
.png&w=3840&q=75)
GPT-5.4 Mini اور GPT-5.4 Nano OpenAI کے GPT-5.4 فرنٹیئر فیملی کے نئے کمپیکٹ ویریئنٹس ہیں: Mini کو کوڈنگ، ملٹی موڈل UI ٹاسکس، اور سب ایجنٹ ورک لوڈز کے لیے بہترین کارکردگی/لیٹنسی ٹریڈ آف ہدف بنایا گیا ہے؛ Nano درجہ بندی، استخراج، رینکنگ اور بڑے پیمانے پر متوازی سب ایجنٹس کے لیے انتہائی کم لاگت اور لیٹنسی کو ہدف بناتا ہے۔ Mini بہت سے ڈویلپر بینچ مارکس پر قریب-فرنٹیئر درستگی فراہم کرتا ہے جبکہ پچھلے minis کے مقابلے میں >2× تیز چلتا ہے؛ Nano فی ٹوکن نمایاں طور پر سستا ہے اور وہاں آئیڈیل ہے جہاں تھروپٹ اور ردعمل سب سے زیادہ اہم ہوں۔ یہ ماڈلز API میں لائیو ہیں (GPT 5.4 Mini اور Nano CometAPI میں دستیاب ہیں)۔
GPT-5.4 Mini اور GPT-5.4 Nano کیا ہیں؟
مختصر تعریف: GPT-5.4 Mini اور GPT-5.4 Nano، GPT-5.4 فیملی کے کمپیکٹ، انجینیئرڈ ویریئنٹس ہیں جنہیں بڑے GPT-5.4 کی بنیادی طاقتیں (reasoning، coding، ملٹی موڈل پرسیپشن، tool use) تیز تر، کم لاگت ماڈلز میں لانے کے لیے ڈیزائن کیا گیا ہے، جو ہائی والیوم، کم لیٹنسی ورک لوڈز کو ہدف بناتے ہیں۔ یہ ماڈلز GPT-5.4 کے رول آؤٹ کے حصے کے طور پر OpenAI نے متعارف کرائے۔
- GPT-5.4 Mini — ایک پرفارمنٹ چھوٹا ماڈل جو "کئی ایویلیوایشنز پر GPT-5.4 کی کارکردگی کے قریب پہنچتا ہے" جبکہ رفتار اور کم لاگت کے لیے آپٹمائزڈ ہے۔ اسے خاص طور پر کوڈنگ، reasoning، ملٹی موڈل UI کی تعبیر (سکرین شاٹس)، اور ایجنٹک سسٹمز میں سب ایجنٹ کے طور پر نمایاں کیا گیا ہے۔ OpenAI رپورٹ کرتا ہے کہ یہ پچھلے "mini" ویریئنٹس کے مقابلے میں 2× سے زیادہ تیز چلتا ہے۔
- GPT-5.4 Nano — سب سے چھوٹا، سب سے سستا GPT-5.4 ویریئنٹ؛ درجہ بندی، استخراج، رینکنگ اور تنگ، دہرائے جانے والے کاموں کو بہت زیادہ تھروپٹ پر سنبھالنے والے “supporting” سب ایجنٹس کے لیے تجویز کردہ۔ یہ گہری reasoning کو لیٹنسی اور لاگت کی بچت کے لیے ٹریڈ آف کرتا ہے۔
دستیابی اور قیمت
OpenAI دو ٹھوس ڈیٹا پوائنٹس فراہم کرتا ہے جن سے آپ لاگت کا موازنہ کر سکتے ہیں:
- GPT-5.4 (فل فلیگ شپ) API ان پٹ قیمت: $2.50 / 1M tokens (اور فلیگ شپ پر آؤٹ پٹ قیمت زیادہ ہے)۔
