

Google zaprezentowało Gemini 3.5 Flash 19 maja 2026 r. podczas I/O, pozycjonując je jako wysoko‑inteligentny, zoptymalizowany pod kątem szybkości model do utrzymywania czołowej wydajności w przepływach agentowych, programowaniu i zadaniach multimodalnych. Bazuje na fundamencie Gemini 3 Flash z ulepszonymi „poziomami myślenia”, równoważącymi jakość, koszt i opóźnienie.
Ten kompleksowy przewodnik obejmuje wszystko: czym jest Gemini 3.5 Flash, jego kluczowe funkcje, szczegółową wydajność w benchmarkach, ceny, porównania z GPT-5.5, Claude 4.7/4.6 i nie tylko. Jako wiodący agregator API AI, CometAPI pomaga deweloperom uzyskać dostęp do Gemini 3.5 Flash (i konkurentów) z ujednoliconymi cenami, uproszczoną integracją i narzędziami do optymalizacji kosztów.
Czym jest Gemini 3.5 Flash?
Gemini 3.5 Flash bazuje na fundamentach rozumowania Gemini 3 Flash, wprowadzając ulepszone „poziomy myślenia” (minimal, low, medium/default, high) do precyzyjnego strojenia kompromisu jakość–opóźnienie–koszt. To natywnie multimodalny model obsługujący tekst, obrazy, wideo, audio i dokumenty (w tym PDF), z oknem kontekstu 1M tokenów i maksymalnie 65K tokenów wyjściowych. Granica wiedzy to styczeń 2025.
Kluczowe wyróżniki względem wcześniejszych modeli Flash:
- Utrzymywana czołowa wydajność w zadaniach agentowych, programowaniu i długohoryzontowych.
- Zachowanie toku rozumowania: Automatycznie utrzymuje pośrednie wnioskowanie w wieloturach bez dodatkowych zmian w API.
- Zoptymalizowany pod skalę: Zaprojektowany do równoległego wykonywania agentowego, iteracyjnego kodowania i wieloetapowych przepływów korporacyjnych.
- Brak wsparcia dla computer use (na razie), ale duże ulepszenia w tool use i function calling.
