

Gemini 3 Pro(Google/DeepMind)와 Claude Sonnet 4.5(Anthropic)는 2025년대 플래그십 모델로, 에이전트형(agentic)·장기(호라이즌)·도구 사용 워크플로에 최적화되어 있으며 코딩에 강한 비중을 둡니다. 강점에 대한 주장에는 차이가 있습니다. Google은 Gemini 3 Pro를 범용 멀티모달 추론기로 제시하면서 에이전트형 코딩에서도 두각을 드러낸다고 강조하는 반면, Anthropic은 Sonnet 4.5를 편집/도구 성공률과 장시간 에이전트 운영에서 특히 강한 세계 최고의 코드/에이전트 모델로 포지셔닝합니다.
짧은 답부터 말하자면: 두 모델 모두 2025년 말 소프트웨어 엔지니어링 작업에 최상급입니다. 순수 소프트웨어 엔지니어링 벤치 지표에서는 Claude Sonnet 4.5가 약간 앞서며, Google의 Gemini 3 Pro(Preview)는 더 넓은 범위의 멀티모달·에이전트형 파워하우스로, 시각적 컨텍스트, 도구 사용, 긴 컨텍스트 처리, 심층 에이전트 워크플로가 중요할 때 특히 강력합니다.
저는 현재 두 모델을 모두 사용하고 있으며, 개발 환경에서 각각 다른 장점을 보입니다. 이제 이 글에서 둘을 비교하겠습니다.
Gemini 3 Pro는 Google AI Ultra 구독자와 유료 Gemini API 사용자에게만 제공됩니다. 하지만 좋은 소식이 있습니다. 올인원 AI 플랫폼인 CometAPI가 Gemini 3 Pro를 통합했으며 무료로 체험할 수 있습니다.
Gemini 3 Pro Preview란 무엇이며 핵심 기능은?
개요
Gemini 3 Pro(초기에는 gemini-3-pro-preview로 제공)는 Google/DeepMind의 Gemini 3 패밀리 최신 “프런티어” LLM입니다. 도구 사용, 서브에이전트 오케스트레이션, 외부 리소스 상호작용이 가능한 에이전트형 워크플로에 최적화된 고추론 멀티모달 모델로 포지셔닝됩니다. 더 강한 추론, 멀티모달(이미지, 비디오 프레임, PDF) 처리, 내부 “사고” 깊이에 대한 명시적 API 제어를 강조합니다.
주요 기능 요약(개발자 관점)
- 에이전트형 도구 사용: 내장 함수 호출과 도구(코드 실행, 웹 그라운딩, 파일 & URL 컨텍스트, 터미널/도구 사용).
- Thinking / Chain-of-Thought 지원: 다단계 계획을 위한 “사고” 프리미티브와 다단계 추론을 더 명시적으로 만드는 내부 사고 시그니처.
- 멀티모달 입력/출력: 텍스트, 이미지, 오디오, 비디오, 구조적 출력과 장문맥 처리.
- 코드 실행 도구 & IDE 통합: 호스팅된 코드 실행 도구와 IDE 및 Google의 새로운 에이전트형 IDE인 Antigravity와의 통합. Antigravity는 현재 퍼블릭 프리뷰.
- 고/확장 사고 제어(
thinking_level매개변수)로 지연 시간과 더 깊은 내부 추론 간 트레이드오프 조절. Gemini 3 Pro의 기본값은high. - 세분화된 멀티모달 제어(
media_resolution)로 이미지/비디오 충실도와 비용을 튜닝 — 스크린샷의 작은 텍스트를 읽거나 프레임 분석이 필요할 때 유용.
코딩에서 Gemini 3 Pro가 강한 지점
- 에이전트형 개발: 에디터/터미널/브라우저 전반의 다단계 작업 오케스트레이션. Antigravity의 아티팩트 시스템과 Gemini 도구 조합은 대형 기능 개발과 자동화에 뛰어납니다.
- 비주얼 + 코드 조합: 스크린샷으로 UI 버그 수정, UI 테스트 하니스 생성, 디자인 이미지를 코드로 변환 등 이미지-투-코드 이해가 강력합니다.
Claude Sonnet 4.5란 무엇이며 주요 기능은?
