

En el vertiginoso panorama de la IA, GLM-5.2 de Z.ai (Zhipu AI) destaca como un formidable modelo de pesos abiertos optimizado para codificación orientada a agentes, tareas de largo horizonte y fiabilidad en producción. Con una ventana de contexto utilizable de 1M tokens, modos de razonamiento duales (High y Max) y un rendimiento sólido a una fracción del coste de los modelos cerrados de vanguardia, se está convirtiendo rápidamente en la opción de referencia para desarrolladores que crean agentes autónomos, integraciones con IDE y flujos de trabajo complejos de ingeniería de software.
Tanto si eres un desarrollador independiente creando prototipos de agentes, un CTO evaluando escalado rentable, como un product manager de IA que integra razonamiento multimodal en un SaaS, dominar la API de GLM-5.2 desbloquea ventajas significativas.
¿Qué es GLM-5.2?
GLM-5.2 es el último modelo insignia de pesos abiertos de Mixture-of-Experts (MoE) de Z.ai (Zhipu AI), lanzado a mediados de junio de 2026. Con aproximadamente 753B parámetros totales (alrededor de 40B activos por token), una ventana de contexto estable de 1 millón de tokens, licencia MIT y un gran rendimiento en tareas de programación de largo horizonte y orientadas a agentes, se posiciona como una alternativa competitiva a modelos cerrados de vanguardia como GPT-5.5, Claude Opus 4.8 y variantes de Gemini, a una fracción del coste para muchas cargas de trabajo.
Arquitectura y especificaciones técnicas de GLM-5.2
GLM-5.2 se basa en la familia GLM con mejoras clave para trabajo de largo horizonte.
- Parámetros: ~753B totales en diseño MoE (parámetros activos ~40B por token). Esto ofrece una capacidad enorme con inferencia eficiente.
- Ventana de contexto: 1,048,576 tokens (1M). Salida máxima normalmente de hasta 128K–131K tokens.
- Precisión: BF16 (con variantes FP8 para despliegues más ligeros).
- Innovación clave – IndexShare: reutiliza un único indexador en grupos de capas de atención dispersa, reduciendo los FLOPs por token hasta 2.9x en contexto de 1M. Esto hace viable la inferencia de largo contexto sin disparar los costes o la latencia.
- Modos de razonamiento: "High" (equilibrado) y "Max" (el más profundo, recomendado para programación). El razonamiento puede desactivarse para tareas simples.
- Modalidades: Principalmente texto/código (sin visión nativa confirmada en la versión base).
- Licencia: MIT: completamente abierto para descarga, modificación y uso comercial.
Esta apertura y eficiencia hacen de GLM-5.2 una opción ideal para equipos que priorizan la privacidad de datos, la personalización o el control de costes.
