

I det raskt utviklende AI-landskapet utmerker GLM-5.2 fra Z.ai (Zhipu AI) seg som en kraftig modell med åpne vekter, optimalisert for agentbasert koding, oppgaver med lang tidshorisont og pålitelighet i produksjon. Med et brukbart kontekstvindu på 1M tokens, to resonneringsmoduser (High og Max) og sterk ytelse til en brøkdel av kostnaden for lukkede frontier-modeller, blir den raskt et førstevalg for utviklere som bygger autonome agenter, IDE-integrasjoner og komplekse programvareutviklingsarbeidsflyter.
Enten du er en solo-utvikler som prototyper agenter, en CTO som vurderer kostnadseffektiv skalering, eller en AI-produktsjef som integrerer multimodal-kompetent resonnering i SaaS, vil det å beherske GLM-5.2-API-et gi betydelige fordeler.
Hva er GLM-5.2?
GLM-5.2 er Z.ai’s (Zhipu AI) nyeste flaggskipmodell med åpne vekter, en Mixture-of-Experts (MoE)-modell, lansert i midten av juni 2026. Med omtrent 753 milliarder totale parametere (omtrent 40B aktive per token), et stabilt kontekstvindu på 1 million tokens, MIT-lisens og sterk ytelse på koding med lang tidshorisont og agentoppgaver, posisjonerer den seg som et konkurransedyktig alternativ til lukkede frontier-modeller som GPT-5.5, Claude Opus 4.8 og Gemini-varianter—til en brøkdel av kostnaden for mange arbeidslaster.
GLM-5.2-arkitektur og tekniske spesifikasjoner
GLM-5.2 bygger videre på GLM-familien med viktige oppgraderinger for arbeid med lang tidshorisont.
- Parametere: ~753B totalt i MoE-design (aktive parametere ~40B per token). Dette gir enorm kapasitet med effektiv inferens.
- Kontekstvindu: 1,048,576 tokens (1M). Maks utdata typisk opptil 128K–131K tokens.
- Presisjon: BF16 (med FP8-varianter for lettere utrulling).
- Nøkkelinnovasjon – IndexShare: Gjenbruker én indekseringskomponent på tvers av grupper av sparse attention-lag, og reduserer FLOPs per token med opptil 2,9x ved 1M kontekst. Dette gjør inferens med lang kontekst praktisk uten eksploderende kostnader eller ventetid.
- Resonneringsmoduser: "High" (balansert) og "Max" (dypest, anbefalt for koding). Tenkning kan deaktiveres for enkle oppgaver.
- Modaliteter: Primært tekst/kode (ingen innebygd visjon bekreftet i basisutgaven).
- Lisens: MIT – fullt åpen for nedlasting, modifikasjon og kommersiell bruk.
Denne åpenheten og effektiviteten gjør GLM-5.2 ideell for team som prioriterer personvern, tilpasning eller kostnadskontroll.
GLM-5.2 vs GLM-5.1
| Område | GLM-5.1 | GLM-5.2 | Praktisk forskjell |
|---|---|---|---|
| Kontekstvindu | Rundt 200K på vanlige hostede ruter | 1M | GLM-5.2 er langt bedre egnet for prosjektomfattende kontekst |
| Resonneringsinnsats | Mindre fleksibel | High og Max | Bedre kontroll over kostnad, ventetid og kvalitet |
| Terminal Bench 2.1 | 63.5 i den publiserte tabellen | 81.0 | Stor forbedring i terminal-/agentoppgaver |
| SWE-bench Pro | 58.4 | 62.1 | Moderat men meningsfull forbedring på repo-nivå |
| FrontierSWE | 30.5 | 74.4 | Svært stor forbedring i langhorisont-ingeniøroppgaver |
| Open-weight-tilnærming | Open-weight GLM-familie | Open-weight MIT-utgivelse | Tilsvarende åpenhet, sterkere posisjonering for lang kontekst |
Hvis din nåværende GLM-5.1-arbeidsflyt mest er korte samtaler eller enkel kodegenerering, endrer ikke oppgraderingen nødvendigvis alt. Dersom arbeidsflyten din omfatter store kodebaser, flerstegs koding med agenter eller langvarig oppgaveutførelse, er GLM-5.2 langt mer relevant.