Claude Sonnet 4.5는 Anthropic의 2025년 릴리스로, 코딩·에이전트형 워크플로·“컴퓨터 사용”(도구, 브라우저, 터미널, 스프레드시트 제어 등)에 가장 강한 모델로 소개됩니다. 편집 능력, 도구 성공률, 확장 사고, 장시간 에이전트 일관성(내부 데모에서 30시간+ 자율 작업), 이전 세대 대비 낮은 코드 편집 오류율을 강조합니다. Anthropic은 Sonnet 4.5를 “최고의 코딩 모델”이라 칭하며, 편집 신뢰성과 장기 과제 일관성에서 큰 향상을 내세웁니다.
주요 기능(개발자 관점)
- 실세계 엔지니어링 벤치에서 높은 코딩 정확도: Anthropic은 SWE-bench Verified에서 SOTA를 보고하며, 편집 오류율과 도구 기반 에이전트 성공의 큰 개선을 주장합니다.
- 에이전트형 및 컴퓨터 사용 개선: Sonnet 4.5는 여러 도구(bash, 파일 편집, 브라우저 자동화)를 실행하고 Claude Agent SDK로 서브에이전트를 오케스트레이션하도록 설계되었습니다. 내부 평가에서 “30시간+”의 연속 다단계 작업을 강조합니다.
- 대형 컨텍스트 윈도우: 대부분 고객에게 기본 200k 토큰, 상위 티어 조직에는 1M 토큰 컨텍스트 베타(동일 1M 기능을 Gemini도 프리뷰로 제공).
- 코드 실행 도구 & 파일 API: 제품 내 및 API 도구로 안전한 코드 실행, 파일 생성/편집, 테스트-실행 루프 지원.
코딩에서 Sonnet 4.5가 강한 지점
- 모델의 알고리즘적 엄밀성과 장기 안정성이 중요하게 작용하는 순수 소프트웨어 엔지니어링 벤치와 구조화된 코드 작업(유닛 테스트 생성, 리포지토리 전역 리팩터링).
- Claude Code 같은 코드 우선 CLI 및 “코드 어시스턴트” 플로(터미널 긴밀 통합과 리포지토리 스캔을 즉시 제공).
간단 비교 표
| 항목 | Gemini 3 Pro (Preview) | Claude Sonnet 4.5 |
|---|---|---|
| 모델/출시 상태 | gemini-3-pro-preview — Google / DeepMind 프런티어 모델(프리뷰). 2025년 11월 출시(프리뷰). | claude-sonnet-4-5 — Anthropic Sonnet 클래스 프런티어 모델(GA / 2025년 9월 29일 발표). |
| 타깃 포지셔닝(코딩 & 에이전트) | 추론 + 멀티모달 + 에이전트형 워크플로에 중점을 둔 범용 프런티어 모델; Google의 최상위 코딩/에이전트 모델로 포지셔닝. | 코딩, 장기 에이전팅 및 컴퓨터 사용에 특화(Anthropic의 “코딩 & 복잡한 에이전트에 최적”). |
| 핵심 개발자 기능 | 더 깊은 내부 추론을 위한 thinking_level 제어; Google 빌트인 도구 통합(검색 그라운딩, 코드 실행, 파일/URL 컨텍스트); 텍스트+이미지 워크플로를 위한 전용 이미지 변형. | Agent SDK, VS Code 통합(Claude Code), 파일 & 코드 실행 도구, 장기 에이전트 개선(수시간 실행 테스트). 반복적 편집/실행/테스트 워크플로와 체크포인팅에 중점. |
| 컨텍스트 창(입력 / 출력) | gemini-3-pro-preview에 대해 1,000,000 토큰 입력 / 64k 토큰 출력 | 1,000,000 토큰 입력 / 64k 토큰 출력 |
