

Google lanzó Gemini 3.5 Flash el 19 de mayo de 2026, en I/O, posicionándolo como un modelo de alta inteligencia optimizado para la velocidad, con rendimiento de vanguardia sostenido en flujos de trabajo agénticos, programación y tareas multimodales. Se basa en los cimientos de Gemini 3 Flash con “niveles de pensamiento” mejorados para equilibrar calidad, costo y latencia.
Esta guía integral cubre todo: qué es Gemini 3.5 Flash, sus características clave, rendimiento detallado en benchmarks, precios, comparaciones con GPT-5.5, Claude 4.7/4.6 y más. Como agregador líder de API de IA, CometAPI ayuda a los desarrolladores a acceder a Gemini 3.5 Flash (y a sus competidores) con precios unificados, integración simplificada y herramientas de optimización de costos.
¿Qué es Gemini 3.5 Flash?
Gemini 3.5 Flash se basa en la base de razonamiento de Gemini 3 Flash con “niveles de pensamiento” mejorados (mínimo, bajo, medio/predeterminado, alto) para ajustar finamente la compensación calidad-latencia-costo. Es un modelo nativamente multimodal que admite texto, imágenes, video, audio y documentos (incluidos PDFs), con una ventana de contexto de 1M tokens y hasta 65K tokens de salida. El corte de conocimientos es enero de 2025.
Diferenciadores clave respecto a los modelos Flash anteriores:
- Rendimiento de vanguardia sostenido en tareas agénticas, de programación y de largo horizonte.
- Conservación del pensamiento: mantiene automáticamente el razonamiento intermedio a lo largo de conversaciones de múltiples turnos sin cambios adicionales en la API.
- Optimizado para escala: diseñado para ejecución agéntica en paralelo, programación iterativa y flujos de trabajo empresariales de múltiples pasos.
- Sin compatibilidad con computer use (por ahora), pero con sólidas mejoras en el uso de herramientas y llamadas a funciones.
Google lo posiciona como el “modelo Flash más inteligente” para uso en producción, superando al anterior Gemini 3.1 Pro en muchos benchmarks agénticos y de programación, al tiempo que ofrece velocidad nivel Flash (a menudo >280 tokens de salida/segundo en pruebas).
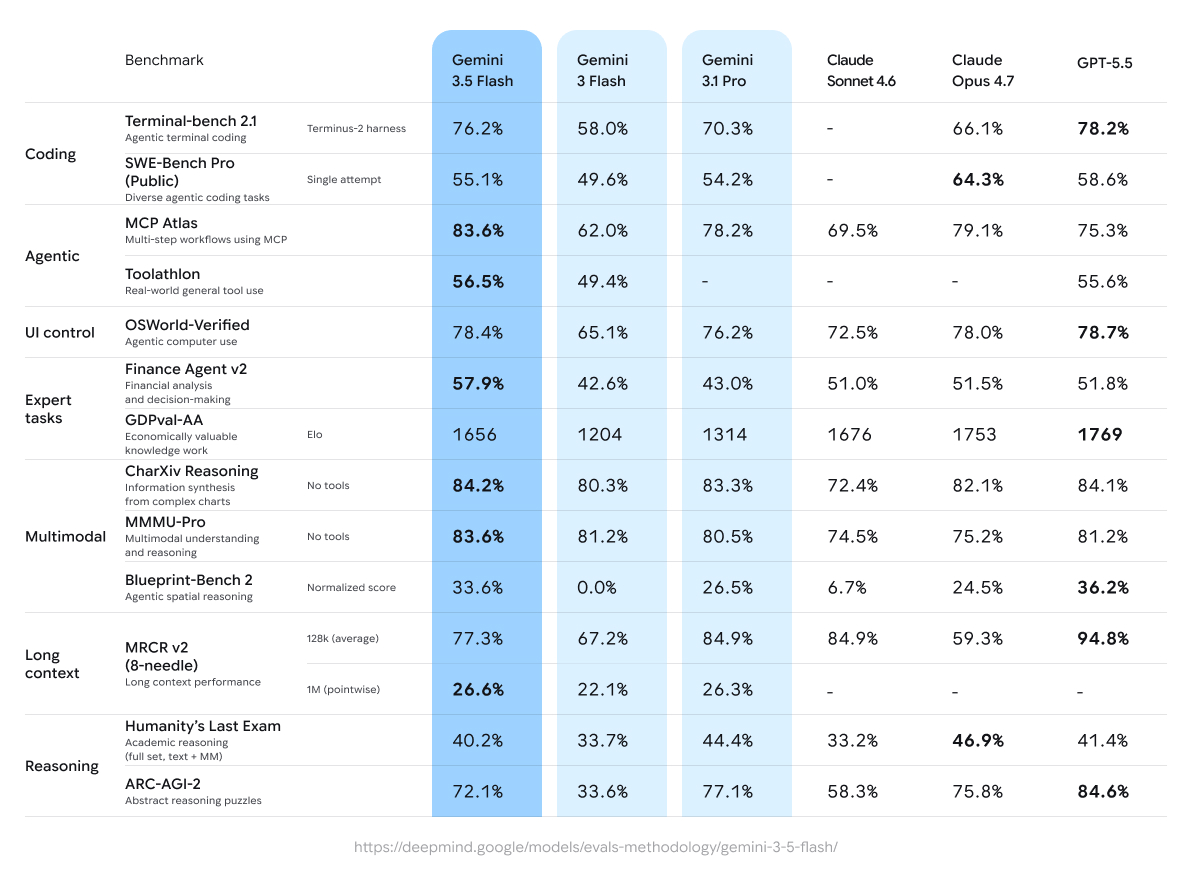
Gemini 3.5 Flash destaca en flujos agénticos y programación con inteligencia cercana a Pro, optimizada en latencia y costo, logrando puntuaciones como 76,2% en Terminal-bench 2.1 y 83,6% en tareas multi-paso de MCP Atlas.
