Especificações Técnicas do GLM-5.2
| Item | GLM-5.2 |
|---|---|
| Provedor | Zhipu AI |
| Data de lançamento | 13 de junho de 2026 |
| Tipo de modelo | LLM Mixture-of-Experts (MoE) de pesos abertos |
| Parâmetros totais | ~744B |
| Parâmetros ativos | ~40B por token |
| Janela de contexto | 1,000,000 tokens |
| Saída máxima | 131,072 tokens |
| Modos de raciocínio | High, Max |
| Licença | MIT |
| Foco principal | Programação orientada a agentes, engenharia de software e raciocínio de longo horizonte |
| Disponibilidade da API | Plataforma Z.ai e provedores compatíveis |
| Pesos abertos | Sim |
O GLM-5.2 é o mais recente modelo carro-chefe da família GLM da Zhipu AI. Diferentemente dos modelos de fronteira de uso geral, o GLM-5.2 é posicionado principalmente como um modelo voltado primeiramente à programação e orientado a agentes, projetado para engenharia de software em escala de repositório, fluxos de trabalho autônomos e raciocínio com contexto extremamente longo. Sua capacidade de destaque é uma janela de contexto nativa de 1 milhão de tokens, tornando-a uma das maiores janelas de contexto publicamente disponíveis entre os modelos de pesos abertos.
Principais recursos do GLM-5.2
- Janela de contexto de 1M tokens para repositórios inteiros, conjuntos extensos de documentação e fluxos de trabalho de agentes em múltiplas sessões.
- Otimização voltada à programação focada em refatoração, depuração, geração de código e tarefas de engenharia de software.
- Suporte a fluxos de trabalho orientados a agentes para ferramentas como Claude Code, Cline, Roo Code, OpenCode e agentes de programação semelhantes.
- Lançamento de pesos abertos sob licença MIT, viabilizando auto-hospedagem e ajuste fino.
- Dois modos de raciocínio (High e Max) permitindo compensações entre latência e profundidade do raciocínio.
- Arquitetura MoE de grande porte com aproximadamente 744B de parâmetros totais, ativando apenas ~40B por token para eficiência.
Desempenho em benchmarks do GLM-5.2
A Zhipu não publicou resultados oficiais abrangentes de benchmark no lançamento, o que torna a comparação direta mais incerta do que em modelos como GPT-5 ou Claude. Diversos relatórios do setor apontam a ausência de divulgações de benchmark validadas independentemente.
| Benchmark | Pontuação reportada |
|---|---|
| Terminal-Bench 2.1 | 81.0 |
| SWE-Bench Pro | 62.1 |
| NL2Repo | 48.9 |
| AIME 2026 | 99.2 |
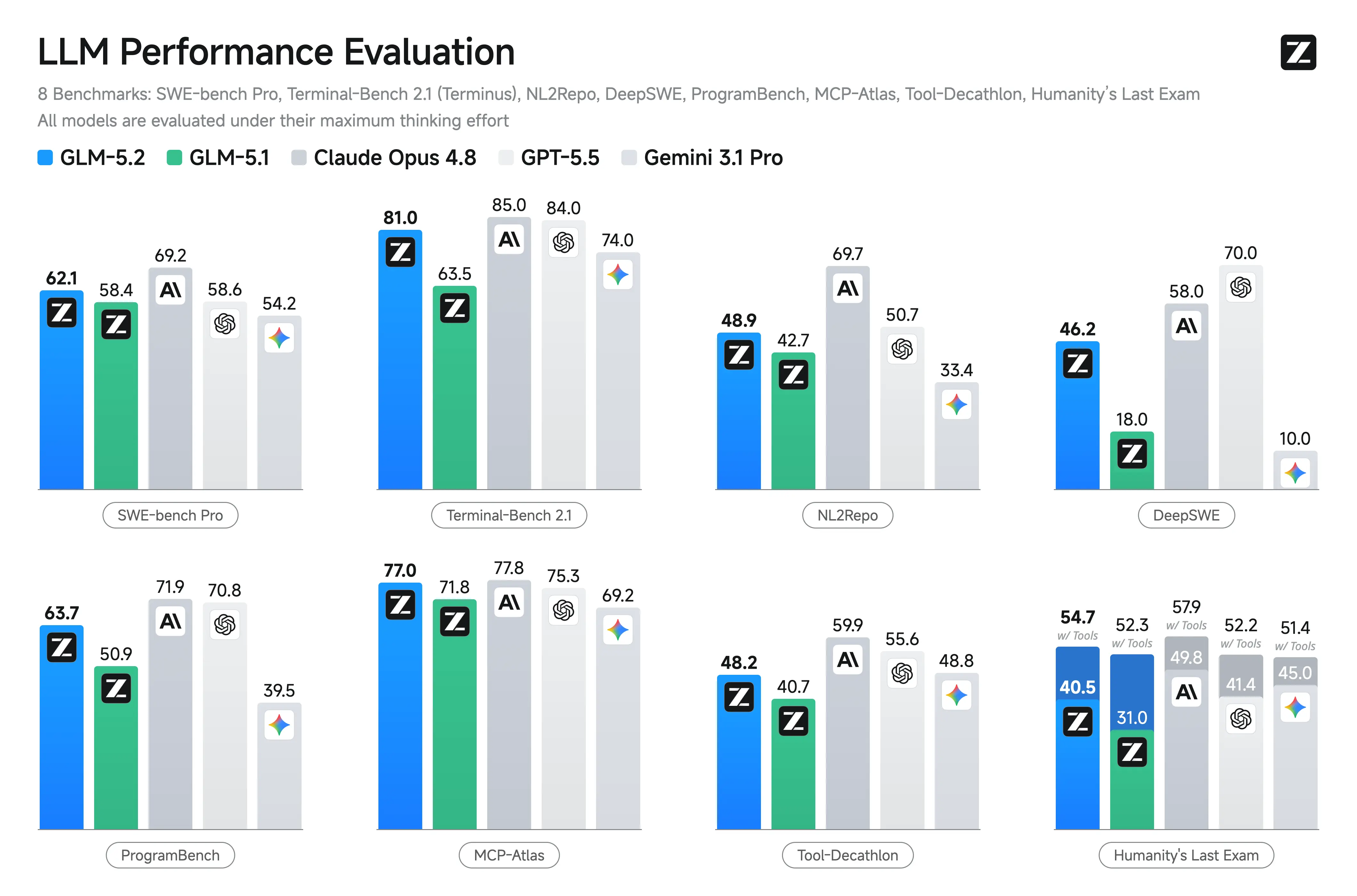
GLM-5.2 vs GLM-5.1 vs Claude Opus 4.8
| Especificação | GLM-5.2 | GLM-5.1 | Claude Opus 4.8 |
|---|---|---|---|
| Data de lançamento | 2026-06-13 | 2026 | 2026 |
| Janela de contexto | 1,000,000 | ~200,000 | 1,000,000 |
| Pesos abertos | Yes (MIT) | Yes | No |
| Modos de raciocínio | High, Max | Standard | Extended Thinking |
| Parâmetros totais | 744B | 744B | Not disclosed |
| Parâmetros ativos | 40B | 40B | Not disclosed |