- GPT-5.4 mini API ان پٹ قیمت: $0.75 / 1M tokens اور آؤٹ پٹ $4.50 / 1M tokens۔
- GPT-5.4 nano API ان پٹ قیمت: $0.20 / 1M اور آؤٹ پٹ $1.25 / 1M۔
سامنے سامنے رکھیں تو: mini کی ان پٹ ٹوکن قیمت (0.75) فلیگ شپ (2.50) کی 30% ہے، یعنی ان پٹ لاگت کا تقریباً ایک تہائی؛ mini کی آؤٹ پٹ قیمت (4.50) API پرائس ٹیبل میں دی گئی فلیگ شپ آؤٹ پٹ قیمت کا تقریباً 32% ہے، یعنی یہ بھی تقریباً ایک تہائی ہے۔ Nano اس سے بھی سستا ہے: اس کی ان پٹ لاگت فلیگ شپ ان پٹ لاگت کا تقریباً 8% ہے، اور اس کی آؤٹ پٹ لاگت فلیگ شپ آؤٹ پٹ لاگت کے تحت 10% ہے۔ یہی تناسبات ہیں جن کی وجہ سے OpenAI mini/nano کو “تقریباً ایک تہائی” (mini) اور “ایک حصے” (nano) کی لاگت پر بڑے ماڈلز کے مقابلے میں پیش کرتا ہے۔ nano ٹوکن کی قیمت $0.05 سے بڑھ کر $0.20 ہو گئی، اور mini ٹوکن کی قیمت $0.25 سے بڑھ کر $0.75 ہو گئی (ان پٹ ٹوکنز کے لیے)۔
OpenAI پلیٹ فارم میں
GPT-5.4 mini تین جگہوں پر دستیاب ہے: OpenAI API، Codex (OpenAI کا ڈویلپر IDE/ایپ پلیٹ فارم)، اور ChatGPT (Free اور Go صارفین کے لیے “Thinking” آپشن کے ذریعے اور پیڈ ٹئیرز کے لیے ریٹ-لمٹ fallback کے طور پر دستیاب)۔ API میں یہ متن اور تصاویر ان پٹ، ٹول استعمال (فنکشن کالنگ)، ویب/فائل سرچ، کمپیوٹر یوز، اور skills کو سپورٹ کرتا ہے — اور یہ بہت بڑا کانٹیکسٹ ونڈو (400k tokens) پیش کرتا ہے تاکہ ڈاکومنٹ-ہیوی اور ملٹی-سکرین شاٹ ورک فلو کی خدمت کر سکے۔ API کی قیمت $0.75 فی 1M ان پٹ ٹوکنز اور $4.50 فی 1M آؤٹ پٹ ٹوکنز ہے۔
GPT-5.4 nano صرف API کے ذریعے دستیاب ہے۔ اس کی فہرست قیمتیں $0.20 فی 1M ان پٹ ٹوکنز اور $1.25 فی 1M آؤٹ پٹ ٹوکنز ہیں — جو اسے GPT-5.4 فیملی میں سب سے کم لاگت والا انٹری بناتی ہیں۔ nano ماڈل جان بوجھ کر قابلیت کو لاگت اور رفتار کے لیے ٹریڈ آف کرتا ہے۔
تیسرے پلیٹ فارم پر
CometAPI ایک AI API ملٹی موڈل ایگریگیشن پلیٹ فارم ہے جس نے اب GPT 5.4 Series API لانچ کر دی ہے، جس میں GPT 5.4 Mini اور GPT 5.4 Nano شامل ہیں، اور وہ OpenAI قیمت سے 20% کم پر دستیاب ہیں۔
GPT 5.4 Nano:
| Comet قیمت (USD / M ٹوکنز) | Official قیمت (USD / M ٹوکنز) |
