Caractéristiques techniques de GLM-5.2
| Élément | GLM-5.2 |
|---|---|
| Fournisseur | Zhipu AI |
| Date de sortie | 13 juin 2026 |
| Type de modèle | LLM Mixture-of-Experts (MoE) à poids ouverts |
| Paramètres totaux | ~744B |
| Paramètres actifs | ~40B par jeton |
| Fenêtre de contexte | 1,000,000 jetons |
| Sortie maximale | 131,072 jetons |
| Modes de raisonnement | High, Max |
| Licence | MIT |
| Focalisation principale | Codage orienté agent, génie logiciel, raisonnement à long terme |
| Disponibilité de l’API | Plateforme Z.ai et fournisseurs compatibles |
| Poids ouverts | Oui |
GLM-5.2 est le dernier modèle phare de la famille GLM de Zhipu AI. Contrairement aux modèles généralistes de pointe, GLM-5.2 est principalement positionné comme un modèle prioritairement dédié au code et orienté agent, conçu pour l’ingénierie logicielle à l’échelle d’un dépôt, les flux de travail autonomes et le raisonnement sur de très longs contextes. Sa capacité phare est une fenêtre de contexte native d’1 million de jetons, ce qui en fait l’une des plus grandes fenêtres de contexte publiquement disponibles parmi les modèles à poids ouverts.
Principales fonctionnalités de GLM-5.2
- Fenêtre de contexte de 1M de jetons pour des dépôts entiers, des ensembles de documentation volumineux et des flux de travail multi‑session pour agents.
- Optimisation centrée sur le code axée sur le refactoring, le débogage, la génération de code et les tâches de génie logiciel.
- Prise en charge de flux de travail orientés agent pour des outils tels que Claude Code, Cline, Roo Code, OpenCode et des agents de codage similaires.
- Publication à poids ouverts sous licence MIT, permettant l’auto‑hébergement et l’affinage.
- Deux modes de raisonnement (High et Max) permettant d’arbitrer entre latence et profondeur de raisonnement.
- Grande architecture MoE d’environ 744B de paramètres totaux tout en n’activant qu’~40B par jeton pour l’efficacité.
Performances de benchmark de GLM-5.2
Zhipu n’a pas publié de résultats officiels de benchmark complets lors du lancement, ce qui rend les comparaisons directes plus incertaines que pour des modèles tels que GPT-5 ou Claude. Plusieurs rapports de l’industrie signalent l’absence de publications de benchmarks validés de manière indépendante.
| Benchmark | Score rapporté |
|---|---|
| Terminal-Bench 2.1 | 81.0 |
| SWE-Bench Pro | 62.1 |
| NL2Repo | 48.9 |
| AIME 2026 | 99.2 |
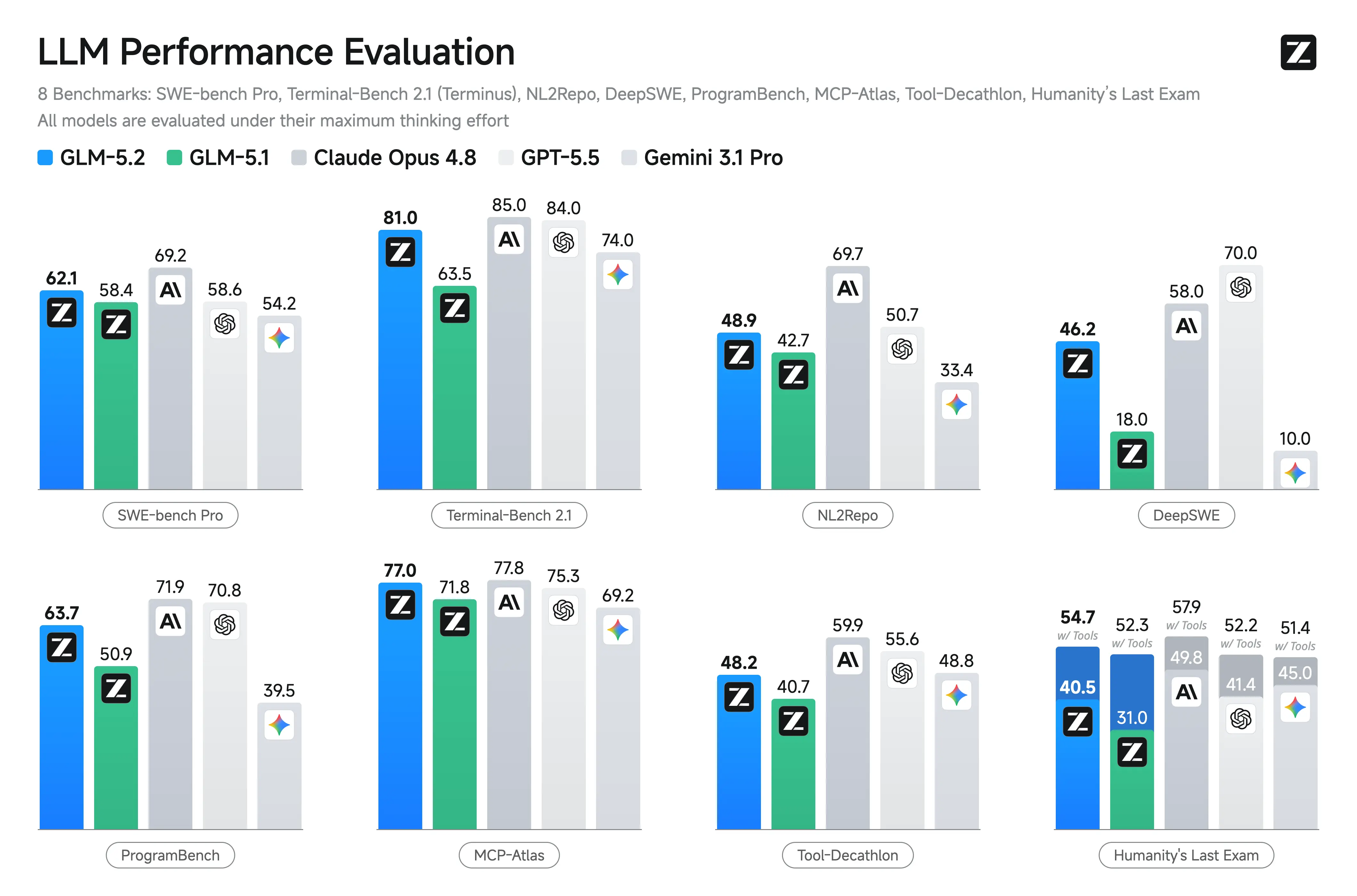
GLM-5.2 vs GLM-5.1 vs Claude Opus 4.8
| Spécification | GLM-5.2 | GLM-5.1 | Claude Opus 4.8 |
|---|---|---|---|
| Date de sortie | 2026-06-13 | 2026 | 2026 |
| Fenêtre de contexte | 1,000,000 | ~200,000 | 1,000,000 |
| Poids ouverts | Oui (MIT) | Oui | Non |
| Modes de raisonnement | High, Max | Standard | Extended Thinking |
| Paramètres totaux | 744B | 744B | Non divulgué |
| Paramètres actifs | 40B | 40B | Non divulgué |
| Données de benchmark officielles | Non publiées | Publiées au lancement | Publiées |