Google określa go jako „najinteligentniejszy model Flash” do zastosowań produkcyjnych, przewyższający poprzedni Gemini 3.1 Pro w wielu agentowych i programistycznych benchmarkach przy zachowaniu szybkości poziomu Flash (często >280 tokenów wyjściowych/sek w testach).
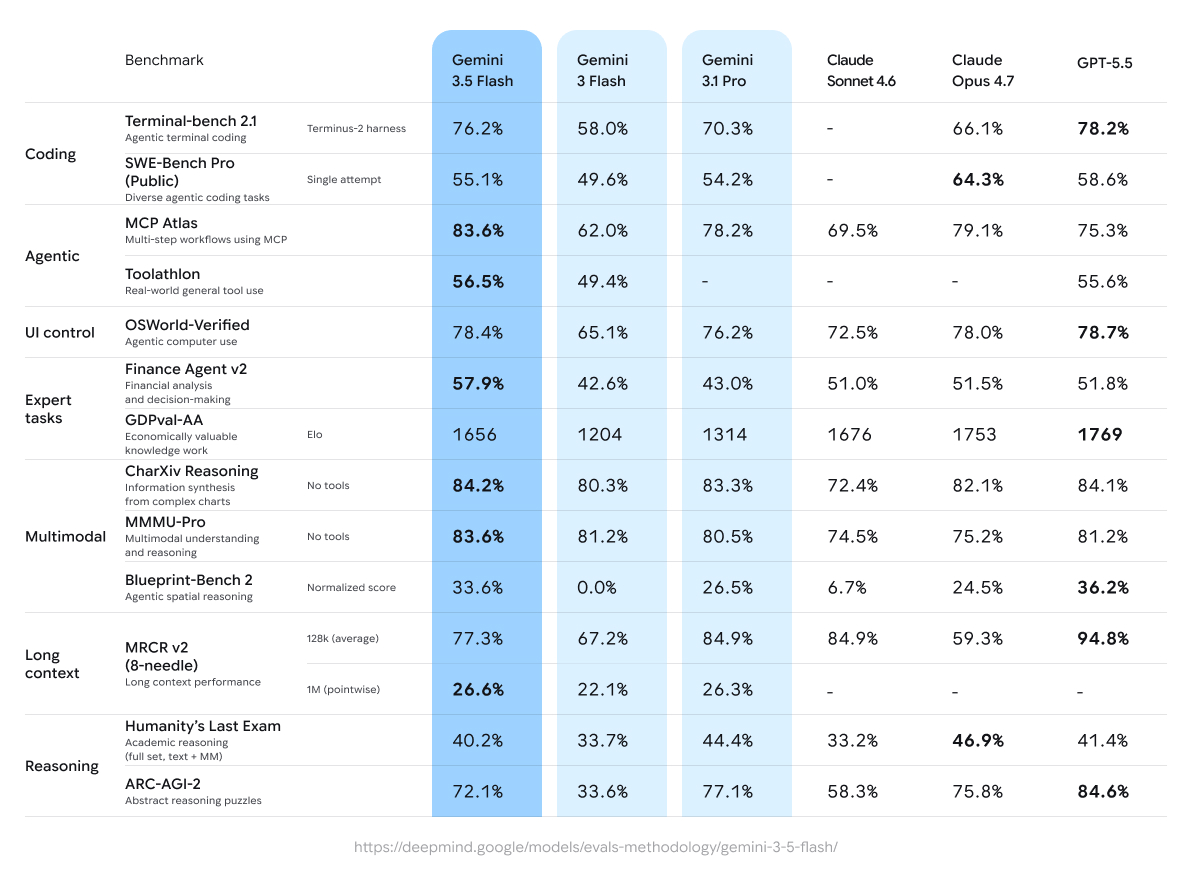
Gemini 3.5 Flash wyróżnia się w przepływach agentowych i programowaniu z inteligencją zbliżoną do Pro, przy zoptymalizowanym opóźnieniu i koszcie, osiągając wyniki jak 76.2% na Terminal-bench 2.1 i 83.6% na wieloetapowych zadaniach MCP Atlas.
Przełom w wydajności benchmarków
Niezależne testy potwierdzają, że zapewnia wydajność klasy Pro lub lepszą w zadaniach programistycznych/agentowych przy wyższej szybkości, choć całkowite koszty uruchomienia benchmarków rosną ze względu na większe zużycie tokenów w złożonych pętlach agentowych oraz 3× wzrost ceny względem wcześniejszych modeli Flash.
Gemini 3.5 Flash wykazuje silne wzrosty względem poprzedników, szczególnie w domenach agentowych i kodowania. Oto kluczowe wyniki z model card Google DeepMind i niezależnych ewaluacji (stan na maj 2026):
Wybrane benchmarki (Gemini 3.5 Flash vs. porównania):
Kodowanie:
- Terminal-bench 2.1 (agentowe kodowanie terminalowe): 76.2% (vs. Gemini 3 Flash 58.0%, Gemini 3.1 Pro 70.3%, GPT-5.5 78.2%)
- SWE-Bench Pro (publiczne, zróżnicowane kodowanie agentowe): 55.1% (vs. 49.6% dla 3 Flash, 54.2% dla 3.1 Pro)
Agentowe użycie narzędzi:
- MCP Atlas (wieloetapowe przepływy): 83.6% (silna przewaga)
- Toolathlon (realne ogólne użycie narzędzi): 56.5%
- Finance Agent v2: 57.9% (duże +15.3% względem 3 Flash)
Multimodalne:
- CharXiv (rozumowanie nad wykresami): 84.2%
- MMMU-Pro: 83.6% (przewodzi wielu konkurentom)
Rozumowanie i długi kontekst:
- Humanity’s Last Exam: 40.2%
- ARC-AGI-2: 72.1%
- MRCR v2 (128k): 77.3%; 1M kontekst silny na poziomie 26.6% (pointwise).