|---|---|
| ان پٹ:$0.16/M; آؤٹ پٹ:$1/M | ان پٹ:$0.2/M; آؤٹ پٹ:$1.25/M |
GPT 5.4 Nano:
| Comet قیمت (USD / M ٹوکنز) | Official قیمت (USD / M ٹوکنز) |
|---|---|
| ان پٹ:$0.6/M; آؤٹ پٹ:$3.6/M | ان پٹ:$0.75/M; آؤٹ پٹ:$4.5/M |
اہم خصوصیات اور نیا کیا ہے
ذیل میں سرخی وار صلاحیتیں ہیں — وہ وجہ جس سے انجینئرز اور پروڈکٹ ٹیمیں دلچسپی رکھیں گی۔
انکوڈنگ اور طویل سیاق کی معاونت
کانٹیکسٹ ونڈو: GPT-5.4 mini 400k ٹوکن کانٹیکسٹ ونڈو سپورٹ کرتا ہے (OpenAI واضح طور پر mini کو 400k کانٹیکسٹ کے ساتھ فہرست کرتا ہے)۔ یہ اتنا بڑا ہے کہ متعدد فائل کوڈ بیسز، طویل دستاویزات، یا ملٹی ٹرن ایجنٹ سیشنز کے لیے جہاں سیاق اہم ہو۔ Nano کا کانٹیکسٹ فل GPT-5.4 کے مقابلے میں چھوٹا ہے لیکن پھر بھی تیز، مختصر ٹاسکس کے لیے خاطر خواہ ہے۔
استدلال
Reasoning لیولز: OpenAI قابل کنفیگر reasoning_effort (none → xhigh) ایکسپوز کرتا ہے؛ mini اور nano مختلف effort پر چل سکتے ہیں مگر mini بلند effort پر کئی reasoning بینچ مارکس میں فل GPT-5.4 کے قریب آ جاتا ہے۔ کئی انٹیلیجنس بینچ مارکس (مثلاً GPQA Diamond) پر، mini 88.0% اسکور حاصل کرتا ہے جبکہ GPT-5.4 93.0% ہے، اور nano 82.8% پوسٹ کرتا ہے، جو چھوٹے ماڈل کے لیے معقول reasoning کی طرف اشارہ کرتا ہے۔ یہ نتائج OpenAI نے اپنے لانچ پوسٹ میں شائع کیے۔
ملٹی موڈل فہم (ویژن اور UI)
بصری ادراک اور UI ٹاسکس: GPT-5.4 mini UI ٹاسکس (سکرین شاٹس، گھنی دستاویزاتی تصاویر) کے لیے بہت مضبوط ملٹی موڈل کارکردگی دکھاتا ہے۔ OSWorld-Verified (کمپیوٹر یوز بینچ مارک) پر، mini 72.1% سکور کرتا ہے، جو GPT-5.4 کے 75.0% کے بہت قریب ہے اور سابقہ minis سے کہیں آگے — یہی وجہ ہے کہ mini کو سکرین شاٹ-ڈرِون آٹومیشنز اور ریسپانسیو ملٹی موڈل اسسٹنٹس کے لیے پوزیشن کیا گیا ہے۔ Nano بصری بینچ مارکس پر کم کارکردگی دکھاتا ہے مگر سادہ امیج ٹاسکس کے لیے پھر بھی مفید ہے۔
ٹول کالنگ اور کمپیوٹر استعمال