| 가격(공개 기준) | <200k 티어 기준 $2 / $12 per 1M tokens(입력/출력); >200k는 더 높은 요율(>200k에서 $4 / $18 예시). | Anthropic 공개 기준: Sonnet 4.5 $3 / $15 per 1M tokens(입력/출력). |
| 멀티모달 기능(비전/비디오/오디오) | 완전한 멀티모달 지원: 텍스트, 이미지, 오디오, 비디오 프레임 + 이미지/비디오 해상도 파라미터 구성 가능; 텍스트+이미지 워크플로를 위한 gemini-3-pro-image-preview 전용. UI/스크린샷 OCR·시각 정보 추출에 강점. | 비전(텍스트+이미지) 입력을 지원하며 에이전트 흐름 내 시각 컨텍스트 사용에 중점; 이미지 생성 동등성보다 에이전트 통합에 방점. |
| 장기 호라이즌 에이전트 성능 및 지속성 | 다단계 내부 추론을 위한 “사고” 프리미티브; 강한 수학/추론 & 멀티모달 심층 추론. 복잡한 알고리즘 작업 분해에 능함. 단일 응답 고난도 추론 + 멀티모달 분석에 최적. | 장기 에이전트 일관성을 강조 — 내부 테스트에서 Sonnet 4.5가 30시간+ 동안 일관된 다단계 도구 사용을 유지. 지속 자동화와 CI형 에이전트 워크플로에 적합. |
| 코딩 출력 품질(수정, 테스트, 신뢰성) | 매우 강한 단일샷 추론 + 코드 생성; Google 도구를 통한 코드 실행 내장; 벤더 주장 기준 알고리즘 벤치에서 높은 점수. 시각 스펙 + 코드 혼합 워크플로에서 실용적 이점. | 반복적 편집→실행→테스트 루프에 특화; Sonnet 4.5는 “패칭” 신뢰성 향상(리젝션 샘플링/스코어링으로 견고한 패치 선택)과 체크포인트·테스트 중심 워크플로 지원을 강조. |
두 모델의 아키텍처와 핵심 역량은 어떻게 다른가?
아키텍처와 설계 의도(하이레벨)
Gemini 3 Pro: 멀티모달 범용 파운데이션 모델로 제시되며 “사고”와 도구 사용을 위한 명시적 엔지니어링을 갖춤. 설계 초점은 심층 추론, 비디오/오디오 이해, 내장 함수 호출 및 코드 실행 환경을 통한 에이전트 오케스트레이션. Google은 Gemini 3 Pro를 가족 중 “가장 지능적” 모델로 규정하며 코드 외 광범위한 작업에 최적화되었다고 설명(에이전트형 코딩도 우선순위).
Claude Sonnet 4.5: 에이전트형 워크플로와 코드에 특히 최적화. 지시 준수, 도구 신뢰성, 편집/수정 숙련도, 장기 상태 관리에 집중. 파괴적/환각성 편집을 최소화하고 현실 세계 컴퓨터 상호작용의 견고성을 높이는 데 주안점.
요약: Gemini 3 Pro는 멀티모달 추론과 에이전트 통합에 강한 최상급 제너럴리스트로, Sonnet 4.5는 편집/수정 보증을 강화한 코딩·에이전트 특화형입니다.
도구와 통합
- Gemini: 검색 그라운딩, 파일 검색, 코드 실행, 전용 이미지/비디오 파라미터 등 Google 빌트인 도구 세트; 내부 연산/지연 트레이드오프를 제어하는
thinking_level. Google 인프라와의 심층 통합으로 Google Cloud를 쓰는 팀에 편리. - Claude: 견고한 Agent SDK와 안정적 장기 실행에 초점(Sonnet의 30시간+ 일관성 보고). 코드 실행, 파일 API 제공, Claude Code와 VS Code 확장에서 “체크포인트” 편집 UX — 반복적 개발 워크플로를 실질적으로 개선.
기술 사양과 벤치마크는 무엇을 말하나?