Artificial Analysis Intelligence Index: Gemini 3.5 Flash uzyskuje 55 (wysoki poziom myślenia), o 9 punktów więcej niż Gemini 3 Flash. Prowadzi na granicy Pareto inteligencja vs. szybkość, z zyskami w zadaniach agentowych i redukcją halucynacji (do 61% współczynnika halucynacji). Osiąga >280 tokenów wyjściowych/sek, ale generuje wyższe zużycie tokenów w pętlach agentowych.
Błyszczy w długim kontekście (mocny MRCR v2 i 1M pointwise), multimodalnym przywództwie (wykresy, dokumenty) oraz utrzymywanej wydajności agentowej z mniejszym marnotrawstwem tokenów w części przepływów (np. o 42% lepiej na benchmarku cyber przy 72% mniejszej liczbie tokenów).
Równowaga między szybkością a możliwościami agentowymi
Gemini 3.5 Flash wyróżnia się w kompromisie szybkość–inteligencja. Osiąga wysoką przepustowość (>280 tokenów/s), jednocześnie wspierając zaawansowane zachowania agentowe, takie jak wdrażanie podagentów, wykonywanie równoległe i szybka iteracja.
Domyślny nakład myślenia to teraz medium, zmieniony z high w Gemini 3 Flash Preview.
Poziomy myślenia pozwalają na precyzyjną kontrolę:
- Medium (domyślny): Najlepsza równowaga dla większości złożonych zadań kodowania i agentowych.
- High: Maksymalizuje głębokie rozumowanie dla najtrudniejszych problemów.
- Low/Minimal: Ultra‑niskie opóźnienie dla prostszych zapytań.
Google raportuje istotne zyski efektywności tokenowej w realnych scenariuszach agentowych (np. 72% redukcji w niektórych benchmarkach cyber względem wcześniejszych wersji), czyniąc model opłacalnym dla utrzymywanych, długotrwałych przepływów.
Kompromisy: Wyższa cena niż w poprzednich modelach Flash prowadzi do zwiększonych kosztów całkowitych w scenariuszach agentowych o dużej liczbie tokenów (5.5× koszt w indeksie inteligencji vs. Gemini 3 Flash z powodu cen + użycia).
Rozszerzone możliwości inteligentnych agentów
Gemini 3.5 Flash rozwija „agentową erę Gemini”. Kluczowe usprawnienia obejmują:
- Równoległe pętle wykonywania agentowego: Wdrażanie wielu podagentów dla złożonego rozwiązywania problemów.
- Iteracyjne kodowanie i prototypowanie: Szybkie eksplorowanie ścieżek rozwiązań z dynamicznym użyciem narzędzi.
- Długohoryzontowe, wieloetapowe przepływy: Obsługa rozbudowanych procesów korporacyjnych z zachowaniem toku rozumowania.
- Ulepszenia w użyciu narzędzi: Ścisłe dopasowanie odpowiedzi funkcji, multimodalne odpowiedzi funkcji oraz ograniczenie zbędnych wywołań dzięki lepszemu promptowaniu i niższym poziomom myślenia. Mocne zadania OSWorld i UI.
Zasila nowe agenty informacyjne Google, autonomiczne badania i potoki kodowania. W testach wewnętrznych wyróżnia się w budowaniu złożonych systemów i zarządzaniu projektami badawczymi.
Dla deweloperów nowe Interactions API (beta) upraszcza zarządzanie historią po stronie serwera, podobnie jak zaawansowane wzorce w innych ekosystemach.
Rekomendacja CometAPI: Użyj naszego ujednoliconego API, aby łączyć Gemini 3.5 Flash z wyspecjalizowanymi modelami (np. Claude do dogłębnego przeglądu kodu lub GPT do zadań kreatywnych) w systemach agentowych. Nasze funkcje trasowania i przełączania awaryjnego zapewniają niezawodność i oszczędności kosztów.
Multimodalne przywództwo
Google utrzymuje przywództwo w multimodalnym rozumieniu. Gemini 3.5 Flash natywnie przetwarza i wnioskuje na podstawie tekstu + obrazu + wideo + audio + dokumentów. Prowadzi lub plasuje się blisko czołówki w benchmarkach takich jak CharXiv, MMMU-Pro i zadania rozumienia wideo.