Native ٹول/کلک صلاحیتیں: GPT-5.4 نیٹو کمپیوٹر-یوز ٹولنگ متعارف اور توسیع کرتا ہے؛ mini اس صلاحیت کو وراثت میں لیتا ہے کہ ٹولز کال کرے، فنکشن کالز کرے، سکرین شاٹس کی تعبیر کرے اور سب ایجنٹس کو آرکسٹریٹ کرے۔ ٹول کال بینچ مارکس (Toolathlon، MCP Atlas) میں mini اور nano مناسب اسکور کرتے ہیں (Toolathlon: mini 42.9%, nano 35.5%) — یہ بیرونی ٹولز کو کال اور ہم آہنگ کرنے کی ان کی صلاحیت کو مقداری طور پر ظاہر کرتا ہے۔ یہ میٹرکس OpenAI کے اعلان سے ہیں۔
ہیلوسینیشن / حقیقت پر مبنی ہونا / غلطی کی شرحیں
OpenAI رپورٹ کرتا ہے کہ GPT-5.4 اب تک کا “سب سے factual ماڈل” ہے اور GPT-5.2 کے مقابلے میں ہیلوسینیشن میں کمی دکھاتا ہے؛ mini اور nano فل ماڈل کے مقابلے میں مطلق factuality میں کم ہیں (مثلاً، HLE w/ tools: GPT-5.4 52.1%, mini 41.5%, nano 37.7%) جو ظاہر کرتا ہے کہ ہائی-فیکٹ ٹاسکس میں چھوٹے ماڈلز استعمال کرتے وقت توثیق کی ضرورت بڑھ جاتی ہے۔ جب درستگی اہم ہو تو ٹول-بیسڈ verification (ٹول کالز، حوالہ جات کی بازیافت) استعمال کریں۔
رفتار
OpenAI رپورٹ کرتا ہے کہ GPT-5.4 mini عام پروڈکشن-اسٹائل لیٹنسی تخمینوں پر پچھلے GPT-5 mini کے مقابلے میں 2× سے زیادہ تیز چلتا ہے (یہ تخمینے سمولیٹڈ پروڈکشن برتاؤ پر مبنی ہیں جن میں ٹول کال دورانیے اور سمپلڈ ٹوکنز شامل ہیں)۔ یہ اسپیڈ اپ اس نئی فیملی کا مرکزی دعویٰ ہے اور یہی mini کو انٹرایکٹو ایپس جیسے کوڈنگ اسسٹنٹس کے اندر ایک ریسپانسیو سب ایجنٹ کے طور پر استعمال کرنے کے قابل بناتا ہے۔
Mini اور Nano کی کارکردگی — کیا یہ فل GPT-5.4 کے “قریب” پہنچتے ہیں؟
OpenAI نے کوڈنگ، ٹول یوز، ملٹی موڈل کمپیوٹر-یوز ٹاسکس، انٹیلیجنس ٹیسٹس، اور لانگ-کانٹیکسٹ ایویلیوایشنز میں بینچ مارک تقابلات کا ایک جامع سیٹ شائع کیا۔ سرخی وار نمبرز (جہاں قابل اطلاق ہو xhigh reasoning effort) میں شامل ہیں:
| بینچ مارک | GPT-5.4 | GPT-5.4 Mini | GPT-5.4 Nano | GPT-5 Mini (Old) | نوٹس |
|---|---|---|---|---|---|
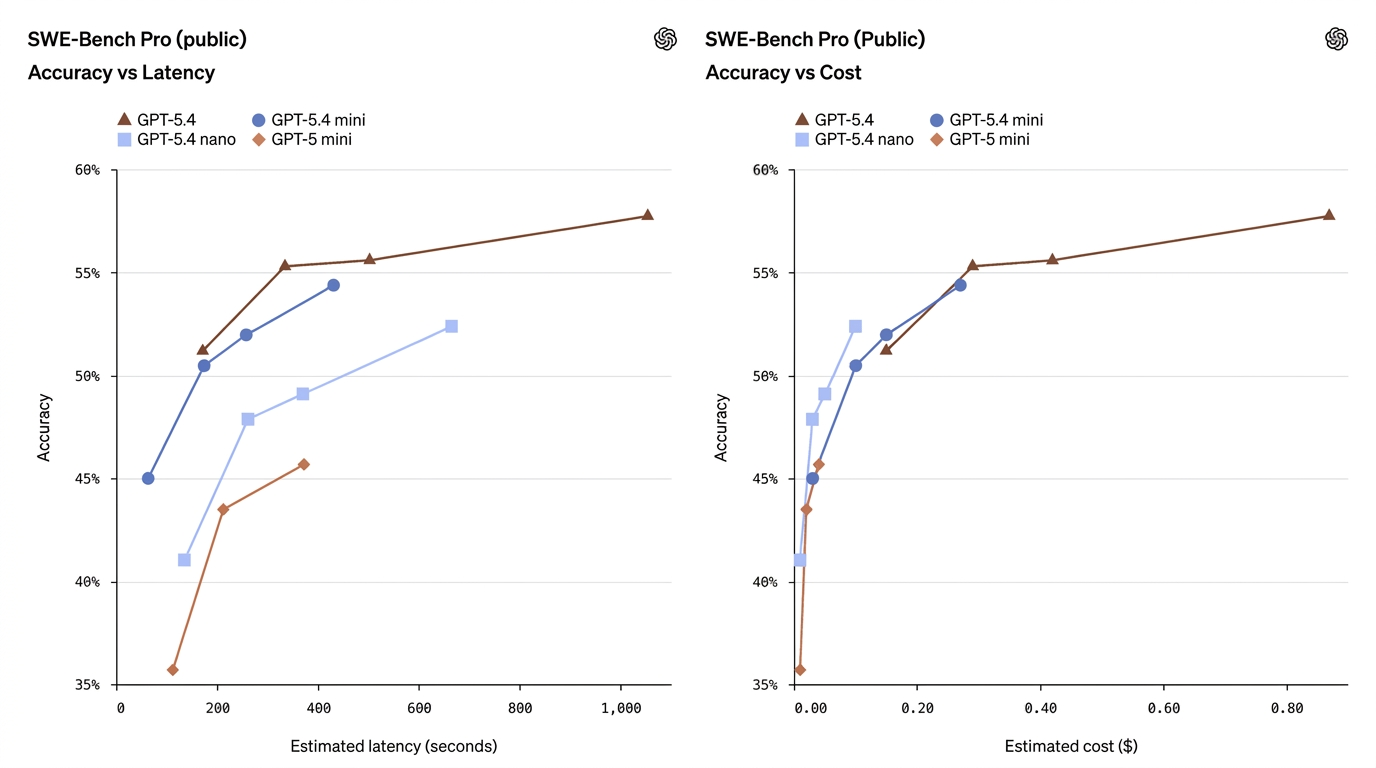
| SWE-Bench Pro (Coding) | 57.7% | 54.4% | 52.4% | 45.7% | Mini فل ماڈل کی کوڈنگ کارکردگی کے قریب آتا ہے |
| Terminal-Bench 2.0 (Interactive Coding) | 75.1% | 60.0% | 46.3% | — | Mini کے لیے مضبوط ریئل ٹائم کوڈنگ اہلیت |