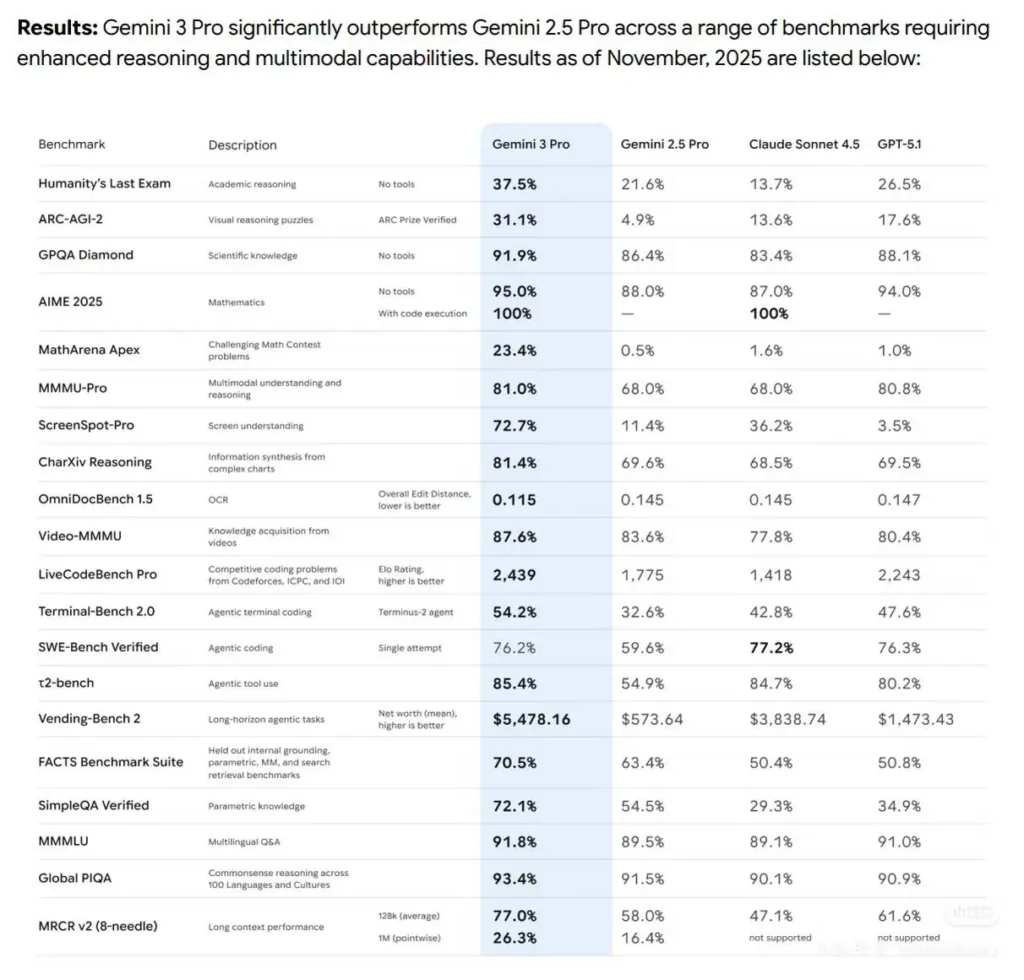
벤치마크는 평가자와 구성(단일 시도 vs 다중 시도, 도구 접근, 확장 사고 설정)에 따라 약간 달라집니다. 아래는 코딩 능력에 대한 벤치마크 데이터 분석입니다.
SWE-bench Verified(실세계 소프트웨어 엔지니어링 테스트)
Claude Sonnet 4.5(Anthropic 보고): 77.2%(200k 사고 예산; 1M 구성에서 78.2%). 병렬 시도/리젝션 샘플링을 사용한 고연산 점수 82.0%도 보고.
Gemini 3 Pro(DeepMind 보고/관련 리더보드): SWE-bench 단일 시도에서 ~76.2%(벤더 표). 공개 리더보드는 사례에 따라 Gemini와 Sonnet이 근소 차로 앞서거니 뒤서거니 합니다.
Terminal-Bench & 에이전트형 과제
Gemini 3 Pro: 터미널/에이전트형 벤치(벤더 표)에서 강한 성능(예: Terminal-Bench 54.2%)으로 Sonnet의 에이전트 강점과 경쟁.
Sonnet 4.5: 에이전트 도구 오케스트레이션에 탁월(Anthropic은 OSWorld와 터미널형 벤치에서의 큰 개선과 더 긴 연속 작업 성능을 강조).
요약: 최신 코드 이해/생성 벤치에서 두 모델은 매우 근접합니다. 소프트웨어 엔지니어링 검증 스위트 일부에서는 Sonnet 4.5가 소폭 우위(Anthropic 공개 수치), 반면 Gemini 3 Pro는 멀티모달과 일부 코딩 대회형 리더보드에서 선도하는 경우가 많습니다. 도구 접근, 컨텍스트 크기, 사고 예산 등 구성에 따라 점수가 크게 달라지므로 반드시 동일 조건으로 검증하세요.
