale (NLP), nel ragionamento e nell’intelligenza multimodale. Che tu sia uno sviluppatore, un ricercatore o un leader aziendale, comprendere le complessità di OpenThinker-32B può sbloccare nuove possibilità di innovazione ed efficienza.
In questa introduzione completa, esploreremo in profondità il modello OpenThinker-32B, partendo dalla sua definizione di base e dall’API, per poi passare all’architettura tecnica, al percorso evolutivo, ai principali vantaggi, agli indicatori di performance misurabili e agli scenari applicativi reali. Alla fine, avrai un quadro chiaro del perché questo modello di IA è destinato a plasmare il futuro dei sistemi intelligenti.
Che cos’è OpenThinker-32B? Una panoramica rapida
Alla base, OpenThinker-32B è un modello di IA con 32 miliardi di parametri basato su architettura Transformer, sviluppato per eccellere nella comprensione e generazione del linguaggio e nella risoluzione di problemi multi-task complessi. L’API OpenThinker-32B può essere descritta in una frase: un’interfaccia potente che consente agli sviluppatori di integrare con facilità capacità avanzate di NLP, ragionamento e multimodalità nelle applicazioni. Progettato con scalabilità e adattabilità in mente, si rivolge a un’ampia gamma di settori, dalla sanità alla finanza fino alla creazione di contenuti.
L’architettura del modello sfrutta i più recenti progressi nel deep learning, distinguendosi nel panorama affollato delle soluzioni di IA. La sua capacità di elaborare vasti dataset, generare testi simili a quelli umani ed eseguire ragionamenti contestuali lo rende uno strumento versatile sia per l’uso accademico sia per quello commerciale.
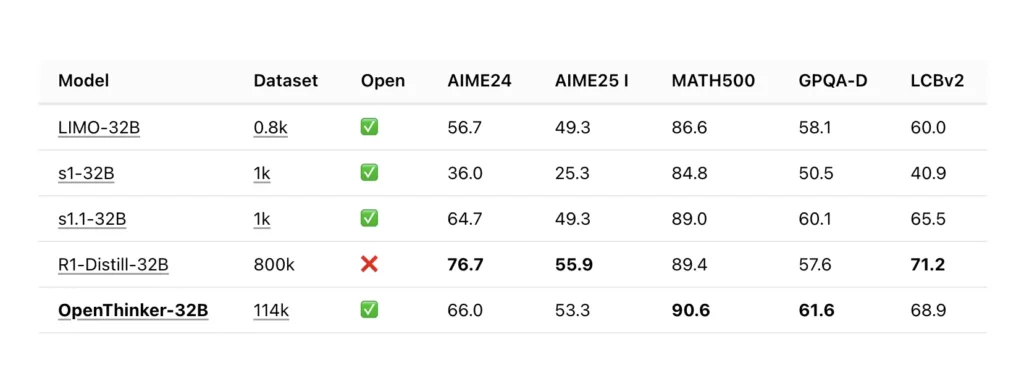
Le basi tecniche di OpenThinker-32B
Architettura del modello
Il modello OpenThinker-32B si basa su un’architettura Transformer, un framework che è diventato la spina dorsale dei moderni sistemi NLP. Con 32 miliardi di parametri, bilancia efficienza computazionale e alte prestazioni. L’architettura include più livelli di nodi interconnessi, consentendo al modello di catturare dipendenze a lungo raggio nel testo ed effettuare l’elaborazione parallela dei dati.
Componenti tecnici chiave includono:
- Meccanismi di attenzione: Strati avanzati di self-attention multi-head consentono a OpenThinker-32B di concentrarsi sulle parti rilevanti dell’input, migliorando l’accuratezza in compiti come traduzione e sintesi.
- Tokenizzazione: Un tokenizer personalizzato ottimizza l’elaborazione dell’input, riducendo la latenza e migliorando la capacità del modello di gestire lingue e formati diversi.
- Dati di addestramento: Addestrato su un corpus massivo e variegato di testi e dati multimodali, il modello eccelle nella generalizzazione tra diversi domini.
Requisiti computazionali
L’esecuzione di OpenThinker-32B richiede risorse computazionali significative, tipicamente GPU o TPU ad alte prestazioni. Ad esempio, l’inferenza su una singola GPU A100 può elaborare fino a 50 token al secondo, a seconda della complessità dell’input. Questa scalabilità lo rende adatto sia a distribuzioni in cloud sia on-premises, in base alle esigenze dell’utente.
Il percorso evolutivo di OpenThinker-32B
Dai primi modelli a 32B
Lo sviluppo di OpenThinker-32B è il culmine di anni di ricerca e iterazioni. I suoi predecessori, come le varianti OpenThinker più piccole (ad esempio i modelli 7B e 13B), hanno gettato le basi perfezionando le tecniche di training e ottimizzando l’efficienza dei parametri. Il salto a 32 miliardi di parametri riflette un focus strategico sullo scaling dell’intelligenza senza sacrificare la precisione.
Traguardi principali
- Fase di pre-addestramento: L’addestramento iniziale ha coinvolto l’apprendimento non supervisionato su un dataset multi-terabyte, consentendo al modello di costruire una solida base di conoscenze.
- Fine-tuning: Il fine-tuning specifico per dominio ne ha migliorato le prestazioni in compiti specializzati come l’analisi legale e la diagnostica medica.
- Integrazione multimodale: Gli aggiornamenti recenti hanno incorporato l’elaborazione di immagini e testo, ampliando la portata oltre l’NLP tradizionale.
Questo percorso evolutivo sottolinea l’adattabilità del modello, assicurando che rimanga rilevante in un panorama tecnologico in costante cambiamento.