GLM-5.2 vs Claude Opus, GPT-5.5, Gemini og DeepSeek
Den reneste måten å sammenligne GLM-5.2 på er etter oppgavetype:
| Oppgavetype | GLM-5.2-posisjon |
|---|---|
| Koding med lang tidshorisont | En av de sterkeste open-weight-alternativene; nær frontier-lukkede modeller på utvalgte benchmarker |
| Generell resonnering | Sterk, men ikke alltid foran de beste lukkede modellene |
| Verktøybruk | Sterk MCP-Atlas- og HLE-with-tools-ytelse |
| Matematiske konkurranser | Svært sterk AIME 2026-score i publiserte resultater |
| Visjon | Ikke riktig modell; bruk en visjonsmodell |
| Lavkost klassifisering i høyt volum | Vanligvis overdimensjonert; bruk en mindre modell |
| Egenhosting og tilpasning | Sterkere alternativ enn lukkede API-only-modeller |
For team er det beste svaret som regel ikke «erstatt hver modell med GLM-5.2». Det bedre svaret er «ruter GLM-5.2 til oppgavene der den har en fordel». Det er én grunn til at en samlet API-leverandør som CometAPI kan være praktisk. Den lar deg sammenligne og rute modeller etter arbeidslast uten å bygge om hver integrasjon.
Prising: Rimelig kraft i stor skala
GLM-5.2 tilbyr overbevisende økonomi, spesielt for token-tunge oppgaver med lang kontekst.
- API-prising (via Z.ai/OpenRouter/etc.): $1.40 / 1M input tokens, $4.40 / 1M output tokens. Cache-lesing ned til $0.26/1M i noen ruter.
- Abonnement for GLM Coding Plan (inkluderer full tilgang, ingen ekstra for 5.2):
- Lite: ~$10–12.60/måned (lett iterasjon).
- Pro: ~$30/måned.
- Max/Team: Høyere kvoter for tung bruk.
Eksempel på kostnadsbesparelse: For en lang agentsesjon med 500K kontekst + utdata kan GLM-5.2 være 4–5x billigere enn Claude-ekvivalenter, samtidig som den håndterer større kontekster nativt.
Anbefaling fra CometAPI: Få tilgang til GLM-5.2 (og 500+ andre modeller) via CometAPIs enhetlige, OpenAI-kompatible endepunkt til konkurransedyktige priser. Én nøkkel, ingen leverandørlåsing, testkreditter ved registrering. Ideelt for å sammenligne GLM-5.2 side om side med Claude/GPT i produksjon. Besøk cometapi for sømløs integrasjon.
1M kontekstvindu: Den fremste funksjonen
1M-konteksten er «solid» og tapsfri i praksis for arbeid i prosjektskala—langt utover markedsføringshype. Den gjør det mulig å holde hele mellomstore til store kodebaser i kontekst, noe som reduserer oppsummeringsoverhead og feilakkumulering i agenter.
Tips for effektiv bruk:
- Bruk identifikatoren glm-5.2[1m].
- Angi maks antall tokens hensiktsmessig; overvåk i produksjon.
- Kombiner med verktøy/MCP for dynamisk datahenting.