GLM-5.2 vs GLM-5.1
| Área | GLM-5.1 | GLM-5.2 | Diferencia práctica |
|---|---|---|---|
| Ventana de contexto | En torno a 200K en rutas alojadas comunes | 1M | GLM-5.2 se adapta mucho mejor al contexto de proyectos completos |
| Esfuerzo de razonamiento | Menos flexible | High y Max | Mejor control sobre coste, latencia y calidad |
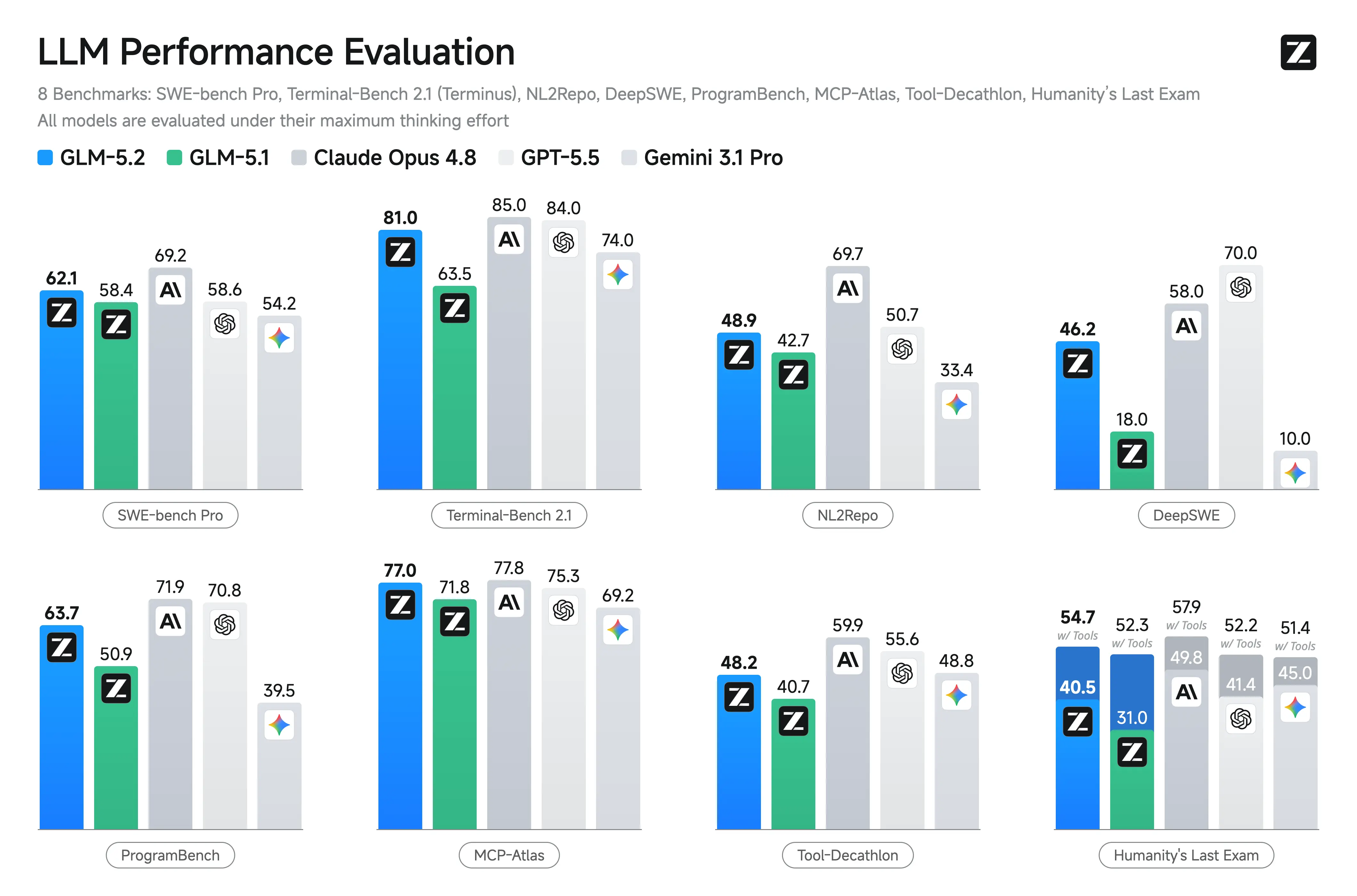
| Terminal Bench 2.1 | 63.5 en la tabla publicada | 81.0 | Mejora notable en tareas de agentes basadas en terminal |
| SWE-bench Pro | 58.4 | 62.1 | Mejora moderada pero significativa a nivel de repositorio en programación |
| FrontierSWE | 30.5 | 74.4 | Gran mejora en ingeniería de largo horizonte |
| Postura de pesos abiertos | Familia GLM de pesos abiertos | Lanzamiento MIT de pesos abiertos | Apertura similar, posicionamiento más fuerte en contextos largos |
Si tu flujo de trabajo actual con GLM-5.1 es principalmente chat corto o generación básica de código, la actualización puede no cambiarlo todo. Si tu flujo implica repositorios grandes, agentes de programación multi-paso o ejecución de tareas largas, GLM-5.2 es un modelo mucho más relevante.
GLM-5.2 vs Claude Opus, GPT-5.5, Gemini y DeepSeek
La manera más clara de comparar GLM-5.2 es por tipo de tarea:
| Tipo de tarea | Posición de GLM-5.2 |
|---|---|
| Programación de largo horizonte | Una de las opciones de pesos abiertos más fuertes; cerca de los modelos cerrados de vanguardia en determinados benchmarks |
| Razonamiento general | Sólido, pero no siempre por delante de los mejores modelos cerrados |
| Uso de herramientas | Alto rendimiento en MCP-Atlas y HLE-with-tools |
| Competiciones matemáticas | Puntaje AIME 2026 muy fuerte en los resultados publicados |
| Visión | No es el modelo adecuado; utiliza un modelo de visión |
| Clasificación de alto volumen y bajo coste | Normalmente sobredimensionado; usa un modelo más pequeño |
| Autoalojamiento y personalización | Opción más fuerte que los modelos cerrados solo API |
Para los equipos, la mejor respuesta no suele ser "reemplazar todos los modelos por GLM-5.2". La respuesta mejor es "encaminar GLM-5.2 a las tareas donde tiene ventaja". Esa es una razón por la que un proveedor de API unificado como CometAPI puede ser práctico. Te permite comparar y encaminar modelos por carga de trabajo sin reconstruir cada integración.
Precios: potencia asequible para escalar
GLM-5.2 ofrece una economía convincente, especialmente para trabajo de largo contexto con muchos tokens.