Przypadki użycia: Synteza wykresów/danych, analiza wideo, multimodalne wywołania funkcji (np. przetwarzanie obrazów w odpowiedziach narzędzi), oraz bogate media dla agentów. To czyni go idealnym do zastosowań w e‑commerce, tworzeniu treści, wizualizacji naukowej i nie tylko.
Cennik: ile kosztuje Gemini 3.5 Flash?
Cennik Gemini API (na 1M tokenów, przybliżone stawki globalne):
- Wejście (tekst/obraz/wideo/audio): $1.50
- Wyjście: $9.00
- Buforowanie kontekstu: $0.15 (znaczne oszczędności przy powtarzanych promptach)
To ~3× wzrost względem Gemini 3 Flash Preview ($0.50/$3), ale nadal konkurencyjny wobec skoku możliwości. Zbliża się do cen Gemini 3.1 Pro ($2/$12), oferując lepszą szybkość dla wielu obciążeń.
Poziomy Enterprise/Agent Platform mogą się różnić wraz z rabatami wolumenowymi i dodatkami. Buforowane wejścia i efektywne promptowanie (niższe poziomy myślenia, zoptymalizowane historie) znacząco pomagają kontrolować koszty.
To ~3× wzrost względem Gemini 3 Flash Preview ($0.50/$3), ale nadal konkurencyjny wobec skoku możliwości. Zbliża się do cen Gemini 3.1 Pro ($2/$12), oferując lepszą szybkość dla wielu obciążeń.
Bezpłatny poziom: Ograniczony dostęp przez Google AI Studio/aplikację Gemini; płatny w produkcji.
Cometapi Advantage: Uzyskaj dostęp do Gemini 3.5 Flash API wraz ze 100+ modelami z konkurencyjnymi stawkami, analizą użycia i narzędziami optymalizacji, aby minimalizować zużycie tokenów. Nasza platforma często zapewnia lepsze efektywne ceny dzięki inteligentnemu trasowaniu i batchowaniu. Ceny API są zwykle o 20% niższe niż oficjalne.
Gemini 3.5 Flash vs. GPT-5.5, Claude 4.7/4.6 i inni
Mocne strony Gemini 3.5 Flash:
- Szybkość + równowaga agentowa: Szybszy wnioskowanie niż większość modeli czołowych przy zmniejszającej się luce inteligencji.
- Multimodalność i długi kontekst: Natywne 1M kontekstu i przywództwo w wizji.
- Koszt przy dużej skali: Tańszy per token niż topowe Claude/GPT w wielu obciążeniach, zwłaszcza z buforowaniem.
- Ekosystem Google: Bezproblemowa integracja z Search, Workspace, Cloud.
Gdzie konkurenci mają przewagę:
- GPT-5.5 często prowadzi w surowym rozumowaniu (np. ARC-AGI) i może mieć silniejsze zdolności kreatywne/ogólne.
- Claude Opus 4.7/Sonnet 4.6 wyróżniają się w uważnym kodowaniu (wyższe SWE-Bench w niektórych przypadkach) oraz wyrafinowanym pisaniu/bezpieczeństwie.
- Efektywność tokenowa bywa zmienna; pętle agentowe mogą czynić 3.5 Flash droższym całościowo.
Porównanie na wysokim poziomie (przybliżone/wybrane metryki; zawsze weryfikuj najnowsze rankingi):
| Benchmark / Metryka | Gemini 3.5 Flash | GPT-5.5 | Claude Opus 4.7 / Sonnet 4.6 | Gemini 3.1 Pro | Uwagi |
|---|---|---|---|---|---|
| Terminal-bench 2.1 (kodowanie) | 76.2% | 78.2% | ~66% | 70.3% | Agentowe kodowanie |
| MCP Atlas (agentowe) | 83.6% | 75.3% | 79.1% / 69.5% | 78.2% | Wieloetapowe przepływy |
| GDPval-AA (Agentic Knowledge) | 1656 Elo | 1769 | 1753 | 1314 | Wartość ekonomiczna |
| MMMU-Pro (multimodalne) | 83.6% | 81.2% | ~75% | 80.5% | Silna przewaga Gemini |
| Intelligence Index (AA) | 55 | Wysoki (zmienny) | Konkurencyjny | Niższy | Pareto: szybkość/intel |
| Szybkość (tokeny/s) | >280 | Niższa | Zmienna | Wolniejszy | Przewaga Flash |
| Cena wej./wyj. ($/1M) | 1.50 / 9.00 | Wyższa | Wyższa (zwł. Opus) | 2/12 | Opłacalny „frontier” |
| Okno kontekstu | 1M | Konkurencyjne | Silne | 1M+ | Wszystkie klasy „frontier” |
Podsumowanie kompromisów:
- Gemini 3.5 Flash wygrywa w szybkości + multimodalności + efektywności agentowej na skalę.