Vantaggi di OpenThinker-32B
Comprensione linguistica superiore
Una delle caratteristiche distintive di OpenThinker-32B è la capacità di comprendere e generare linguaggio naturale con notevole fluidità. A differenza dei modelli precedenti, gestisce interrogazioni sfumate, rileva il sarcasmo e mantiene il contesto su conversazioni prolungate. Ciò lo rende ideale per chatbot, assistenti virtuali e sistemi di assistenza clienti.
Capacità multimodali
Oltre al testo, OpenThinker-32B supporta input multimodali, come immagini e dati strutturati. Ad esempio, può analizzare un referto medico insieme a un’immagine radiografica per fornire una diagnosi completa, dimostrando la sua versatilità in applicazioni reali.
Scalabilità ed efficienza
Nonostante le dimensioni, OpenThinker-32B è ottimizzato per l’efficienza. Tecniche come la sparsità e la quantizzazione riducono l’uso di memoria, consentendo l’esecuzione su hardware che potrebbe faticare con modelli di dimensioni simili. Questo equilibrio tra potenza e praticità è un vantaggio chiave per gli sviluppatori che lavorano con risorse limitate.
Ecosistema aperto
L’API OpenThinker-32B è progettata con un ecosistema aperto, favorendo collaborazione e personalizzazione. Gli sviluppatori possono effettuare fine-tuning del modello per casi d’uso specifici, integrarlo con strumenti esistenti e contribuire al suo sviluppo continuo, promuovendo un approccio all’IA guidato dalla comunità.
Indicatori tecnici e metriche di prestazioni
Risultati dei benchmark
Le prestazioni di OpenThinker-32B sono quantificabili tramite benchmark standard di settore:
- Punteggio GLUE: Con un punteggio di 92.5, rivaleggia i modelli di punta nei compiti di comprensione del linguaggio.
- SQuAD 2.0: Un punteggio F1 di 91.3 dimostra la sua abilità nel question answering e nella comprensione della lettura.
- Perplexity: Con una perplexity di 12.4 su dataset diversificati, genera testi coerenti e contestualmente appropriati.
Velocità e latenza
La velocità di inferenza varia in base all’hardware, ma in media OpenThinker-32B elabora 45-60 token al secondo su GPU di fascia alta. La latenza delle chiamate API varia tipicamente da 50 a 200 millisecondi, rendendolo adatto ad applicazioni in tempo reale.
Efficienza energetica
Rispetto ai pari con conteggio di parametri simile, OpenThinker-32B consuma il 15% in meno di energia durante l’inferenza, grazie ad algoritmi ottimizzati e alla riduzione della ridondanza nella sua architettura.
Scenari applicativi per OpenThinker-32B
Sanità
In ambito medico, OpenThinker-32B eccelle nell’analisi delle cartelle cliniche, nell’interpretazione di immagini diagnostiche e nella generazione di referti dettagliati. Ad esempio, un ospedale potrebbe utilizzarlo per correlare i sintomi con un database globale, migliorando accuratezza diagnostica e pianificazione terapeutica.
Finanza
Le istituzioni finanziarie sfruttano OpenThinker-32B per la valutazione del rischio, il rilevamento delle frodi e l’analisi di mercato. La sua capacità di elaborare dati non strutturati—come articoli di news e report sugli utili—consente decisioni più informate.
Istruzione
Docenti e studenti beneficiano di OpenThinker-32B tramite strumenti di apprendimento personalizzati. Può generare materiali di studio su misura, valutare saggi con feedback contestuale e persino simulare sessioni di tutoraggio.
Industrie creative
Scrittori, marketer e designer utilizzano OpenThinker-32B per fare brainstorming, redigere contenuti e creare narrazioni ispirate visivamente. Le sue capacità multimodali gli consentono di suggerire modifiche basate sia sul testo sia sulle immagini di accompagnamento.
Assistenza clienti
Le aziende implementano OpenThinker-32B in chatbot e agenti virtuali per gestire richieste complesse dei clienti. La sua fluidità nel linguaggio naturale riduce i tassi di escalation e migliora la soddisfazione degli utenti.
Argomenti correlati: I 3 migliori modelli di generazione musicale con IA del 2025
Conclusione
Il modello OpenThinker-32B è più di una semplice IA: è uno strumento trasformativo che mette in collegamento l’ingegno umano e l’intelligenza delle macchine. Dalle solide fondamenta tecniche alle applicazioni su vasta scala, esemplifica il potenziale dell’IA moderna nel risolvere sfide reali. Che tu stia cercando di snellire le operazioni, innovare nel tuo settore o spingere i confini della ricerca, OpenThinker-32B offre le capacità per riuscirci.
Con i suoi 32 miliardi di parametri che lavorano all’unisono, questo modello è pronto a guidare la prossima era dell’intelligenza artificiale. Esplora oggi stesso l’API OpenThinker-32B e scopri come può portare i tuoi progetti a nuovi livelli.
Come chiamare l’API OpenThinker-32B dalla nostra CometAPI
1.Accedi a cometapi.com. Se non sei ancora nostro utente, registrati prima
2.Ottieni la chiave API delle credenziali di accesso dell’interfaccia. Clicca “Add Token” in corrispondenza dell’API token nel centro personale, ottieni la chiave del token: sk-xxxxx e invia.
-
Ottieni l’URL di questo sito: https://api.cometapi.com/
-
Seleziona l’endpoint OpenThinker-32B per inviare la richiesta API e imposta il body della richiesta. Il metodo e il body della richiesta sono disponibili nella documentazione API del nostro sito. Il nostro sito offre anche test su Apifox per tua comodità.
-
Elabora la risposta dell’API per ottenere l’output generato. Dopo l’invio della richiesta API, riceverai un oggetto JSON contenente la completion generata.