Avance en rendimiento de benchmarks
Pruebas independientes confirman que ofrece rendimiento de nivel Pro o mejor en tareas de programación/agénticas a mayor velocidad, aunque el costo total de ejecución de benchmarks aumenta debido al mayor uso de tokens en bucles agénticos complejos y al incremento de precio 3x frente a anteriores modelos Flash.
Gemini 3.5 Flash muestra fuertes mejoras sobre sus predecesores, particularmente en dominios agénticos y de programación. Estos son resultados clave del model card de Google DeepMind y de evaluaciones independientes (a mayo de 2026):
Benchmarks seleccionados (Gemini 3.5 Flash vs. comparadores):
Programación:
- Terminal-bench 2.1 (programación agéntica en terminal): 76,2% (vs. Gemini 3 Flash 58,0%, Gemini 3.1 Pro 70,3%, GPT-5.5 78,2%)
- SWE-Bench Pro (programación agéntica pública y diversa): 55,1% (vs. 49,6% para 3 Flash, 54,2% para 3.1 Pro)
Uso agéntico de herramientas:
- MCP Atlas (flujos multi-paso): 83,6% (sólido liderazgo)
- Toolathlon (uso de herramientas en el mundo real): 56,5%
- Finance Agent v2: 57,9% (+15,3% grande sobre 3 Flash)
Multimodal:
- CharXiv (razonamiento con gráficos): 84,2%
- MMMU-Pro: 83,6% (lidera a muchos competidores)
Razonamiento y contexto largo:
- Humanity’s Last Exam: 40,2%
- ARC-AGI-2: 72,1%
- MRCR v2 (128k): 77,3%; en contexto de 1M, sólido con 26,6% punto a punto.
Artificial Analysis Intelligence Index: Gemini 3.5 Flash obtiene 55 (pensamiento alto), +9 puntos frente a Gemini 3 Flash. Lidera la frontera de Pareto de inteligencia vs. velocidad, con mejoras en tareas agénticas y reducción de alucinaciones (hasta 61% de tasa de alucinación). Logra >280 tokens de salida/segundo, pero incurre en mayor uso de tokens en bucles agénticos.
Destaca en contexto largo (sólido MRCR v2 y 1M punto a punto), liderazgo multimodal (gráficos, documentos) y rendimiento agéntico sostenido con reducción de desperdicio de tokens en algunos flujos (p. ej., 42% mejor en benchmark de ciber con 72% menos tokens).
Equilibrio entre velocidad y capacidades agénticas
Gemini 3.5 Flash brilla en la compensación velocidad-inteligencia. Logra alto rendimiento (>280 tokens/s) mientras admite comportamientos agénticos sofisticados como el despliegue de subagentes, ejecución en paralelo e iteración rápida.
El esfuerzo de pensamiento predeterminado ahora es medium, cambiado desde high en Gemini 3 Flash Preview.
Los Niveles de pensamiento permiten un control preciso:
- Medio (predeterminado): Mejor equilibrio para la mayoría de tareas complejas de código y agénticas.
- Alto: Maximiza el razonamiento profundo para los problemas más difíciles.
- Bajo/Mínimo: Latencia ultra baja para consultas más simples.
Google informa importantes ganancias de eficiencia de tokens en escenarios agénticos del mundo real (p. ej., reducción del 72% en algunos benchmarks de ciber frente a versiones anteriores), haciéndolo viable para flujos de trabajo sostenidos y de larga duración.
Compensaciones: El precio más alto que los modelos Flash anteriores conlleva mayores costos generales en escenarios agénticos intensivos en tokens (5,5x de costo del Intelligence Index vs. Gemini 3 Flash debido a precio + uso).