Tidlige tester bekrefter stabilitet forbi 200K, et vanlig sviktpunkt for andre «langkontekst»-modeller.
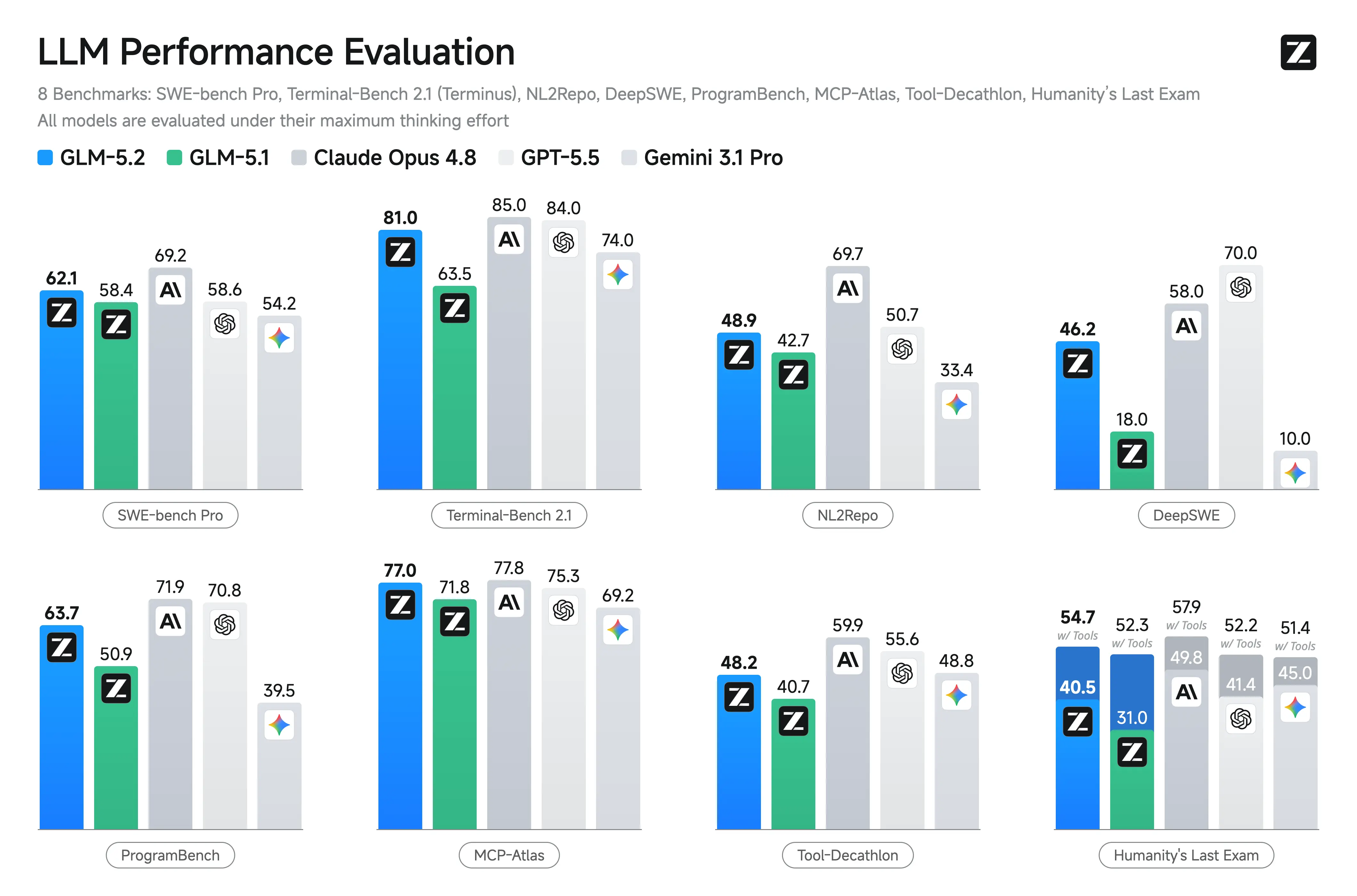
Grunnleggende ytelse og benchmarker
Z.ai og uavhengige rapporter fremhever GLM-5.2s styrker i koding og agentscenarier. Den viser betydelige gevinster over GLM-5.1 og konkurransedyktige resultater mot lukkede modeller på oppgaver med lang horisont.
Viktige rapporterte benchmarker (Z.ai og tredjepartsaggregater):
- Terminal-Bench 2.1: 81.0 (opp fra GLM-5.1s 62.0) – Utmerket for terminal-/agentoperasjoner.
- SWE-bench Pro: 62.1 (tangerer/forbi GPT-5.5 på 58.6).
- MCP-Atlas: 77.0 (nær Claude Opus 4.8).
- Humanity’s Last Exam (med verktøy): 54.7.
Andre ledende resultater: På topp eller nær toppen blant åpne modeller på FrontierSWE, PostTrainBench, SWE-Marathon. Sterk på AIME 2026 (~99.2) og GPQA-Diamond (91.2).
Alternativer for tilgang til GLM-5.2 API
Det finnes to vanlige måter å få tilgang til GLM-5.2 fra en applikasjon.
Alternativ 1: Bruk Z.ai direkte
Den direkte ruten er å bruke den offisielle Z.ai-API-en. Dette kan være riktig valg når teamet ditt ønsker et direkte forhold til modellleverandøren, kun bruker Z.ai-modeller, eller trenger leverandørspesifikke kontroller så snart de slippes.
Avveiningen er operasjonell. Hvis produktet ditt bruker flere modellsuiter, kan du måtte vedlikeholde separate SDK-konfigurasjoner, faktureringsflyter, failover-logikk, prisnormalisering og observabilitetskonvensjoner. For et forskningsprosjekt kan det være akseptabelt. For en SaaS i produksjon kan integrasjonsflaten vokse raskt.
Alternativ 2: Bruk GLM-5.2 via CometAPI
CometAPI gir tilgang til GLM-5.2 gjennom en samlet API-gateway. Den praktiske fordelen er at utviklere kan kalle ulike AI-modeller via ett OpenAI-kompatibelt grensesnitt, i stedet for å bygge én integrasjon per leverandør. Du holder koden nærmere OpenAI-SDK-mønsteret, setter modellen til glm-5.2, og ruter forespørsler gjennom CometAPI.
Dette er nyttig for startups og produktteam som ønsker å:
- Teste GLM-5.2 opp mot andre modeller uten å bygge om backend
- Holde én API-nøkkel og ett faktureringslag for flere modeller
- Flytte raskere fra benchmark til prototype til produksjon
- Implementere modell-fallback eller ruteringsstrategier
- Sammenligne kost og kvalitet på tvers av leverandører
- Bruke kjente OpenAI-lignende forespørselmønstre
Registrer deg på CometAPI.com for umiddelbare testkreditter og OpenAI-kompatible endepunkter som skjuler leverandørens særegenheter.
- Skaff API-nøkkelen din.