La principale amélioration documentée de GLM-5.2 par rapport à GLM-5.1 est l’extension à une fenêtre de contexte de 1M de jetons et l’introduction de modes de raisonnement sélectionnables High et Max. Au lancement, Z.ai n’a pas publié de résultats officiels pour SWE-Bench, LiveCodeBench, HumanEval, ou des benchmarks similaires, de sorte que les comparaisons de performances avec Claude Opus 4.8, GPT-5, DeepSeek ou les modèles Qwen restent non vérifiées.
Comparé à d’autres modèles ouverts, le principal facteur différenciant de GLM-5.2 est sa combinaison d’une très grande fenêtre de contexte, d’une spécialisation pour le code et d’une licence MIT. Son atout majeur est l’ingénierie logicielle à l’échelle d’un dépôt plutôt que les applications de conversation générales.
Pourquoi utiliser GLM-5.2 via CometAPI ?
CometAPI permet aux développeurs d’intégrer GLM-5.2 via la même interface utilisée pour des dizaines de modèles d’IA de premier plan.
Avantages :
- Authentification unifiée auprès de plusieurs fournisseurs
- Intégration d’API compatible OpenAI
- Gestion simplifiée de la facturation et de l’usage
- Expérimentation rapide avec des modèles alternatifs
- Changement facile entre des modèles de code, de raisonnement, d’image, d’audio et de vidéo
- Réduction de la dépendance fournisseur pour les systèmes de production
Que vous construisiez un IDE d’IA, un assistant d’ingénierie interne ou une plate‑forme d’automatisation d’entreprise, CometAPI minimise l’effort d’intégration tout en préservant la flexibilité.
Comment accéder à l’API GLM-5.2 sur CometAPI
Commencez avec notre produit en quelques étapes simples...
Étape 1 : Inscrivez-vous pour obtenir votre clé d’API GLM-5.2
Créez un compte sur Kie.ai et accédez au tableau de bord API pour générer votre clé d’API GLM-5.2. Cette clé authentifie toutes vos requêtes et vous donne un accès immédiat à l’ensemble des capacités de l’API GLM-5.2, y compris la fenêtre de contexte de 1M de jetons et 128k jetons de sortie.
Étape 2 : Envoyez des requêtes à l’API GLM-5.2
Utilisez votre clé d’API GLM-5.2 pour envoyer des requêtes POST vers le point de terminaison Kie.ai. Transmettez votre prompt, définissez des paramètres de modèle tels que le niveau d’effort et le nombre maximal de jetons, et l’API GLM-5.2 traite votre demande — couvrant tout, de la génération de code à l’analyse de documents en passant par l’utilisation d’outils orientés agent.
Étape 3 : Récupérez les résultats et intégrez l’API GLM-5.2
L’API GLM-5.2 fournit des réponses structurées, incluant le texte de complétion, des instructions d’appel d’outils et des métadonnées d’usage de jetons. Elle prend en charge à la fois des réponses synchrones standard et le streaming en temps réel via Server-Sent Events (SSE) lorsque stream: true est configuré. Le point de terminaison peut être facilement intégré à vos flux de travail existants en utilisant des clients HTTP standard ou des SDK compatibles openAI, en acheminant les requêtes via url(//api.cometapi.com/v1) avec votre jeton Bearer.