- Precios de API (vía Z.ai/OpenRouter/etc.): $1.40 / 1M tokens de entrada, $4.40 / 1M tokens de salida. Lectura de caché desde $0.26/1M en algunas rutas.
- Suscripciones del plan GLM Coding (incluye acceso completo, sin coste adicional por 5.2):
- Lite: ~$10-12.60/mes (iteración ligera).
- Pro: ~$30/mes.
- Max/Team: cuotas más altas para uso intensivo.
Ejemplo de ahorro de costes: Para una sesión agéntica larga con 500K de contexto + salidas, GLM-5.2 puede ser 4-5x más barato que equivalentes de Claude, mientras maneja contextos más grandes de forma nativa.
Recomendación de CometAPI: Accede a GLM-5.2 (y más de 500 modelos) a través del endpoint unificado compatible con OpenAI de CometAPI a tarifas competitivas. Una sola clave, sin bloqueo de proveedor, créditos de prueba al registrarte. Ideal para comparar GLM-5.2 junto a Claude/GPT en producción. Visita cometapi para una integración sin fricciones.
Ventana de contexto de 1M: la característica destacada
El contexto de 1M es "sólido" y sin pérdidas en la práctica para trabajo a escala de proyecto, muy por encima del marketing. Permite mantener repositorios de tamaño medio a grande en contexto, reduciendo la sobrecarga de resumen y la acumulación de errores en agentes.
Consejos para un uso eficaz:
- Usa el identificador glm-5.2[1m].
- Configura max tokens adecuadamente; monitoriza para producción.
- Combínalo con herramientas/MCP para obtención dinámica de datos.
Las pruebas tempranas confirman la estabilidad más allá de 200K, un punto de fallo común en otros modelos de "largo contexto".
Rendimiento base y benchmarks
Z.ai e informes independientes destacan las fortalezas de GLM-5.2 en escenarios de programación y agentes. Muestra ganancias sustanciales sobre GLM-5.1 y resultados competitivos frente a modelos cerrados en tareas de largo horizonte.
Benchmarks clave reportados (Z.ai y agregados de terceros):
- Terminal-Bench 2.1: 81.0 (desde 62.0 de GLM-5.1) – Excelente para operaciones de terminal/agente.
- SWE-bench Pro: 62.1 (supera ligeramente a GPT-5.5 con 58.6).
- MCP-Atlas: 77.0 (cerca de Claude Opus 4.8).
- Humanity’s Last Exam (with tools): 54.7.
Otras ventajas: Tope o cerca del tope entre modelos abiertos en FrontierSWE, PostTrainBench, SWE-Marathon. Fuerte en AIME 2026 (~99.2) y GPQA-Diamond (91.2).
Opciones de acceso a la API de GLM-5.2
Hay dos maneras comunes de acceder a GLM-5.2 desde una aplicación.
Opción 1: Usar Z.ai directamente
La vía directa es utilizar la API oficial de Z.ai. Esta puede ser la elección adecuada cuando tu equipo quiere una relación directa con el proveedor del modelo, usa solo modelos de Z.ai o necesita controles específicos del proveedor tan pronto como se publiquen.
El compromiso es operativo. Si tu producto usa múltiples familias de modelos, puede que necesites mantener configuraciones de SDK separadas, flujos de facturación, lógica de conmutación por error, normalización de precios y convenciones de observabilidad. Para un proyecto de investigación, eso puede ser aceptable. Para una plataforma SaaS en producción, la superficie de integración puede crecer rápidamente.
Opción 2: Usar GLM-5.2 a través de CometAPI
CometAPI proporciona acceso a GLM-5.2 mediante una pasarela de API unificada. El beneficio práctico es que los desarrolladores pueden invocar distintos modelos de IA a través de una interfaz compatible con OpenAI en lugar de construir una integración por proveedor. Mantienes tu código cercano al patrón del SDK de OpenAI, estableces el nombre del modelo a glm-5.2 y enrutas las solicitudes a través de CometAPI.
Esto es útil para startups y equipos de producto que quieren:
- Probar GLM-5.2 frente a otros modelos sin reconstruir su backend
- Mantener una sola clave de API y una sola capa de facturación para múltiples modelos
- Avanzar más rápido del benchmark al prototipo y a producción
- Implementar estrategias de fallback o enrutado de modelos
- Comparar coste y calidad entre proveedores
- Usar patrones de solicitudes estilo OpenAI familiares
Regístrate en CometAPI.com para obtener créditos de prueba instantáneos y endpoints compatibles con OpenAI que abstraen las peculiaridades de cada proveedor.
- Obtén tu clave de API.