멀티모달 능력 비교
비전 & 이미지 처리
- Gemini 3 Pro: 이미지/비디오
media_resolution(이미지/프레임별 토큰 예산) 같은 정교한 멀티모달 제어, 이미지 생성/편집(별도 이미지 프리뷰 모델), OCR/시각 디테일을 위한 명시적 가이드. 스크린샷, UI 목업, 비디오 프레임을 읽어 코드로 전환해야 하는 코딩 작업에서 특히 강력. - Claude Sonnet 4.5: 텍스트+이미지 멀티모달을 지원하고, Claude 앱에서 시각 워크플로를 제공. Sonnet 4.5의 초점은 원시 이미지 합성 동등성보다 에이전트 흐름 내 시각 컨텍스트 통합.
코딩에서 멀티모달이 중요할 때
워크플로가 UI 스크린샷, 이미지 속 디자인 스펙, 분석이 필요한 비디오 워크스루에 크게 의존한다면, Gemini의 전용 이미지 해상도 제어와 이미지 생성 변형이 실무적 우위가 될 수 있습니다. 파이프라인이 에이전트 주도 자동화(클릭, 명령 실행, 파일 편집을 여러 도구에 걸쳐 수행)라면 Claude의 Agent SDK와 코드 실행 도구가 일급입니다.
고급 추론 & 장기 계획 — 어느 쪽이 더 나은가?
Sonnet 4.5: 지속력과 정렬(Alignment)
Sonnet 4.5는 복잡한 다단계 과제(계획, 리서치, 소송 문서 작성, 장시간 코드 작업)에서 30시간 이상 일관된 작업을 유지할 수 있습니다. 이 지속력과 Anthropic의 정렬 강조는 목표 추적과 안전한 행동 유지가 필요한 종단 간 자동화에 매력적입니다.
Gemini 3 Pro: 심층 추론 + 에이전트 오케스트레이션
Gemini 3 Pro는 “Deep Think” 변형과 다단계 계획을 위한 더 풍부한 내부 사고 API를 도입했으며, Google의 에이전트형 IDE와 결합됩니다. 실제로 Gemini는 도구(에디터, 셸, 웹) 전반에서 에이전트 단계를 계획하고 실행할 수 있습니다. 자동화에 외부 도구 접근과 아티팩트 생성을 요구한다면 Gemini의 통합 에이전트 도구(Antigravity)가 큰 장점입니다. 참고: Deep Think는 지연과 깊이 간 트레이드오프가 있습니다.
장기 계획 비교: Vending-Bench 2
“Vending-Bench 2” 시뮬레이션 테스트에서 Gemini 3는 가상 회사를 1년간 운영하며 수익성을 유지해 Claude 4.5를 앞질렀습니다. 단기 테스트에서는 Gemini 3 Pro와 Claude 4 Sonnet의 데이터가 비슷했지만, 테스트 기간이 길어질수록 차이가 두드러졌습니다.
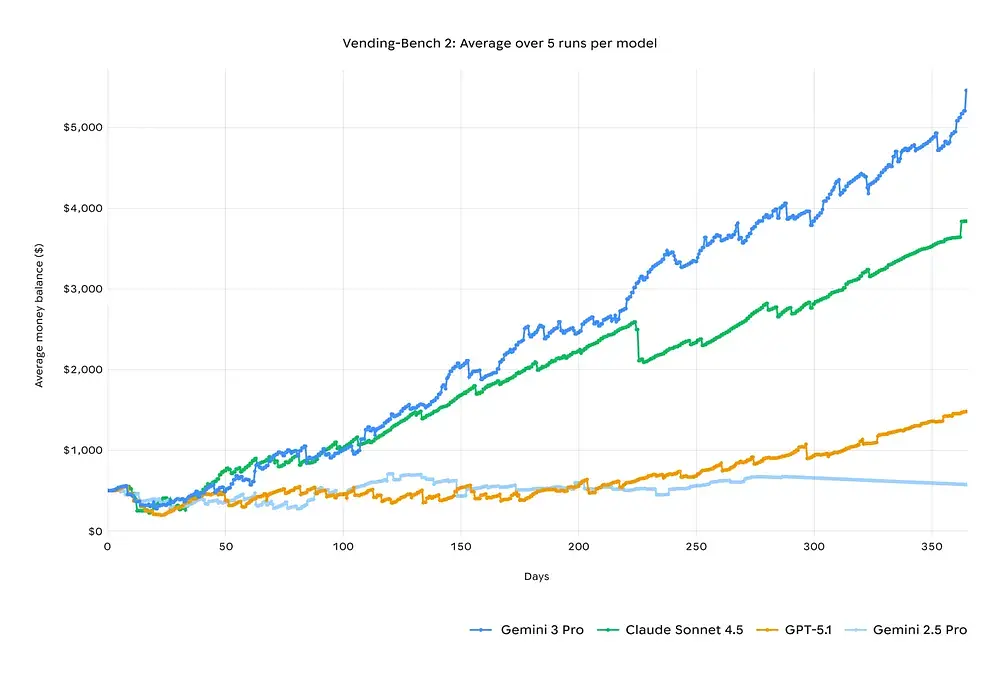
실무적 차이
- 단일샷 고난도 추론 작업(복잡한 알고리즘 디버깅, 코드에 내재된 심층 논리 증명)에서는 Gemini의
thinking_level과 Deep Think가 더 깊은 단일 응답을 약속합니다. - 장시간, 도구 주도 자동화(지속 에이전트가 많은 명령을 실행하고, 테스트 작성·반복·상태 관리)를 위해서는 Claude Sonnet 4.5의 장기 초점과 Agent SDK가 강력한 차별점입니다.