- Sett miljøvariabler (sikkerhetsmessig beste praksis):
bash
export GLM_API_KEY="your_key_here"
export BASE_URL="https://api.cometapi.com/v1" # or direct Z.ai endpoint
Slik gjør du ditt første GLM-5.2 API-kall
cURL-eksempel (hurtigtest):
bash
curl https://api.z.ai/api/paas/v4/chat/completions \
-H "Authorization: Bearer $GLM_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5.2",
"messages": [
{"role": "system", "content": "You are an expert full-stack engineer."},
{"role": "user", "content": "Write a FastAPI endpoint for user authentication with JWT."}
],
"temperature": 0.7,
"max_tokens": 2048
}'
Vanlige bruksområder for GLM-5.2
GLM-5.2 er en sterk kandidat for arbeidsflyter der lang kontekst, resonnering og verktøybruk kombineres.
| Bruksområde | Eksempelimplementering | Hvorfor GLM-5.2 kan passe |
|---|---|---|
| Utviklerassistent | Analyser feilrapporter, kodebiter, logger og tester | Krever resonnering på tvers av teknisk kontekst |
| Dokumentintelligens | Gå gjennom kontrakter, policyer, krav eller rapporter | Lange inndata og strukturert uttrekk |
| Forskningsagent | Les kilder, sammenlign påstander, produser sammendrag | Drar nytte av lang kontekst og siteringsdisiplin |
| Kundesupport-kopilot | Kombiner sakshistorikk, dokumentasjon, kontodata og policy | Trenger innhenting + verktøykalling |
| Assistent for AI-produktsjef | Syntetiser tilbakemeldinger, spesifikasjoner, bruksdata og roadmap-notater | Lang kontekst og forretningsresonnering |
| Sikkerhetsanalyse | Gå gjennom hendelsesrapporter, varsler og tiltak | Trenger nøye flerstegsresonnering |
| Salgsingeniørarbeid | Generer tekniske svar fra dokumentasjon og kundekrav | Nyttig i komplekse B2B-salgssykluser |
Det vanlige mønsteret er ikke «chatbot». Det vanlige mønsteret er arbeidsflytkomprimering. GLM-5.2 kan redusere tiden mellom rå informasjon og en nyttig beslutning.
Hvem bør bruke GLM-5.2?
GLM-5.2 passer godt for:
- Utviklere som bygger AI-kodeverktøy.
- SaaS-selskaper som legger til repo-bevisste assistenter.
- CTO-er som vurderer open-weight-alternativer til lukkede kodemodeller.
- AI-produktsjefer som tester arbeidsflyter med lang kontekst.
- Foretak med fremtidige behov for egenhosting eller datakontroll.
- Utviklerplattformer som trenger modellvalgfrihet.
- Team som jobber med store tekniske dokumenter, SDK-er eller kodebaser.
Det er spesielt attraktivt når det er kostbart å feile. Hvis en modells feil forårsaker ødelagte bygg, dårlige migreringer eller bortkastet utviklingstid, kan kostnaden ved å bruke en sterkere modell raskt forsvares.
Når bør du ikke bruke GLM-5.2
Ikke bruk GLM-5.2 som standard for:
- Korte og repeterende klassifiseringsoppgaver.
- Enkel tekstomskriving.
- Forståelse av bilder eller skjermbilder.
- Lavlatens autoutfylling der millisekunder teller.
- Arbeidsflyter der en mindre modell allerede presterer godt.
- Produkter som ikke kan tåle langvarig generering.
Målet er ikke å jage det største kontekstvinduet. Målet er å løse oppgaven med riktig profil for kvalitet, kost og ventetid.
Endelig vurdering
GLM-5.2 er en av de viktigste open-weight-modellutgivelsene for programvareteam i 2026. Kombinasjonen av 1M kontekst, sterke kode-benchmarker, High- og Max-resonneringsmoduser, støtte for funksjonskalling og MIT-lisens gjør den til et seriøst alternativ for kodeagenter og AI-arbeidsflyter med lang horisont.
For team som vil prøve raskt, er CometAPI et pragmatisk tilgangslag. Du kan kalle GLM-5.2 via et OpenAI-kompatibelt endepunkt, sammenligne den med andre ledende modeller, overvåke bruk og bygge en ruteringsstrategi uten å bygge om stakken rundt én leverandør. Start med en liten, privat evaluering, mål kost per løst oppgave og flytt GLM-5.2 i produksjon bare der styrkene med lang kontekst tydelig lønner seg.
Klar til å teste GLM-5.2 i din egen app? Utforsk GLM-5.2 on CometAPI, opprett en API-nøkkel og kjør din første OpenAI-kompatible forespørsel på minutter. Bruk den på en ekte oppgave i et repo, ikke en lekeprøve, og sammenlign resultatet mot den nåværende modellstakken din.