| Toolathlon (Tool Use) | 54.6% | 42.9% | 35.5% | — | آرکسٹریشن اور ٹول-کالنگ کی پیمائش |
| GPQA Diamond (Advanced QA) | 93.0% | 88.0% | 82.8% | — | انٹیلیجنس اور reasoning بینچ مارک |
| OSWorld-Verified (GUI Tasks) | 75.0% | 72.1% | 39.0% | 42.0% | UI/کمپیوٹر-یوز صلاحیت |
یہ نمبرز دکھاتے ہیں کہ mini اکثر فرق کو کافی حد تک کم کرتا ہے — خاص طور پر کوڈنگ اور کمپیوٹر-یوز ٹاسکس پر — جبکہ nano قابلیت اور لاگت کے درمیان ایک مفید وسطی مقام لیتا ہے۔
سادہ الفاظ میں یہ اعداد و شمار کیا بتاتے ہیں؟
- GPT-5.4 Mini ≈ “کئی پروڈکشن ٹاسکس پر تقریباً فلیگ شپ”۔ SWE-Bench Pro (کوڈنگ پاس-ریٹ میٹرک) پر، mini 54.4% سکور کرتا ہے جبکہ فلیگ شپ 57.7% — بہت سے حقیقی دنیا کے کوڈنگ کاموں کے لیے یہ نسبتاً کم فرق ہے، خاص طور پر جب لیٹنسی اہم ہو۔ OSWorld (کمپیوٹر یوز) پر، mini 72.1% ہے جبکہ فلیگ شپ 75.0% — پھر بھی UI/سکرین شاٹ ٹاسکس کے لیے بہت قریب۔
- GPT-5.4 Nano زیادہ قابلیت کو رفتار/لاگت کے لیے ٹریڈ آف کرتا ہے۔ Nano کا کوڈنگ سکور (SWE-Bench Pro پر 52.4%) سابقہ minis کے مقابلے میں معقول ہے، مگر اس کا OSWorld سکور 39.0% تک گر جاتا ہے، جو دکھاتا ہے کہ پیچیدہ ملٹی-اسٹیپ UI سمجھ یا ایجنٹک ٹول سیکوئنسز کے لیے nano کم موزوں ہے۔ Nano سنگل-ٹرن درجہ بندی، استخراج، اور چھوٹے مددگار کاموں میں چمکتا ہے۔
- ٹول یوز بہتر ہوا، مگر حساس رہتا ہے۔ Toolathlon اور دیگر ٹول-یوز میٹرکس GPT-5 mini سے GPT-5.4 mini/nano پر سوئچ کرنے سے نمایاں طور پر بڑھتے ہیں، جس سے ظاہر ہوتا ہے کہ OpenAI نے چھوٹے فٹ پرنٹ ماڈلز میں ٹول انوکیشن ریلائی ایبیلٹی بہتر کی — لیکن پیچیدہ ٹول آرکسٹریشن میں فل ماڈل اب بھی آگے ہے۔
پروڈکشن میں یہ کیسے کام کرتے ہیں
کمپریشن، ڈسٹلیشن اور انجینیئرنگ اصلاحات
Mini/Nano جیسے کمپیکٹ ماڈلز عام طور پر model distillation، quantization، اور architectural pruning کے امتزاج کا استعمال کرتے ہیں تاکہ اعلیٰ قدر صلاحیتیں (کوڈنگ ہیورسٹکس، بصری پرسیپٹس) محفوظ رہیں جبکہ inference compute کم کیا جا سکے۔ OpenAI کی لفظیات مخصوص skillsets (کوڈنگ، ملٹی موڈل UI فہم) کو چھوٹے فٹ پرنٹس میں محفوظ رکھنے پر مرکوز انجینیئرنگ کی طرف اشارہ کرتی ہیں۔