개발자 관점에서 API 접근성과 가격 비교
Gemini 3 Pro(Google) — 접근과 가격
- 접근: Gemini 3 Pro 프리뷰는 Google AI Studio와 Vertex AI(Model Garden)에서 제공. SDK는 Python/JS/Go/기타용 google-genai, 마이그레이션을 쉽게 하는 OpenAI 호환 레이어, REST 엔드포인트, 함수 호출/코드 실행 도구 포함. Antigravity는 프리뷰에서 Gemini 3 Pro를 사용하는 IDE 표면을 제공합니다.
- 가격: Google 문서의 프리뷰 가격 — <200k 티어 $2 / $12 per 1M tokens(입력/출력), >200k에서는 더 높은 요율(예: $4 / $18).
Claude Sonnet 4.5 — 접근과 가격
- API & SDK: Anthropic은 Claude API, Claude Agent SDK로 에이전트형 워크플로 구축, 파일 API, 코드 실행 도구 제공(VS Code 네이티브 확장, Claude Code 개선, “체크포인트” 기능).
- 가격: 기본 200k 토큰 컨텍스트, 엔터프라이즈에 1M 토큰 컨텍스트 베타; 가격은 $3 / $15 per 1M tokens(입력/출력).
개발자로서 가장 저렴한 모델이 아니라, 과제와 모델 특성에 따라 선택해야 합니다. 두 모델로 모두 해결 가능한 작업이라면 컨텍스트에 따라 결정하세요.
두 모델을 동시에 사용하고 싶다면 CometAPI를 추천합니다. Gemini 3 Pro Preview API와 Claude Sonnet 4.5 API를 모두 제공하며, 공식 가격의 20% 수준으로 책정되어 있습니다.
| Gemini 3 Pro Preview | GPT-5.1 | |
| Input Tokens | $1.60 | $2.4.00 |
| Output Tokens | $9.60 | $12.00 |
마무리 생각
Gemini 3 Pro(Preview)와 Claude Sonnet 4.5는 2025년 말 기준 코딩 어시스턴트로서 모두 최첨단 선택지입니다. Sonnet 4.5는 특정 소프트웨어 엔지니어링 검증 벤치와 장기 과제 지구력에서 약간 우위를 보이는 반면, Gemini 3 Pro는 에디터/터미널/브라우저 환경에서 실행 가능한 더 강한 멀티모달 이해와 심층 에이전트 도구를 제공합니다. 최적의 선택은 주된 니즈가 순수 코드 추론·검증인지(Sonnet), 멀티모달·에이전트·도구 보강 개발인지(Gemini)에 달려 있습니다. 엔터프라이즈급 배포에서는 많은 팀이 단계별 워크플로에서 각 모델의 강점을 사용하는 하이브리드 접근을 합리적으로 채택할 것입니다.
개발자는 CometAPI를 통해 Gemini 3 Pro Preview API와 Claude Sonnet 4.5 API에 접근할 수 있습니다. 시작하려면 Playground에서 CometAPI의 모델 기능을 탐색하고, 상세한 지침은 API 가이드를 확인하세요. 접근 전에 CometAPI에 로그인하고 API 키를 발급받았는지 확인하십시오. CometAPI는 통합을 돕기 위해 공식 가격보다 훨씬 낮은 가격을 제공합니다.
Ready to Go?→ Gemini 3 pro 및 GPT-5.1 모델 무료 체험