Capacidades mejoradas de agentes inteligentes
Gemini 3.5 Flash impulsa la “era agéntica de Gemini”. Mejoras clave incluyen:
- Bucles de ejecución agénticos en paralelo: despliega múltiples subagentes para resolver problemas complejos.
- Programación y prototipado iterativos: exploración rápida de vías de solución con uso dinámico de herramientas.
- Flujos de trabajo de largo horizonte y multi-paso: maneja procesos empresariales extendidos con conservación del pensamiento.
- Mejoras en el uso de herramientas: correspondencia estricta de respuestas de funciones, respuestas de funciones multimodales y reducción de llamadas innecesarias mediante mejores prompts y niveles de pensamiento más bajos. Sólido desempeño en OSWorld y tareas de IU.
Impulsa los nuevos agentes de información, investigación autónoma y pipelines de programación de Google. En pruebas internas, destaca al construir sistemas complejos y gestionar proyectos de investigación.
Para desarrolladores, la nueva Interactions API (beta) simplifica la gestión del historial del lado del servidor, similar a patrones avanzados en otros ecosistemas.
Recomendación de CometAPI: Usa nuestra API unificada para encadenar Gemini 3.5 Flash con modelos especializados (p. ej., Claude para revisión profunda de código o GPT para tareas creativas) en sistemas agénticos. Nuestras funciones de enrutamiento y fallback garantizan confiabilidad y ahorro de costos.
Liderazgo multimodal
Google mantiene el liderazgo en comprensión multimodal. Gemini 3.5 Flash procesa y razona de forma nativa sobre texto + imagen + video + audio + documentos. Lidera o compite estrechamente en benchmarks como CharXiv, MMMU-Pro y tareas de comprensión de video.
Casos de uso: síntesis de gráficos/datos, análisis de video, llamadas de funciones multimodales (p. ej., procesamiento de imágenes en respuestas de herramientas) y agentes de medios enriquecidos. Esto lo hace ideal para aplicaciones en comercio electrónico, creación de contenido, visualización científica y más.
Precios: ¿Cuánto cuesta Gemini 3.5 Flash?
Precios de la API de Gemini (por 1M tokens, tarifas globales aproximadas):
- Entrada (texto/imagen/video/audio): $1.50
- Salida: $9.00
- Caché de contexto: $0.15 (ahorros significativos para prompts repetidos)
Esto representa un aumento de ~3x frente a Gemini 3 Flash Preview ($0.50/$3), pero sigue siendo competitivo para el salto de capacidad. Se acerca a los precios de Gemini 3.1 Pro ($2/$12) mientras ofrece mejor velocidad para muchas cargas de trabajo.
Niveles Enterprise/Agent Platform pueden variar con descuentos por volumen y complementos. Entradas en caché y prompting eficiente (niveles de pensamiento más bajos, historiales optimizados) ayudan a controlar significativamente los costos.
Esto representa un aumento de ~3x frente a Gemini 3 Flash Preview ($0.50/$3), pero sigue siendo competitivo para el salto de capacidad. Se acerca a los precios de Gemini 3.1 Pro ($2/$12) mientras ofrece mejor velocidad para muchas cargas de trabajo.
Nivel gratuito: acceso limitado vía Google AI Studio/Gemini app; pago para producción.
Ventaja de Cometapi: Accede a la Gemini 3.5 Flash API junto a 100+ modelos con tarifas competitivas, analítica de uso y herramientas de optimización para minimizar el gasto en tokens. Nuestra plataforma a menudo ofrece mejor precio efectivo mediante enrutamiento inteligente y batching. Los precios de API suelen ser un 20% más bajos que los oficiales.
Gemini 3.5 Flash vs. GPT-5.5, Claude 4.7/4.6 y otros
Fortalezas de Gemini 3.5 Flash:
- Equilibrio velocidad + capacidad agéntica: Inferencia más rápida que la mayoría de los modelos de frontera mientras reduce la brecha de inteligencia.
- Multimodal y contexto largo: 1M de contexto nativo y liderazgo en visión.
- Costo para volumen: Más barato por token que los mejores Claude/GPT para muchas cargas, especialmente con caché.
- Ecosistema Google: Integración fluida con Search, Workspace, Cloud.
Dónde le superan los competidores:
- GPT-5.5 a menudo lidera el razonamiento puro (p. ej., ARC-AGI) y puede tener capacidades creativas/generales más fuertes.
- Claude Opus 4.7/Sonnet 4.6 destacan en codificación cuidadosa (SWE-Bench más alto en algunos casos) y escritura/métricas de seguridad matizadas.
- La eficiencia de tokens varía; los bucles agénticos pueden hacer que 3.5 Flash sea más caro en términos generales.