تجویز کردہ پیٹرنز
- Orchestrator + subagent پیٹرن: GPT-5.4 (بڑا) بطور پلانر/جج استعمال کریں اور کام GPT-5.4 mini / nano سب ایجنٹس کو تیزی سے انجام دہی کے لیے تفویض کریں (سرچ، پارس، ایڈٹ)۔ اس سے کل لاگت کم ہوتی ہے اور صارف کے لیے لیٹنسی گھٹتی ہے۔ OpenAI اس ڈیزائن پیٹرن کی صراحتاً توثیق کرتا ہے۔
- Fallback اور ریٹ-لمٹ ہینڈلنگ: ChatGPT یا Codex میں mini کو ریٹ-لمٹ fallback کے طور پر ایکسپوز کریں تاکہ وقت-حساس سوالات کو بھی قابل جواب ملے جب فل ماڈل دستیاب نہ ہو۔
- لاگت کنٹرول کے لیے ٹئیرڈ آرکیٹیکچر: بلک پائپ لائنز (انڈیکسنگ، استخراج) → GPT-5.4 nano؛ انٹرایکٹو UI کمپوننٹس → GPT-5.4 mini؛ آخری اداریہ جاتی فیصلہ/پیچیدہ چینز → GPT-5.4 فل۔ یہ ملٹی-ٹئیر طریقہ لاگت اور قابلیت میں توازن لاتا ہے۔
لیٹنسی اور متوازی پن
Mini اور nano کو parallel subagents کے لیے آپٹمائز کیا گیا ہے، جہاں بہت سے چھوٹے ورکرز بیک وقت چلتے ہیں — مثلاً، ہزاروں PDFs کو متوازی اسکین کرنا۔ OpenAI کا “tool yields” تصور ماپتا ہے کہ متوازی ٹول کالز وال-کلاک لیٹنسی کو کیسے کم کرتی ہیں؛ mini/nano کو ان پیٹرنز کو لاگت-افورڈ ایبل بنانے کے لیے انجینیئر کیا گیا ہے۔
عملی طور پر میں Mini اور Nano کو کیسے استعمال کروں
کیا مجھے ہر جگہ فلیگ شپ کالز کو Mini/Nano سے بدل دینا چاہیے؟
ضروری نہیں۔ درست پیٹرن جس کی OpenAI صراحتاً سفارش کرتا ہے وہ delegation ہے: منصوبہ بندی، پیچیدہ فیصلے، یا آخری توثیق کے لیے بڑے ماڈل کا استعمال کریں، اور بہت سے سپورٹنگ، مختصر ذیلی کام Mini یا Nano سب ایجنٹس کو تفویض کریں۔ یہ پیٹرن لاگت اور لیٹنسی کو کم کرتا ہے جبکہ جہاں اہم ہو وہاں بڑے ماڈل کی حفاظتی حدود برقرار رکھتا ہے۔ استعمال کی مثالیں:
- انٹرایکٹو کوڈنگ اسسٹنٹس: فلیگ شپ پلان اور ریویو کرے؛ Mini تیزی سے کوڈ سرچ، ایڈٹس، اور مختصر یونٹ ٹیسٹس سنبھالے۔
- سکرین شاٹ-ڈرِون “کمپیوٹر یوز” ایجنٹس: Mini گھنی انٹرفیسز کو تیزی سے پارس کر سکتا ہے؛ فلیگ شپ مبہم ملٹی-اسٹیپ پلاننگ کو حل کرتا ہے۔