- Configura variables de entorno (buena práctica de seguridad):
export GLM_API_KEY="your_key_here"
export BASE_URL="https://api.cometapi.com/v1" # or direct Z.ai endpoint
Realiza tu primera llamada a la API de GLM-5.2
Ejemplo cURL (prueba rápida):
bash
curl https://api.z.ai/api/paas/v4/chat/completions \
-H "Authorization: Bearer $GLM_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5.2",
"messages": [
{"role": "system", "content": "You are an expert full-stack engineer."},
{"role": "user", "content": "Write a FastAPI endpoint for user authentication with JWT."}
],
"temperature": 0.7,
"max_tokens": 2048
}'
Casos de uso comunes de GLM-5.2
GLM-5.2 es un candidato sólido para flujos de trabajo donde se combinan contexto largo, razonamiento y uso de herramientas.
| Caso de uso | Implementación de ejemplo | Por qué GLM-5.2 puede encajar |
|---|---|---|
| Asistente para desarrolladores | Analizar informes de errores, fragmentos de código, registros y pruebas | Requiere razonamiento a través de contexto técnico |
| Inteligencia documental | Revisar contratos, políticas, reclamaciones o informes | Entradas largas y extracción estructurada |
| Agente de investigación | Leer fuentes, comparar afirmaciones, producir resúmenes | Se beneficia de contexto largo y disciplina de citación |
| Copiloto de soporte al cliente | Combinar historial de tickets, documentación, datos de cuenta y política | Necesita recuperación y llamadas a herramientas |
| Asistente de product manager de IA | Sintetizar feedback, especificaciones, datos de uso y notas de hoja de ruta | Contexto largo y razonamiento de negocio |
| Análisis de seguridad | Revisar informes de incidentes, alertas y planes de remediación | Necesita razonamiento multi-paso |
| Ingeniería de ventas | Generar respuestas técnicas desde documentación y requisitos del cliente | Útil para ciclos de ventas B2B complejos |
El patrón común no es "chatbot". El patrón común es la compresión del flujo de trabajo. GLM-5.2 puede reducir el tiempo entre la información en bruto y una decisión útil.
¿Quién debería usar GLM-5.2?
GLM-5.2 encaja bien para:
- Desarrolladores que construyen herramientas de programación con IA.
- Empresas SaaS que añaden asistentes conscientes del repositorio.
- CTOs que evalúan alternativas de pesos abiertos a modelos de código cerrados.
- Product managers de IA que prueban flujos de trabajo de largo contexto.
- Empresas con futura autoimplantación o necesidades de control de datos.
- Plataformas para desarrolladores que necesitan opcionalidad de modelo.
- Equipos que trabajan con documentos técnicos, SDKs o bases de código grandes.
Es especialmente atractivo cuando fallar es caro. Si un error del modelo provoca builds rotos, malas migraciones o tiempo de ingeniería desperdiciado, el coste de usar un modelo más fuerte puede justificarse rápidamente.
Cuándo no usar GLM-5.2
No lo uses por defecto para:
- Tareas de clasificación cortas y repetitivas.
- Reescritura simple de texto.
- Comprensión de imágenes o capturas de pantalla.
- Autocompletado de baja latencia donde importan milisegundos.
- Flujos donde un modelo más pequeño ya rinde bien.
- Productos que no toleran generaciones de larga duración.
El objetivo no es venerar la ventana de contexto más grande. El objetivo es resolver la tarea con el perfil adecuado de calidad, coste y latencia.
Veredicto final
GLM-5.2 es uno de los lanzamientos de modelos de IA de pesos abiertos más importantes para equipos de ingeniería de software en 2026. La combinación de contexto de 1M, fuertes benchmarks de programación, modos de razonamiento High y Max, compatibilidad con llamadas a funciones y licencia MIT lo convierten en una opción seria para agentes de programación y flujos de trabajo de IA de largo horizonte.
Para los equipos que quieran probarlo rápidamente, CometAPI es una capa de acceso pragmática. Puedes invocar GLM-5.2 mediante un endpoint compatible con OpenAI, compararlo con otros modelos líderes, monitorizar el uso y construir una estrategia de enrutado sin reestructurar tu stack alrededor de un único proveedor. Comienza con una evaluación privada pequeña, mide el coste por tarea resuelta y lleva GLM-5.2 a producción solo donde sus fortalezas de largo contexto se paguen claramente por sí mismas.
¿Listo para probar GLM-5.2 en tu propia app? Explora GLM-5.2 en CometAPI, crea una clave de API y ejecuta tu primera solicitud compatible con OpenAI en minutos. Úsalo para una tarea real de repositorio, no un prompt de juguete, y compara el resultado con tu pila actual de modelos.