| Dados de benchmark oficiais | Not published | Published at launch | Published |
A principal atualização documentada do GLM-5.2 em relação ao GLM-5.1 é sua expansão para uma janela de contexto de 1M tokens e a introdução de modos de raciocínio selecionáveis High e Max. No lançamento, a Z.ai não publicou resultados oficiais de benchmarks como SWE-Bench, LiveCodeBench, HumanEval ou similares, portanto as comparações de desempenho com Claude Opus 4.8, GPT-5, DeepSeek ou modelos Qwen permanecem não verificadas.
Em comparação com outros modelos abertos, o principal diferencial do GLM-5.2 é a combinação de uma janela de contexto muito grande, especialização em programação e licença MIT. Seu maior apelo é para engenharia de software em escala de repositório, em vez de aplicações de chat gerais.
Por que usar o GLM-5.2 por meio do CometAPI?
O CometAPI permite que desenvolvedores integrem o GLM-5.2 usando a mesma interface empregada por dezenas de modelos de IA líderes.
Benefícios incluem:
- Autenticação unificada entre múltiplos provedores
- Integração de API compatível com OpenAI
- Faturamento e gestão de uso simplificados
- Experimentação rápida com modelos alternativos
- Alternância fácil entre modelos de código, raciocínio, imagem, áudio e vídeo
- Redução do lock-in de fornecedor para sistemas de produção
Esteja você construindo um IDE de IA, um assistente interno de engenharia ou uma plataforma de automação corporativa, o CometAPI minimiza o esforço de integração ao mesmo tempo em que preserva a flexibilidade.
Como acessar a API do GLM-5.2 no CometAPI
Comece com nosso produto em apenas alguns passos simples...
Etapa 1: Cadastre-se para obter sua chave de API do GLM-5.2
Crie uma conta em Kie.ai e navegue até o painel da API para gerar sua chave de API do GLM-5.2. Essa chave autentica todas as suas solicitações e dá acesso imediato a todos os recursos da API do GLM-5.2, incluindo a janela de contexto de 1M tokens e 128k tokens de saída.
Etapa 2: Envie solicitações para a API do GLM-5.2
Use sua chave de API do GLM-5.2 para enviar solicitações POST ao endpoint Kie.ai. Passe seu prompt, defina parâmetros do modelo como nível de esforço e máximo de tokens, e a API do GLM-5.2 processa sua solicitação — lidando com tudo, da geração de código à análise de documentos e ao uso de ferramentas orientado a agentes.
Etapa 3: Recupere os resultados e integre a API do GLM-5.2
A API do GLM-5.2 entrega respostas estruturadas, incluindo texto de conclusão, instruções de chamada de ferramentas e metadados de uso de tokens. Ela oferece suporte tanto a respostas síncronas padrão quanto a streaming em tempo real via Server-Sent Events (SSE) quando stream: true está configurado. O endpoint pode ser facilmente integrado aos seus fluxos de trabalho existentes usando clientes HTTP padrão ou SDKs compatíveis com OpenAI, roteando as solicitações por meio de url(//api.cometapi.com/v1) com seu Bearer Token.