Comparación de alto nivel (métricas aproximadas/seleccionadas; verifica siempre los rankings más recientes):
| Benchmark / Métrica | Gemini 3.5 Flash | GPT-5.5 | Claude Opus 4.7 / Sonnet 4.6 | Gemini 3.1 Pro | Notas |
|---|---|---|---|---|---|
| Terminal-bench 2.1 (Coding) | 76.2% | 78.2% | ~66% | 70.3% | Programación agéntica |
| MCP Atlas (Agentic) | 83.6% | 75.3% | 79.1% / 69.5% | 78.2% | Flujos multi-paso |
| GDPval-AA (Agentic Knowledge) | 1656 Elo | 1769 | 1753 | 1314 | Valor económico |
| MMMU-Pro (Multimodal) | 83.6% | 81.2% | ~75% | 80.5% | Ventaja sólida de Gemini |
| Intelligence Index (AA) | 55 | Alto (varía) | Competitivo | Inferior | Pareto velocidad/intel |
| Speed (tokens/s) | >280 | Menor | Variable | Más lento | Ventaja de Flash |
| Input/Output Price ($/1M) | 1.50 / 9.00 | Mayor | Mayor (esp. Opus) | 2/12 | Frontera rentable |
| Context Window | 1M | Competitivo | Sólido | 1M+ | Todos a nivel frontera |
Resumen de compensaciones:
- Gemini 3.5 Flash gana en velocidad + multimodalidad + eficiencia agéntica a escala.
- GPT-5.5 a menudo se impone en picos de razonamiento/codificación.
- Claude 4.7 Opus destaca en codificación cuidadosa y alta confiabilidad, pero con mayor costo/latencia.
Gemini con frecuencia lidera o empata en suites multimodales y agénticas específicas, siendo más rápido y más asequible para usos de alto volumen.
Cómo acceder e integrar Gemini 3.5 Flash
Accede a él a través de:
- Gemini App / Google AI Studio
- Gemini API (
gemini-3.5-flash) - Google Cloud Vertex AI / Enterprise Agent Platform
- Agregadores de terceros para flexibilidad multi-proveedor.
Recomendación de CometAPI: Para aplicaciones de producción en Cometapi.com, integra una sola vez con una única clave API para acceder a Gemini 3.5 Flash (y 500+ modelos de OpenAI, Anthropic, xAI, etc.) con 20-40% menos precio efectivo, sin lock-in de proveedor y con fácil intercambio de modelos.
Beneficios para tus proyectos:
- Prueba Gemini 3.5 Flash frente a GPT-5.5 o Claude 4.7 al instante cambiando el nombre del modelo.
- Facturación unificada, enrutamiento con fallback y latencia optimizada.
- Ideal para apps agénticas que necesitan confiabilidad entre proveedores.
- Registro de clave API gratuito con límites de prueba generosos.
La integración de ejemplo es sencilla con los SDK oficiales o el endpoint unificado de CometAPI—perfecta para escalar la codificación
Casos de uso y buenas prácticas
- Automatización agéntica: Construye sistemas multiagente robustos para investigación, análisis de datos o soporte al cliente.
- Programación y desarrollo: Prototipado iterativo, depuración y generación de pipelines completos en Antigravity o IDE.
- Aplicaciones multimodales: Análisis de imágenes/video, comprensión de gráficos, generación de contenido.
- Flujos de trabajo empresariales: Procesos de largo horizonte con control de costos mediante caché y niveles de pensamiento.
Consejos: Usa el historial completo de conversación para la conservación del pensamiento. Empieza con medium. Optimiza los prompts para reducir llamadas a herramientas. Supervisa el uso de tokens para eficiencia de costos.
Limitaciones y consideraciones
- El aumento de precio requiere optimización cuidadosa para apps de alto volumen.
- Aún no hay computer use (monitorea novedades).
- Las evaluaciones de seguridad muestran buen desempeño con mejoras en el tono, aunque las métricas automatizadas varían.
- La reducción de alucinaciones es notable, pero valida siempre las salidas críticas.
- Aumento de precio: más alto que modelos Flash anteriores; optimiza con niveles de pensamiento y caché.
- Corte de conocimientos: enero de 2025—usa herramientas de grounding/Search para eventos actuales.
Conclusión: ¿Vale la pena Gemini 3.5 Flash?
Sí—para desarrolladores y empresas que priorizan velocidad, confiabilidad agéntica, capacidades multimodales y rendimiento escalable. Empuja la frontera de Pareto, haciendo que la IA de frontera sea más accesible para cargas de trabajo de producción.
¿Listo para construir? Dirígete a CometAPI hoy para probar Gemini 3.5 Flash junto con otros modelos líderes en un solo panel. Optimiza tu pila de IA, reduce costos y lanza más rápido.