- GPT-5.5 często przeważa w surowym rozumowaniu/szczytowym kodowaniu.
- Claude 4.7 Opus wyróżnia się w uważnym, wysokiej niezawodności kodowaniu, lecz przy wyższym koszcie/opóźnieniu.
Gemini często prowadzi lub remisuje w multimodalnych i wybranych zestawach agentowych, będąc szybszym i tańszym dla zastosowań o dużym wolumenie.
Jak uzyskać dostęp i zintegrować Gemini 3.5 Flash
Dostępne przez:
- Aplikację Gemini / Google AI Studio
- Gemini API (
gemini-3.5-flash) - Google Cloud Vertex AI / Enterprise Agent Platform
- Agregatory firm trzecich dla elastyczności wielodostawczej.
Rekomendacja CometAPI: Dla aplikacji produkcyjnych na Cometapi.com zintegruj raz za pomocą jednego klucza API, aby uzyskać dostęp do Gemini 3.5 Flash (i 500+ modeli od OpenAI, Anthropic, xAI itd.) z o 20–40% niższymi efektywnymi cenami, bez uzależnienia od jednego dostawcy i z łatwą podmianą modeli.
Przykładowa integracja jest prosta z oficjalnymi SDK lub ujednoliconym endpointem CometAPI — idealne do skalowania zadań programistycznych
Zastosowania i dobre praktyki
- Automatyzacja agentowa: Buduj odporne systemy wieloagentowe do badań, analizy danych lub obsługi klienta.
- Kodowanie i rozwój: Iteracyjne prototypowanie, debugowanie i generowanie pełnych potoków w Antigravity lub IDE.
- Aplikacje multimodalne: Analiza obrazów/wideo, rozumienie wykresów, generowanie treści.
- Przepływy korporacyjne: Długotrwałe procesy wieloetapowe z kontrolą kosztów dzięki buforowaniu i poziomom myślenia.
Wskazówki: Używaj pełnej historii konwersacji dla zachowania toku rozumowania. Zacznij od medium. Optymalizuj prompty, aby ograniczyć wywołania narzędzi. Monitoruj zużycie tokenów dla efektywności kosztowej.
Ograniczenia i uwagi
- Wzrost ceny wymaga starannej optymalizacji w aplikacjach o dużym wolumenie.
- Brak computer use na ten moment (śledź aktualizacje).
- Oceny bezpieczeństwa wskazują na solidne wyniki z poprawą tonu, choć metryki automatyczne są zróżnicowane.
- Redukcja halucynacji jest zauważalna, ale zawsze weryfikuj krytyczne wyniki.
- Wzrost ceny: Wyższa niż w poprzednich modelach Flash; optymalizuj poziomami myślenia i buforowaniem.
- Granica wiedzy: Styczeń 2025 — używaj narzędzi ugruntowania/Search dla bieżących wydarzeń.
Wniosek: czy Gemini 3.5 Flash jest wart uwagi?
Tak — dla deweloperów i przedsiębiorstw priorytetyzujących szybkość, niezawodność agentową, multimodalne możliwości i skalowalną wydajność. Przesuwa granicę Pareto, czyniąc czołowe AI bardziej dostępnym dla obciążeń produkcyjnych.
Gotowi do tworzenia? Przejdź na CometAPI, aby przetestować Gemini 3.5 Flash wraz z innymi topowymi modelami w jednym panelu. Optymalizuj swój stos AI, obniż koszty i dostarczaj szybciej.