- ہائی والیوم استخراج اور درجہ بندی پائپ لائنز: Nano بڑے بیچڈ ان پٹس (فارمز، لاگز) کو پراسیس کر کے اسٹرکچرڈ نتائج لوٹاتا ہے؛ فلیگ شپ ایکسیپشنز اور پیچیدہ ایج کیسز کو ہینڈل کرتا ہے۔
کیا Mini یا Nano کو ملٹی موڈل یا امیج ٹاسکس کے لیے استعمال کیا جا سکتا ہے؟
ہاں — Mini امیج ان پٹس سپورٹ کرتا ہے اور ملٹی موڈل/ویژن-ڈرِون بینچ مارکس (MMMUPro/OmniDocBench) پر اچھی کارکردگی دکھاتا ہے، کچھ ٹیسٹس پر فلیگ شپ کے قریب آتا ہے۔ Nano کی ملٹی موڈل قوت محدود تر ہے: اگرچہ یہ سابقہ nanos پر بہتری ہے، لیکن گہری ملٹی موڈل reasoning یا ایجنٹک امیج-بیسڈ ٹاسکس کے لیے یہ بہترین انتخاب نہیں۔
چھوٹے ماڈلز کی قابلیتوں کی دوڑ تیز ہو گئی ہے
تین ماہ پہلے، چھوٹے ماڈلز کو "کافی حد تک اچھا" سمجھا جاتا تھا۔ اب، GPT-5.4 mini پروگرامنگ بینچ مارکس پر فلیگ شپ ماڈلز کے قریب پہنچ رہا ہے اور کمپیوٹیشنل کارکردگی میں تقریباً ان کے برابر ہو چکا ہے۔
اس رجحان کی سمت واضح ہے: فلیگ شپ ماڈلز کی قابلیتیں تیزی سے چھوٹے ماڈلز میں منتقل ہو رہی ہیں۔ OpenAI، Google، اور Anthropic سب ایک ہی کام کر رہے ہیں: بڑے ماڈلز کی بنیادی قابلیتوں کو چھوٹے، تیز تر، اور سستے ورژنز میں ڈسٹل کرنا۔
نتیجہ
ان دونوں ماڈلز کی ریلیز AI ایپلیکیشنز کو حجم سے عملی کارکردگی کی طرف منتقل ہونے کی علامت ہے۔ تیز رفتار ردعمل کی صلاحیتوں کے ذریعے، یہ حقیقی وقت کی AI انٹریکشن اور پیچیدہ ٹاسک فلو کی تقسیم کے لیے زیادہ قابلِ اعتماد بنیادی سہارا فراہم کرتے ہیں۔
ڈویلپرز کے لیے، اس کا مطلب ہے کہ ایجنٹ سسٹمز کی لاگت ساخت نئی تعریف اختیار کر رہی ہے۔ جب لاگت اس سطح تک گر جائے، تو کئی ایجنٹ سینیریوز جو پہلے "نظریاتی طور پر ممکن مگر اقتصادی طور پر ناممکن" تھے، قابلِ عمل ہو جاتے ہیں۔
ڈویلپرز GPT 5.4 Mini اور GPT-5.4 Nano تک CometAPI کے ذریعے اب رسائی حاصل کر سکتے ہیں (CometAPI GPT APIs، Nano Banana APIs وغیرہ جیسے بڑے ماڈل APIs کے لیے ایک ون-اسٹاپ ایگریگیشن پلیٹ فارم ہے)۔ رسائی سے قبل، براہ کرم یقینی بنائیں کہ آپ نے CometAPI میں لاگ ان کر لیا ہے اور API key حاصل کر لی ہے۔ CometAPI آپ کے انضمام میں مدد کے لیے سرکاری قیمت کے مقابلے میں کہیں کم قیمت پیش کرتا ہے۔
تیار ہیں؟